
I-JEPA muestra cómo el jefe de IA de Meta, Yann LeCun, visualiza el futuro de la IA, y todo comienza nuevamente con los benchmarks de ImageNet.
Hace menos de un año, el pionero de la IA y jefe de IA de Meta, Yann LeCun, reveló una nueva arquitectura de IA diseñada para superar las limitaciones de los sistemas actuales, como alucinaciones y debilidades lógicas. Con I-JEPA, un equipo de Meta AI (FAIR), la Universidad McGill, Mila, el Instituto de IA de Quebec y la Universidad de Nueva York presenta uno de los primeros modelos de IA que sigue la «Arquitectura de Predicción de Incorporación Conjunta». Los investigadores incluyen al primer autor Mahmoud Assran y a Yann LeCun.
El modelo basado en Vision Transformer logra un alto rendimiento en benchmarks que van desde la clasificación lineal hasta el conteo de objetos y la predicción de profundidad, y es más eficiente en términos de cómputo que otros modelos de visión computacional ampliamente utilizados.
El I-JEPA aprende con representaciones abstractas
El I-JEPA se entrena de manera auto-supervisada para predecir detalles de las partes no visibles de una imagen. Esto se logra simplemente enmascarando grandes bloques de estas imágenes cuyo contenido el I-JEPA debe predecir. Otros métodos a menudo dependen de conjuntos de datos de entrenamiento mucho más extensos.
Para garantizar que el I-JEPA aprenda representaciones semánticas de nivel superior de los objetos y no opere a nivel de píxel o token, Meta coloca una especie de filtro entre la predicción y la imagen original.
Además de un codificador de contexto, que procesa las partes visibles de una imagen, y un predictor, que utiliza la salida del codificador de contexto para predecir la representación de un bloque objetivo en la imagen, el I-JEPA consta de un codificador objetivo. Este codificador objetivo se encuentra entre la imagen completa, que sirve como señal de entrenamiento, y el predictor.
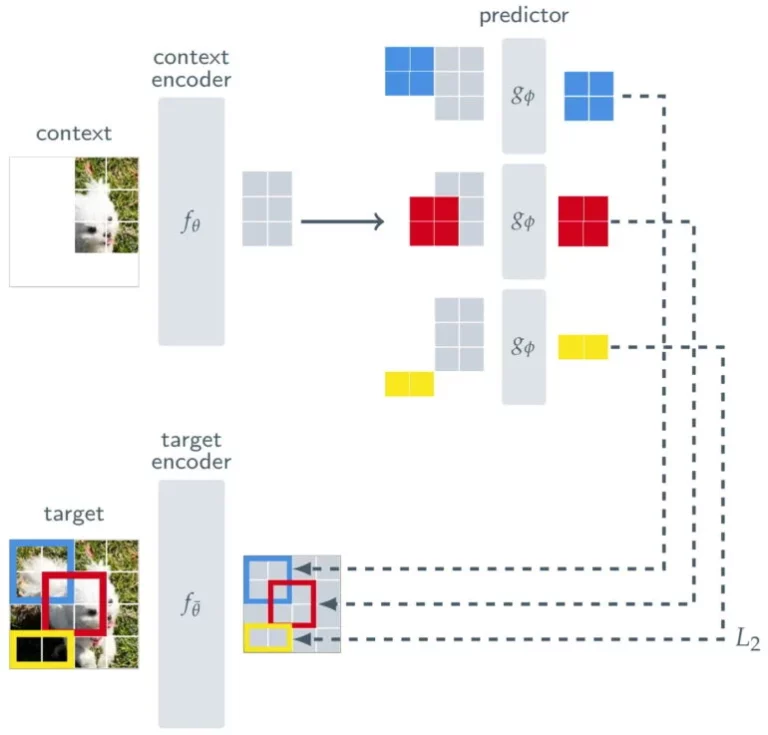
Así, la predicción del I-JEPA no se realiza a nivel de píxel, sino a nivel de representaciones abstractas a medida que la imagen es procesada por el codificador objetivo. Con esto, el modelo utiliza «metas de predicción abstractas en las que los detalles innecesarios a nivel de píxel son potencialmente eliminados», afirma Meta, lo que lleva al modelo a aprender características más semánticas.
