
Video-ChatGPT peut décrire des vidéos au fil du temps, en résolvant des tâches textuelles telles que la description des risques de sécurité dans une scène, la mise en évidence d’aspects humoristiques ou la génération de publicités correspondantes.
Alors que des entreprises comme Runway ML font progresser la conversion texte-vidéo, Video-ChatGPT va dans la direction opposée, en donnant au modèle de langage la capacité d’analyser les vidéos. Video-ChatGPT peut décrire le contenu d’une vidéo en texte, par exemple en expliquant pourquoi un clip peut être drôle en soulignant un élément inhabituel.
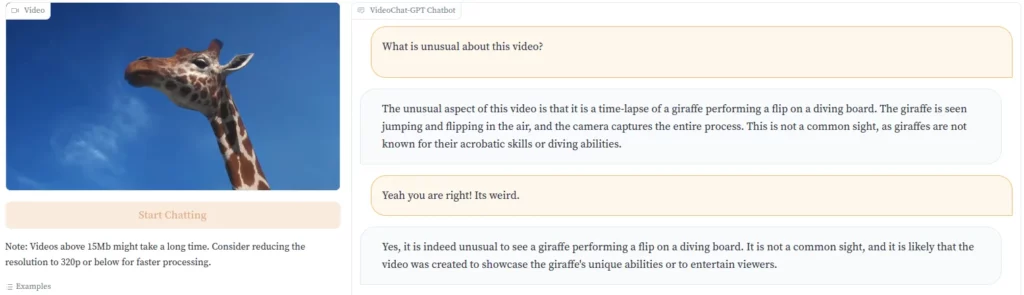
Les développeurs en font la démonstration avec la vidéo d’une girafe sautant dans l’eau à partir d’un plongeoir. « Ce n’est pas un spectacle courant, car les girafes ne sont pas connues pour leurs talents d’acrobate ou leur capacité à plonger », souligne Video-ChatGPT.
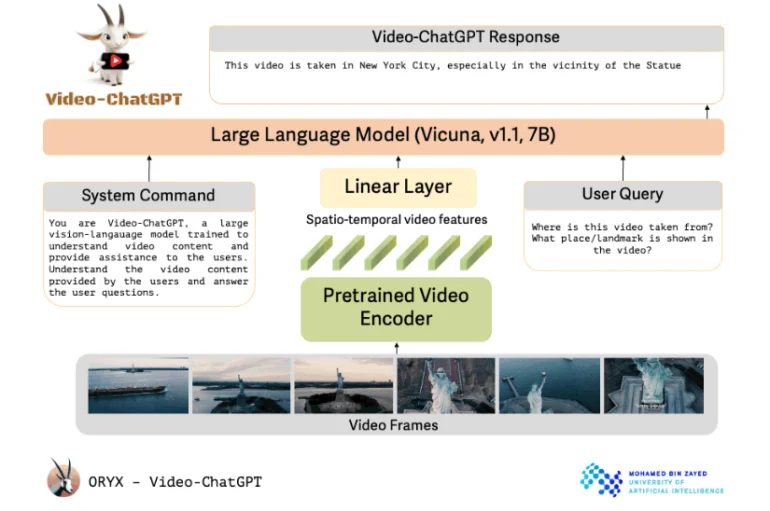
Video-ChatGPT utilise un encodeur vidéo pré-entraîné lié à un modèle de langage open source. Les chercheurs décrivent la conception de Video-ChatGPT comme étant simple et facilement extensible. Il utilise un encodeur vidéo pré-entraîné et le combine avec un modèle linguistique pré-entraîné puis affiné.
Malgré son nom, le projet de l’université Mohamed bin Zayed d’intelligence artificielle d’Abou Dhabi n’utilise pas la technologie OpenAI. Il est plutôt basé sur le modèle open source Vicuna-7B. Les chercheurs ont intégré une couche linéaire pour relier l’encodeur vidéo au modèle linguistique.
En plus de l’invite de l’utilisateur qui demande une tâche spécifique, le modèle linguistique reçoit également une commande du système qui définit son rôle et son travail général.
Les chercheurs ont utilisé une combinaison d’annotations humaines et de méthodes semi-automatiques pour générer des données de haute qualité afin d’affiner le modèle Vicuna. Ces données vont de descriptions détaillées à des tâches créatives et des entretiens, portant sur une variété de concepts différents.
Au total, l’ensemble de données contient environ 86 000 paires question-réponse de haute qualité, certaines annotées par des humains, d’autres annotées par des modèles GPT et d’autres encore annotées avec un contexte provenant de systèmes d’analyse d’images.

Le cœur de Video-ChatGPT est sa capacité à combiner la compréhension vidéo et la génération de texte. Il a été largement testé pour ses capacités de raisonnement vidéo, de créativité et de compréhension du temps et de l’espace. Voir plus d’exemples dans la vidéo ci-dessous et dans le dépôt GitHub.
Pour l’instant, Video-ChatGPT n’est disponible que sous forme de démo en ligne, mais les développeurs prévoient de publier le code et les modèles sur GitHub dans un avenir proche.
L’avenir de l’IA multimodale
À la suite des récentes avancées significatives dans le domaine de la génération de texte, des entreprises comme OpenAI et Google se tournent vers des modèles multimodaux. Bard comprend les images et peut y répondre, et GPT-4 a démontré ces capacités lors de son lancement officiel, bien qu’OpenAI ne l’ait pas encore publié.
Passer des images aux images en mouvement serait la prochaine étape logique. Google a déjà annoncé le développement d’un grand modèle d’IA multimodale avec le projet Gemini, qui sera lancé dans le courant de l’année.
