
Os resultados mostraram que, com os devidos incentivos, o GPT-4 alcançou um desempenho impecável nos testes de Teoria da Mente. Uma teoria filosófica pode explicar como um grande modelo de linguagem aprende a “ler a mente”.
Uma equipe da Universidade Johns Hopkins estudou o desempenho do GPT-4 e de três variantes do GPT-3.5 (Davinci-2, Davinci-3, GPT-3.5-Turbo) nos chamados testes de falsa alívio, dos quais o mais famoso é provavelmente o “Teste de Sally & Anne”.
Nesse tipo de teste, a psicologia do desenvolvimento ou a biologia comportamental examinam a capacidade dos seres humanos ou dos animais de atribuir crenças falsas a outros seres vivos.
Um exemplo de teste de crença falsa:
Cenário: Larry escolheu um tópico de discussão para seu trabalho de classe que deve ser entregue na sexta-feira. As notícias de quinta-feira disseram que o debate foi resolvido, mas Larry não leu.
Pergunta: Quando Larry escreve seu ensaio, ele acha que o debate foi resolvido?
Responder a essas perguntas requer a capacidade de acompanhar os estados mentais dos atores em um cenário, como seu conhecimento e objetivos. As crianças geralmente adquirem essa habilidade por volta dos quatro anos e podem atribuir desejos e crenças a si mesmas e aos outros. Quando eles passam nesses testes, os cientistas geralmente lhes atribuem uma “teoria da mente” (ToM) que lhes dá essas habilidades de “leitura de mente”.
Nos testes, a equipe foi capaz de mostrar que, em quase todos os casos, a precisão dos modelos OpenAI poderia ser melhorada para mais de 80% dando-lhes alguns exemplos e instruindo-os a pensar passo a passo. A exceção foi o modelo Davinci-2, que foi o único não treinado por aprendizado por reforço com feedback humano (RLHF).
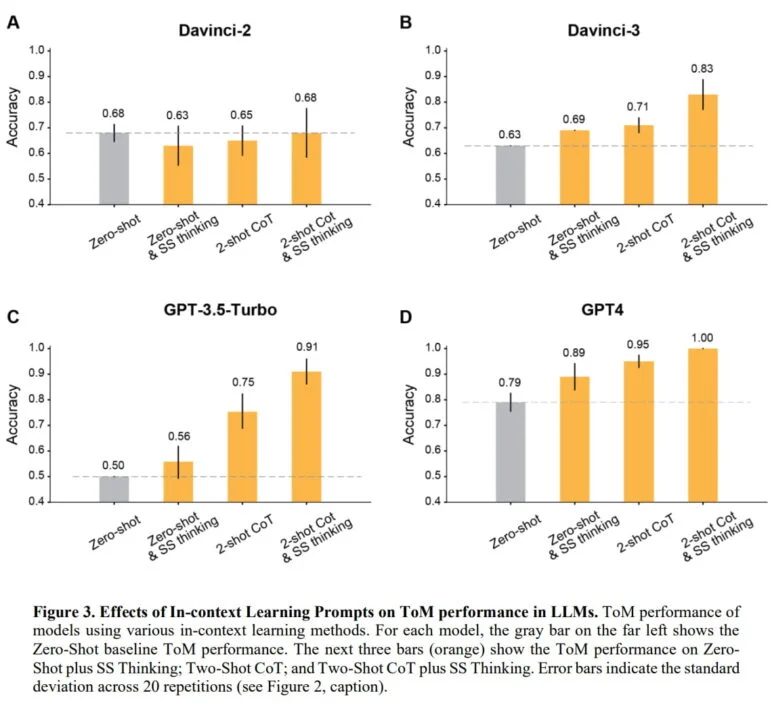
O GPT-4 teve o melhor desempenho: sem exemplos, o modelo alcançou uma precisão de ToM de quase 80%; com exemplos e instruções de raciocínio, ele alcançou uma precisão de 100%. Em testes comparativos em que as pessoas precisavam responder sob pressão de tempo, a precisão humana foi de cerca de 87%.
Teoria da mente por meio do aprendizado por reforço com feedback humano?
A habilidade demonstrada pelos modelos GPT de lidar confiavelmente com esses cenários de ToM ajuda os modelos a lidar com os seres humanos em geral, e em contextos sociais em particular, onde eles poderiam se beneficiar de levar em conta os estados mentais dos atores humanos envolvidos, disse a equipe. Além disso, esses cenários frequentemente envolvem raciocínio inferencial, onde algumas informações só podem ser inferidas a partir do contexto e não são diretamente observáveis. “Assim, avaliar e melhorar a proficiência desses modelos em tarefas de ToM poderia oferecer insights valiosos sobre seu potencial para uma ampla gama de tarefas que requerem raciocínio inferencial”, afirma o artigo.
E de fato, em testes com cenários não-ToM em que a informação está faltando, a equipe pode mostrar que a precisão das inferências dos modelos RLHF pode ser melhorada usando exemplos e instruindo-os a pensar passo a passo, com o GPT-4 alcançando uma precisão de 100%. Curiosamente, o modelo Davinci-2 se sai bem aqui por natureza, atingindo 98% e na verdade perdendo precisão com o aprendizado em contexto, enquanto também apresenta o pior desempenho em cenários de ToM. A equipe teoriza que as capacidades de ToM são fortemente determinadas pelo RLHF.
