

O Instituto Allen para a Inteligência Artificial (AI2) apresentou o Dolma, um conjunto de dados de código aberto com três trilhões de tokens, provenientes de uma ampla variedade de conteúdo da web, publicações científicas, código e livros. É o conjunto de dados de código aberto mais extenso desse tipo disponível publicamente até o momento.
O Dolma é a base do Modelo de Linguagem Aberta (OLMo), atualmente em desenvolvimento na AI2 e programado para ser lançado no início de 2024. Com o objetivo de desenvolver o “melhor modelo de linguagem aberta”, foi criado o extenso conjunto de dados Dolma (Dados para alimentar o OLMo).
O Dolma é atualmente o maior conjunto de dados de código aberto e está disponível para desenvolvedores e pesquisadores por meio da plataforma Hugging Face. Lá, você também encontrará as ferramentas que os pesquisadores usaram para criá-lo, garantindo a reprodutibilidade dos resultados.
O Dolma consiste principalmente em dados em inglês
Para criar o Dolma, dados de várias fontes foram convertidos em documentos de texto limpos.
Na primeira versão, o Dolma é em grande parte limitado a textos em inglês. Um modelo de reconhecimento de idioma foi utilizado para filtrar os dados. Para compensar qualquer viés em direção a dialetos minoritários, a equipe incluiu todos os textos que o modelo classificou como inglês com 50 por cento de confiança. Versões futuras incluirão outros idiomas.

Nas etapas subsequentes, os pesquisadores limparam o conjunto de dados de duplicatas, conteúdo de baixa qualidade ou informações sensíveis, além de melhorarem a qualidade dos exemplos de código.
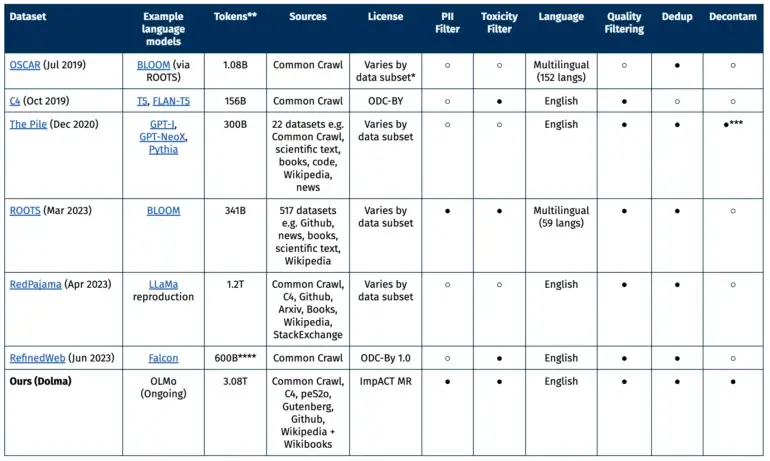
Comparação com outros conjuntos de dados abertos
Grande parte dos dados provém do projeto sem fins lucrativos Common Crawl, que se concentra em dados da web. Além disso, há outras páginas da web da coleção C4, textos acadêmicos de peS20, trechos de código de The Stack, livros do Project Gutenberg e a Wikipédia em inglês.
O conjunto de dados ideal, aos olhos da AI21, deve atender a vários critérios: abertura, representatividade, tamanho e reprodutibilidade. Ele também deve minimizar os riscos, especialmente aqueles que poderiam afetar indivíduos.
Estudos anteriores mostraram que não apenas o número de parâmetros no modelo, mas também a quantidade de material de treinamento em um modelo de linguagem desempenha um papel central no desempenho.
Disponibilidade do Dolma e a questão do código aberto
O conjunto de dados é lançado sob a licença ImpACT da AI2 como um artefato de médio risco. Os pesquisadores devem atender a certos requisitos, como fornecer suas informações de contato e concordar com o uso pretendido do Dolma. Além disso, foi estabelecido um mecanismo para permitir a remoção de dados pessoais mediante solicitação.
Após o lançamento do Dolma como um conjunto de dados de código aberto, alguns críticos argumentaram que havia muitas cláusulas na licença. A seu ver, o Dolma é aberto, mas não poderia ser considerado de código aberto. A designação da Meta do modelo LLaMA-2 como código aberto também foi recentemente criticada pela Iniciativa de Código Aberto.