I-JEPA destaca en ImageNet
Las representaciones aprendidas luego pueden ser reutilizadas para diferentes tareas, lo que permite que el I-JEPA logre excelentes resultados en ImageNet con solo 12 ejemplos etiquetados por clase. El modelo con 632 millones de parámetros se entrenó en 16 GPUs Nvidia A100 en menos de 72 horas. Otros métodos generalmente requieren de dos a diez veces más horas de GPU y obtienen tasas de error peores cuando se entrenan con la misma cantidad de datos.
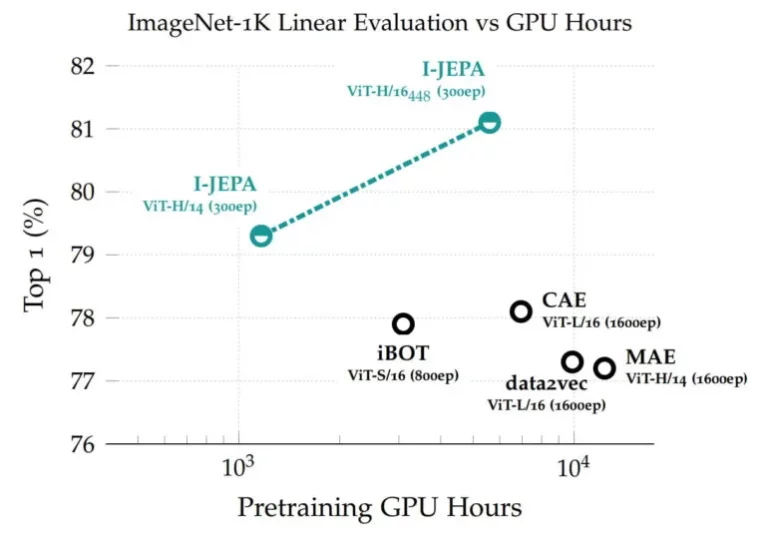
El I-JEPA logra altas puntuaciones en ImageNet con una carga computacional relativamente baja. | Imagen: Meta
En un experimento, el equipo utiliza un modelo de IA generativo para visualizar las representaciones del I-JEPA y muestra que el modelo aprende según lo esperado.

Durante el entrenamiento, el predictor debe predecir el contenido en el recuadro azul. Los resultados visibles aquí fueron producidos utilizando un modelo de IA generativo conectado al módulo de Predictor. | Imagen: Meta
El I-JEPA es una prueba de concepto para la arquitectura propuesta, cuyo elemento central es una especie de filtro entre la predicción y los datos de entrenamiento, lo que a su vez permite representaciones abstractas. Según LeCun, estas abstracciones podrían permitir que los modelos de IA se asemejen más al aprendizaje humano, realicen inferencias lógicas y resuelvan el problema de la alucinación en la IA generativa.
El JEPA podría viabilizar modelos del mundo
El objetivo general de los modelos JEPA no es solo reconocer objetos o generar texto: LeCun desea viabilizar modelos comprehensivos del mundo que funcionen como parte de una inteligencia artificial autónoma. Para lograr esto, propone apilar los JEPA de manera jerárquica para permitir predicciones a un nivel más alto de abstracción basadas en predicciones de módulos inferiores.
«Sería especialmente interesante avanzar en los JEPA para aprender modelos más generales del mundo a partir de modalidades más ricas, por ejemplo, permitiendo realizar predicciones espaciales y temporales a largo plazo sobre eventos futuros en un video a partir de un contexto corto y condicionando esas predicciones a estímulos de audio o texto», afirma Meta.
Por lo tanto, el JEPA se aplicará a otros dominios, como pares de imagen-texto o datos de video. «Este es un paso importante para aplicar y escalar métodos de auto-supervisión para aprender un modelo general del mundo», afirma el blog.
LeCun brinda más información sobre la motivación, desarrollo y funcionamiento del JEPA en una conferencia en el Instituto de IA Experencial de la Universidad Northeastern.
Más información está disponible en el meta-blog de I-JEPA. El modelo y el código están disponibles en GitHub.
Con contenido de The Decoder.