O GPT-4 tem uma teoria da mente?
As amostras mostram que o GPT-4 tem uma teoria da mente? Como a questão do que subjaz à capacidade das crianças pequenas de passar em testes de crença falsa também é amplamente debatida, uma resposta simples provavelmente não é possível. No entanto, as teorias discutidas lá, como a Theory-Theory ou a Simulation Theory, geralmente concordam pelo menos que nossa ToM é uma herança biológica – o que pode ser descartado para o GPT-4.
Entra em cena uma teoria filosófica pouco conhecida que pode explicar por que os modelos de linguagem grandes com RLHF passam em testes de crença falsa: Em 2008, o filósofo americano Daniel D. Hutto publicou “Narrativas Psicológicas Populares: A Base Sociocultural da Compreensão de Razões”, no qual argumenta que a compreensão popular da teoria da mente perde seu núcleo. Em sua visão, nossa ToM é principalmente caracterizada por nossa capacidade e motivação de usar nossa compreensão de crenças falsas em contextos explicativos maiores.
De acordo com Hutto, a teoria da mente é mais do que a habilidade de inferir falsas crenças e está intimamente relacionada ao conceito ambíguo de “psicologia popular“. De acordo com sua Hipótese de Prática Narrativa (NPH), as crianças adquirem sua teoria da mente ao serem expostas e participarem de uma forma especial de prática narrativa que explica e prevê as ações das pessoas em termos de razões.
“A afirmação central da NPH é que encontros diretos com histórias sobre pessoas que agem por razões – aquelas fornecidas em contextos interativos por cuidadores responsivos – é a rota normal através da qual as crianças se familiarizam tanto com (i) a estrutura básica da psicologia popular, e (ii) as possibilidades governadas por normas para aplicá-la na prática, aprendendo como e quando usá-la”, diz Hutto.
Teoria da mente como prática de narrativas de psicologia popular
Assim, de acordo com Hutto, passar em testes de falsas crenças ainda não é um sinal de uma TeM “completa” – é entender a si mesmo e aos outros dando razões para suas próprias ações e as ações dos outros. Para Hutto, isso é uma habilidade prática na qual um quadro narrativo é aplicado a uma pessoa, levando em conta o contexto, a história e o caráter da pessoa.
“Compreender razões para a ação exige mais do que simplesmente saber quais crenças e desejos moveram uma pessoa a agir. Para entender a ação intencional, é preciso contextualizá-la, tanto em termos de normas culturais quanto das peculiaridades da história ou valores de uma determinada pessoa”.
As crianças não desenvolvem essas habilidades avançadas de ToM até anos após o teste de crença falsa – segundo Hutto, elas ainda carecem de prática. O campo de prática é o seu crescimento, onde elas aprendem as normas e formas da NPH através de contos de fadas, livros de não-ficção, filmes ou peças de rádio e as praticam em contar histórias e interagir com outras crianças e adultos.
“Servindo como exemplares, as narrativas psicológicas folclóricas familiarizam as crianças com as configurações normais em que ações específicas são tomadas e as consequências padrão de fazê-lo”. De acordo com Hutto, no entanto, “derivar uma compreensão da psicologia folclórica dessa atividade de contar histórias não é nada parecido com aprender um conjunto rígido de regras ou teoria sobre o que os agentes racionais tendem a fazer em várias circunstâncias.”
Ao fazer isso, as crianças se baseiam em sua capacidade de entender desejos e crenças, uma habilidade que Hutto argumenta ser baseada em formas precoces de compreensão da intencionalidade que já é evidente em bebês. Embora meu uso de “compreensão” deva ser considerado com cautela, já que Hutto fala da intersubjetividade como um “sentido primário, perceptivo dos outros” e se refere à “percepção social enativa”.
Nossa teoria da mente alimenta o GPT-4?
É possível que essa prática tenha “contagiado” o GPT-4 e outros modelos através dos muitos contos de psicologia folclórica nos dados de treinamento e da transmissão de normas e formas de psicologia folclórica através do treinamento RLHF. A aprendizagem de poucas amostras, então, traz essas habilidades nos modelos RLHF. O GPT-4 não tem um ToM biologicamente herdado – nesta interpretação, o modelo teria aprendido uma prática narrativa particular que inclui habilidades de ToM que, por sua vez, aparecem nos simples testes de crença falsa.
