
Sistema de IA StreamDiT gera vídeos em livestream a partir de descrições textuais
Um novo sistema de IA chamado StreamDiT pode gerar vídeos em livestream a partir de descrições textuais, abrindo novas possibilidades para jogos e mídia interativa.
Desenvolvido por pesquisadores da Meta e da Universidade da Califórnia, Berkeley, o StreamDiT cria vídeos em tempo real a 16 quadros por segundo utilizando uma única GPU de alta performance. O modelo, com 4 bilhões de parâmetros, gera vídeos com resolução 512p. Diferentemente dos métodos anteriores, que produzem clipes de vídeo completos antes da reprodução, o StreamDiT gera o fluxo ao vivo, quadro a quadro.
A equipe apresentou diversos casos de uso. O sistema é capaz de gerar vídeos com duração de um minuto instantaneamente, responder a comandos interativos e até editar vídeos já existentes em tempo real. Em uma demonstração, um porco em um vídeo foi transformado em um gato, mantendo o mesmo fundo.

Utilizando um comando de texto, o StreamDiT transforma um porco correndo no vídeo de entrada em um gato no fluxo de saída, demonstrando a edição de vídeo baseada em prompt em tempo real.
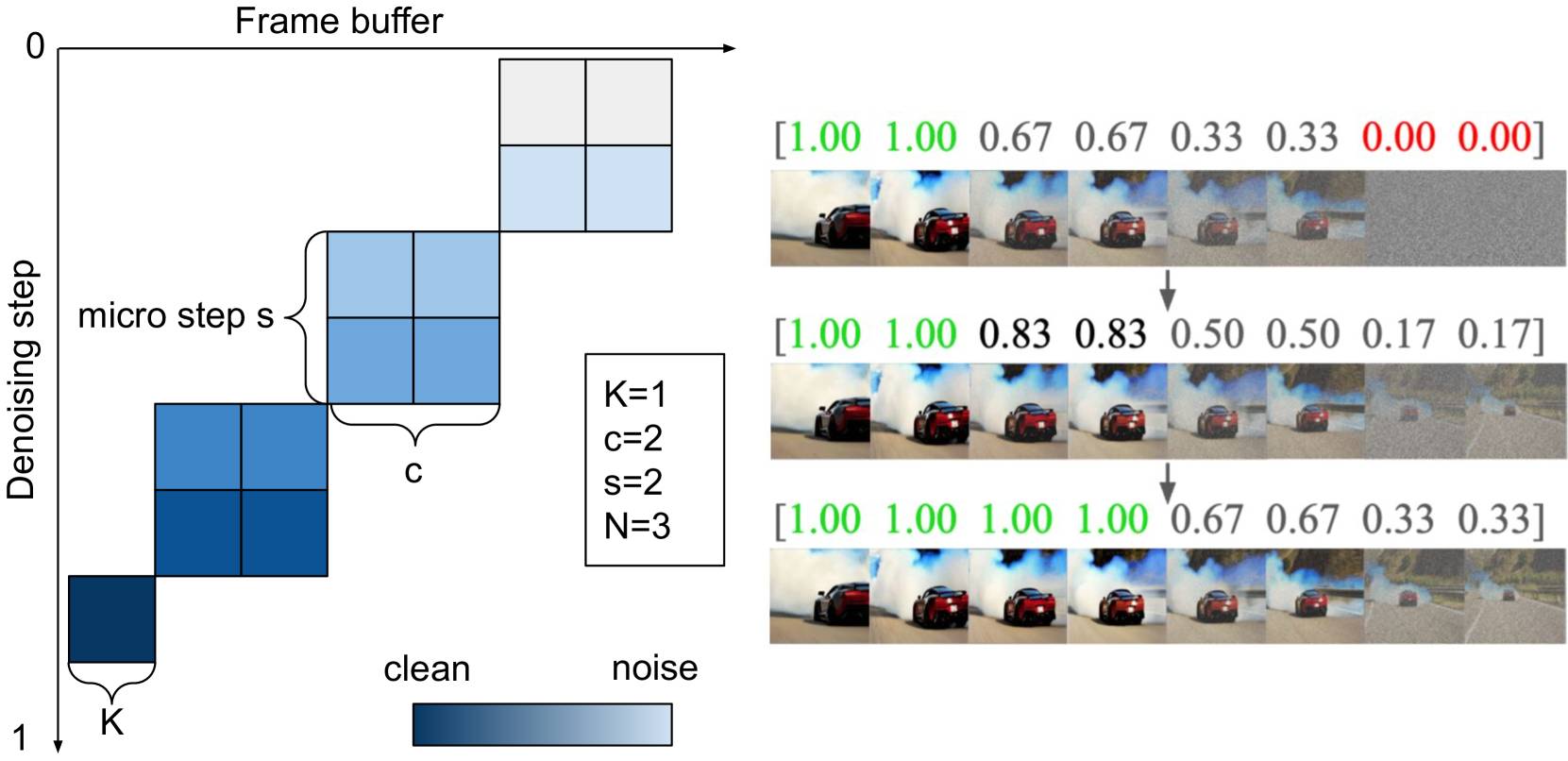
O sistema se baseia em uma arquitetura personalizada desenvolvida para alta velocidade. O StreamDiT utiliza um buffer móvel para processar múltiplos quadros simultaneamente, trabalhando no próximo quadro enquanto exibe o anterior. Os novos quadros começam com um nível elevado de ruído, sendo gradualmente refinados até estarem prontos para exibição. Segundo o estudo, o sistema leva cerca de meio segundo para gerar dois quadros, produzindo oito imagens finais após o processamento.
