
Lorsqu’il s’agit de faire évoluer les systèmes d’IA, on parle souvent de la taille des modèles et de la quantité de données. Mais un troisième facteur est tout aussi important : la qualité des données.
Des chercheurs de Microsoft ont étudié la capacité d’un petit modèle de langage à effectuer des tâches de programmation lorsqu’il est formé avec des données peu nombreuses mais de haute qualité, en utilisant le modèle de langage phi-1 basé sur la transformation.
Les chercheurs affirment n’avoir utilisé que des données de qualité « comparable à celle d’un livre de texte » pour entraîner l’IA. À partir des ensembles de données The Stack et StackOverflow, ils ont filtré six milliards de jetons de formation de haute qualité en code à l’aide d’un classificateur basé sur GPT-4. L’équipe a généré un autre milliard de jetons en utilisant GPT 3.5.
L’entraînement a duré environ quatre jours avec huit cartes graphiques Nvidia A100.
Phi-1 surpasse des modèles beaucoup plus grands lors des tests
Le plus grand petit modèle, phi-1 1.3B, qui a été affiné avec des tâches de codage, surpasse des modèles 10 fois plus grands et utilisant 100 fois plus de données dans les tests de référence HumanEval et MBPP. Seul GPT-4 surpasse phi-1 dans les scénarios de test.
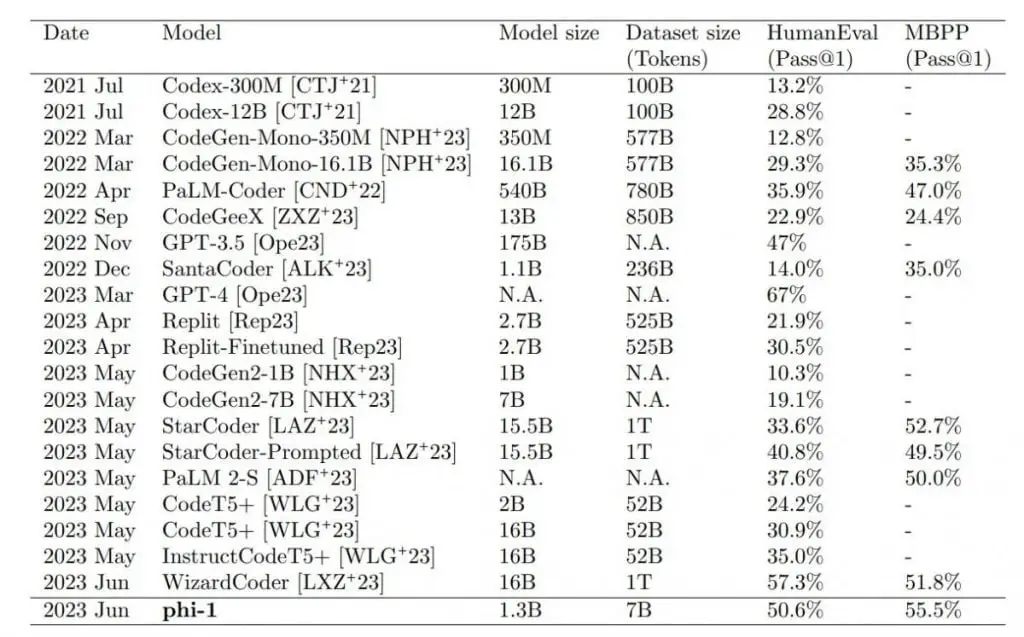
Les résultats ont dépassé les attentes des chercheurs. L’équipe attribue directement la qualité des données, comme le suggère le titre de l’article : « Les manuels sont tout ce dont vous avez besoin », en référence à la recherche de découverte Transformer de Google (« L’attention est tout ce dont vous avez besoin »).
Cependant, Phi-1 présente également certaines limites par rapport à des modèles plus importants. Son expertise en programmation Python limite sa polyvalence, il ne dispose pas des connaissances spécifiques au domaine des grands LLM, telles que la programmation avec des API spécifiques, et la nature structurée de Phi-1 le rend moins robuste aux variations de style ou aux erreurs de saisie dans les messages-guides.
D’autres améliorations de la performance du modèle seraient possibles si les données synthétiques étaient générées à l’aide de GPT-4 au lieu de GPT-3.5, qui a un taux d’erreur élevé. Toutefois, l’équipe souligne que malgré les nombreuses erreurs, le modèle a été capable d’apprendre efficacement et de générer un code correct. Cela suggère qu’il est possible d’extraire des modèles ou des représentations utiles à partir de données erronées.
Modèles experts de qualité des données
Les chercheurs affirment que leurs travaux confirment que des données de haute qualité sont essentielles pour l’apprentissage de l’IA. Ils soulignent toutefois que la collecte de données de haute qualité est un défi. En particulier, les données doivent être équilibrées, diversifiées et éviter les répétitions. En particulier pour les deux derniers points, il y a un manque de méthodes de mesure. Phi-1 sera bientôt disponible en open source sur Hugging Face.
Tout comme un manuel complet et bien conçu peut fournir à un étudiant les connaissances nécessaires pour maîtriser un nouveau sujet, notre travail démontre l’impact remarquable de données de haute qualité dans l’amélioration de la compétence d’un modèle de langage dans les tâches de génération de code.
Extrait de l’article
Andrei Karpathy, ancien directeur de l’IA chez Tesla et aujourd’hui de retour à l’OpenAI, partage ce sentiment, déclarant qu’il espère voir davantage de « petits modèles experts puissants » à l’avenir. Ces modèles d’IA donneraient la priorité à la qualité et à la diversité des données plutôt qu’à leur quantité, et seraient formés sur des données synthétiques complémentaires.
