
Stability AI, la société spécialisée dans le diffing stable, lance deux nouveaux modèles linguistiques de grande taille en collaboration avec CarperAI. L’un d’entre eux est basé sur le modèle Llama v2 de Meta, ce qui améliore ses performances et démontre la rapidité du développement open source.
Les deux modèles de FreeWilly sont basés sur les modèles Llama de Meta, FreeWilly2 utilisant déjà le dernier modèle Llama-2 avec 70 milliards de paramètres. L’équipe de FreeWilly s’efforce de procéder à un « réglage minutieux » à l’aide d’un nouvel ensemble de données synthétiques généré avec des « instructions de haute qualité ».
Du grand au petit
L’équipe a utilisé la « méthode Orca » de Microsoft, qui consiste à enseigner à un petit modèle le processus de raisonnement étape par étape d’un grand modèle de langage, plutôt que d’imiter simplement son style de sortie. Pour ce faire, les chercheurs de Microsoft ont créé un ensemble de données d’entraînement avec le grand modèle, en l’occurrence GPT-4, contenant ses processus de raisonnement étape par étape.
L’objectif de ce type d’expériences est de développer de petits modèles d’intelligence artificielle dont les performances sont similaires à celles des grands modèles – une sorte de principe « enseignant-élève ». Orca surpasse des modèles de taille similaire dans certains tests, mais ne parvient pas à égaler les modèles originaux.
L’équipe de FreeWilly affirme avoir créé un ensemble de 600 000 points de données avec les messages-guides et les modèles linguistiques choisis, soit environ 10 fois moins que l’ensemble de données utilisé par l’équipe d’Orca. Selon l’équipe, cela réduit considérablement la quantité d’entraînement nécessaire et améliore l’impact environnemental du modèle.
VanillaLlama v2 a déjà obtenu de meilleurs résultats que la version précédente
Sur des benchmarks courants, le modèle FreeWilly ainsi formé obtient des résultats équivalents à ChatGPT sur certaines tâches logiques, le modèle FreeWilly 2 basé sur Llama 2 étant nettement plus performant que FreeWilly 1.
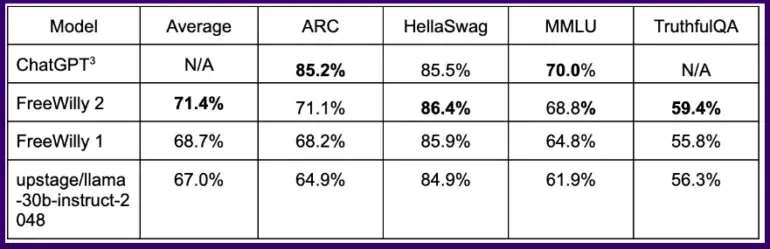
En moyenne, sur l’ensemble des benchmarks, FreeWilly 2 devance Llama v2 d’environ quatre points, une première indication que le nouveau modèle par défaut de Meta peut être amélioré et que la communauté open source peut aider à l’exploiter.
Dans l’ensemble, FreeWilly 2 est actuellement en tête de la liste des modèles open source les plus performants, le modèle original Llama 2 conservant une légère avance dans l’important test de compréhension du langage général MMLU.
FreeWilly1 et FreeWilly2 établissent une nouvelle norme dans le domaine des grands modèles de langage en libre accès. Ces deux modèles font progresser la recherche de manière significative, améliorent la compréhension du langage naturel et permettent d’accomplir des tâches complexes.
Carper AI, Stability AI
Les modèles FreeWilly sont développés à des fins de recherche uniquement et publiés sous une licence non commerciale. Ils peuvent être téléchargés à partir de HuggingFace ici.