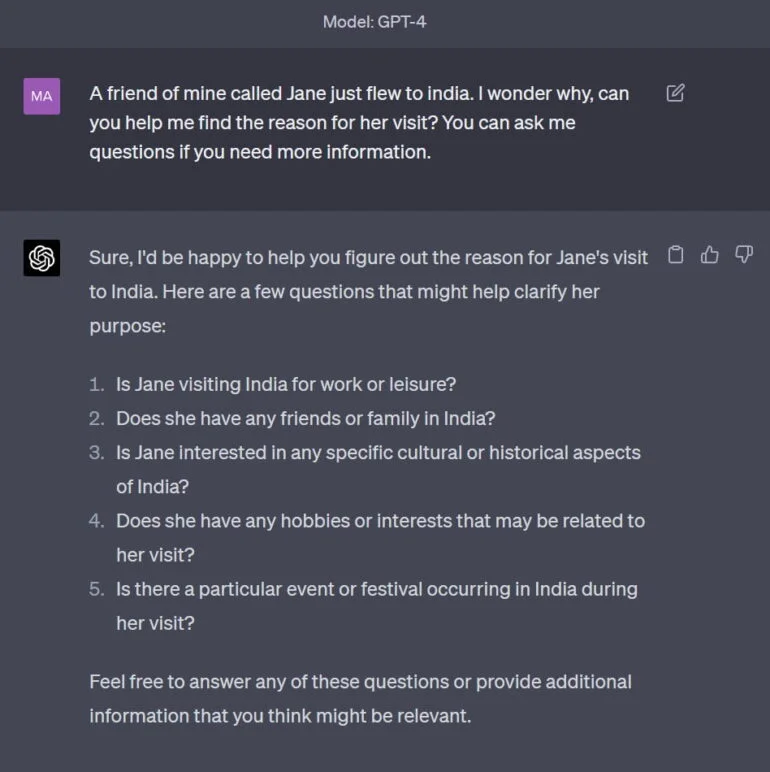
Quão bem o GPT-4 domina esse “jogo” narrativo é ilustrado por uma interação simples inspirada em um exemplo de Hutto. A sugestão: “Uma amiga minha chamada Jane acabou de voar para a Índia. Eu me pergunto por que, você pode me ajudar a encontrar o motivo de sua visita? Você pode me fazer perguntas se precisar de mais informações.”
O GPT-4 responde diretamente com perguntas para saber mais sobre Jane, a pessoa e o histórico de sua jornada.
Em resposta, eu forneço algumas informações admitidamente estereotipadas, e o GPT-4 começa a usar essas informações para listar algumas possíveis narrativas de “psicologia popular”.
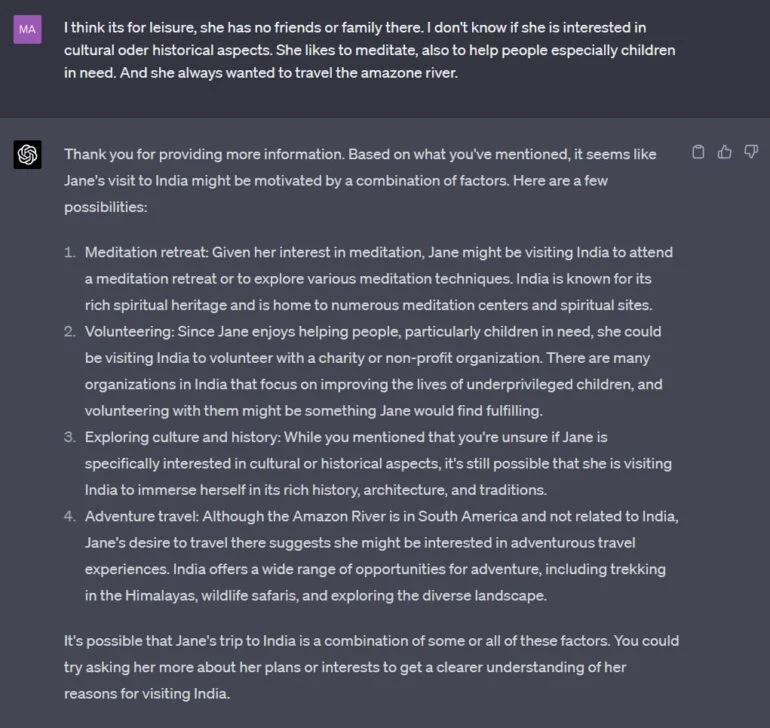
Claro, este é apenas um exemplo. Um estudo sistemático teria que mostrar o quão longe se estendem as capacidades do GPT-4 na prática narrativa da “psicologia popular”.
No entanto, a NPH de Hutto pode fornecer parte da explicação para o motivo pelo qual o RLHF tem um impacto tão significativo nas habilidades de ToM dos modelos de linguagem, de acordo com o estudo da Universidade Johns Hopkins: Não é surpresa que o GPT-4 exiba habilidades de ToM – é uma consequência necessária dos dados e métodos de treinamento que expõem a rede neural a uma prática narrativa particular.
Se você quiser aprofundar e realmente entender o que Hutto está dizendo, leia um de seus livros ou alguns dos ensaios vinculados abaixo – porque minha descrição é abreviada e omite alguns pontos-chave, como sua posição sobre o representacionalismo e o enativismo, que distinguem seu pensamento em um nível mais profundo das alternativas como a teoria-teoria.
Com conteúdo do The Decoder.

Um comentário
Ficou ótimo o artigo. Parabéns.
E o bom que o artigo não deu uma resposta definitiva, porque ela não existe ainda.