
L’Institut Allen pour l’Intelligence Artificielle (AI2) a présenté Dolma, un ensemble de données open source comprenant trois billion de jetons, issus d’une vaste gamme de contenus du web, de publications scientifiques, de code et de livres. C’est l’ensemble de données open source le plus vaste de ce type disponible publiquement jusqu’à présent.
Dolma est la base du Modèle de Langage Ouvert (OLMo), actuellement en développement à l’AI2 et prévu pour être lancé début 2024. Dans le but de développer le « meilleur modèle de langage ouvert », l’ensemble de données étendu Dolma (Données pour alimenter l’OLMo) a été créé.
Dolma est actuellement le plus grand ensemble de données open source et est disponible pour les développeurs et les chercheurs via la plateforme Hugging Face. Vous y trouverez également les outils que les chercheurs ont utilisés pour le créer, garantissant la reproductibilité des résultats.
Le Dolma est principalement composé de données en anglais
Pour créer le Dolma, des données provenant de diverses sources ont été converties en documents texte propres.
Dans la première version, le Dolma est principalement limité aux textes en anglais. Un modèle de reconnaissance de la langue a été utilisé pour filtrer les données. Pour compenser tout biais en faveur des dialectes minoritaires, l’équipe a inclus tous les textes que le modèle a classés comme anglais avec une confiance de 50 pour cent. Les versions futures incluront d’autres langues.

Dans les étapes suivantes, les chercheurs ont nettoyé le jeu de données en supprimant les doublons, le contenu de faible qualité ou les informations sensibles, tout en améliorant la qualité des exemples de code.
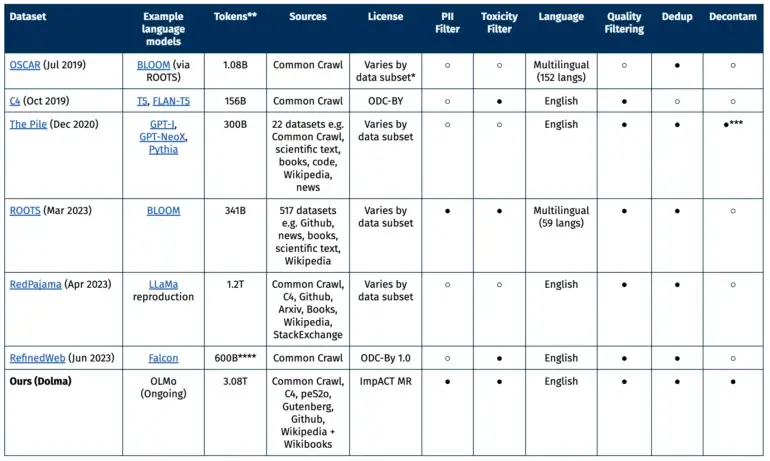
Comparaison avec d’autres ensembles de données ouverts
La majeure partie des données provient du projet à but non lucratif Common Crawl, qui se concentre sur les données du web. De plus, il y a d’autres pages web de la collection C4, des textes académiques de peS20, des extraits de code de The Stack, des livres du Project Gutenberg et la version anglaise de Wikipedia.
L’ensemble de données idéal, selon l’AI21, doit répondre à plusieurs critères : ouverture, représentativité, taille et reproductibilité. Il doit également minimiser les risques, en particulier ceux qui pourraient affecter les individus.
Des études antérieures ont montré que non seulement le nombre de paramètres dans le modèle, mais aussi la quantité de données d’entraînement dans un modèle de langage joue un rôle central dans les performances.
Disponibilité de Dolma et la question de l’open source
L’ensemble de données est publié sous la licence ImpACT d’AI2 en tant qu’artefact à risque modéré. Les chercheurs doivent respecter certaines exigences, telles que fournir leurs coordonnées et accepter l’utilisation prévue de Dolma. De plus, un mécanisme a été mis en place pour permettre la suppression des données personnelles sur demande.
Après le lancement de Dolma en tant qu’ensemble de données open source, certains critiques ont soutenu qu’il y avait trop de clauses dans la licence. Selon eux, bien que Dolma soit ouvert, il ne pourrait pas être considéré comme open source. La désignation par Meta du modèle LLaMA-2 comme open source a également récemment été critiquée par l’Open Source Initiative.