Treinamento para versatilidade
Para aprimorar sua versatilidade, o processo de treinamento foi desenvolvido para utilizar diversas abordagens na criação de vídeos, em vez de se concentrar em um único método. O modelo foi treinado com 3.000 vídeos de alta qualidade e um conjunto de dados maior composto por 2,6 milhões de vídeos, utilizando 128 GPUs Nvidia H100. Os pesquisadores descobriram que a combinação de tamanhos de segmentos, variando de 1 a 16 quadros, produziu os melhores resultados.
Para atingir a performance em tempo real, a equipe introduziu uma técnica de aceleração que reduziu o número de etapas de cálculo necessárias de 128 para apenas 8, com impacto mínimo na qualidade da imagem. A arquitetura também foi otimizada para maior eficiência: em vez de permitir que cada elemento da imagem interaja com todos os outros, a troca de informações ocorre apenas entre regiões locais.
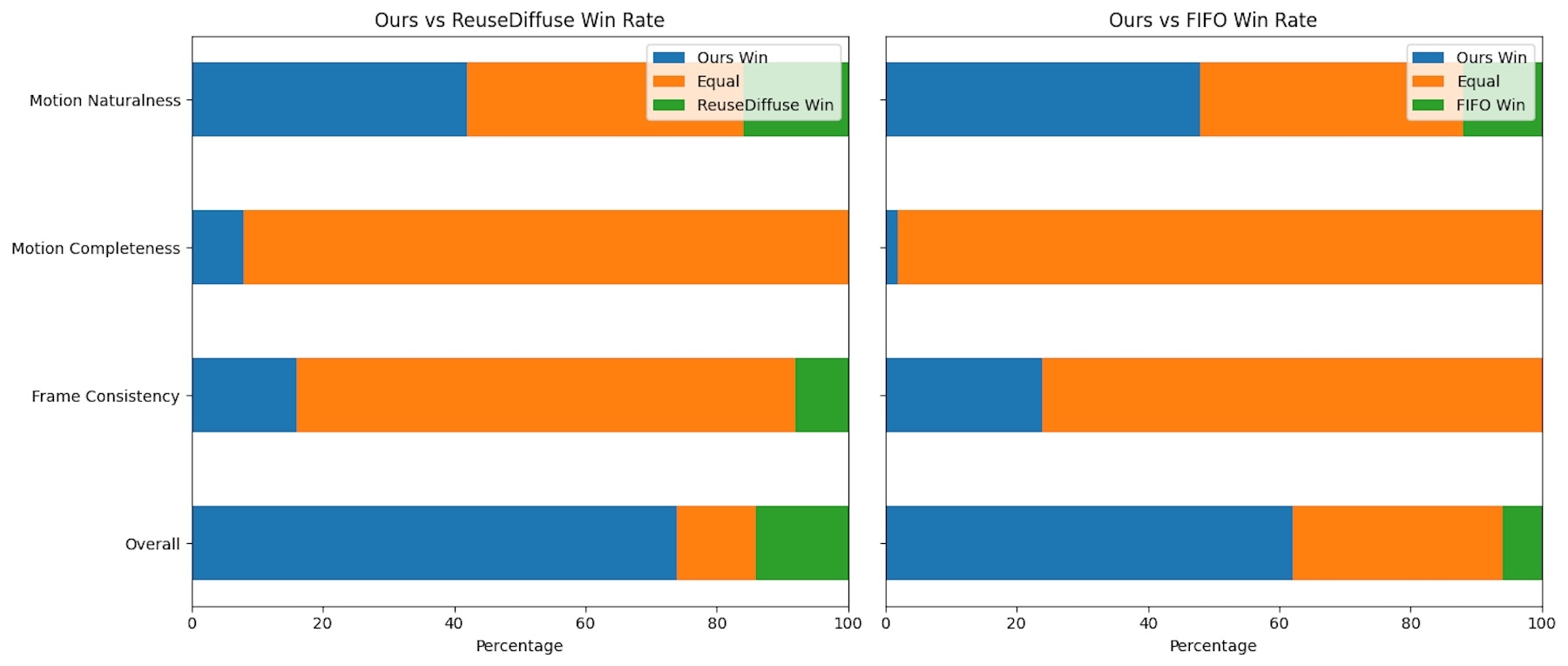
Em comparações diretas, o StreamDiT superou métodos existentes como o ReuseDiffuse e o FIFO diffusion, especialmente em vídeos com grande movimento. Enquanto outros modelos tendiam a criar cenas estáticas, o StreamDiT produziu movimentos mais dinâmicos e naturais.
Observadores humanos avaliaram o desempenho do sistema quanto à fluidez do movimento, completude da animação, consistência entre os quadros e qualidade geral. Em todas as categorias, o StreamDiT se destacou em vídeos de oito segundos com resolução 512p.
Modelo maior, melhor qualidade — mas mais lento
A equipe também experimentou um modelo significativamente maior, com 30 bilhões de parâmetros, que proporcionou uma qualidade de vídeo ainda superior, embora sua velocidade não fosse suficiente para uso em tempo real. Esses resultados indicam que a abordagem pode ser escalada para sistemas mais robustos.
Apesar dos avanços, algumas limitações permanecem, como a capacidade restrita do StreamDiT de “lembrar” partes anteriores do vídeo e transições visíveis ocasionais entre seções. Os pesquisadores afirmam que estão trabalhando em soluções para essas questões.
Outras empresas também estão explorando a geração de vídeos com IA em tempo real. Por exemplo, a Odyssey apresentou recentemente um modelo autoregressivo que adapta os quadros do vídeo, quadro a quadro, em resposta às interações do usuário, proporcionando experiências interativas mais acessíveis.
