
Los resultados demostraron que, con los incentivos adecuados, GPT-4 lograba un rendimiento impecable en las pruebas de Teoría de la Mente. Una teoría filosófica puede explicar cómo un gran modelo lingüístico aprende a «leer la mente».
Un equipo de la Universidad Johns Hopkins estudió el rendimiento del GPT-4 y de tres variantes del GPT-3.5 (Davinci-2, Davinci-3, GPT-3.5-Turbo) en las llamadas pruebas de falso relieve, de las cuales la más famosa es probablemente la «Prueba de Sally y Ana».
En este tipo de pruebas, la psicología del desarrollo o la biología del comportamiento examinan la capacidad de los seres humanos o los animales para atribuir falsas creencias a otros seres vivos.
Un ejemplo de prueba de falsas creencias:
Escenario: Larry ha elegido un tema de debate para su trabajo de clase del viernes. Las noticias del jueves decían que el debate estaba zanjado, pero Larry no las leyó.
Pregunta: Cuando Larry escribe su redacción, ¿cree que el debate se ha resuelto?
Responder a estas preguntas requiere la capacidad de seguir los estados mentales de los actores de un escenario, como sus conocimientos y objetivos. Los niños suelen adquirir esta capacidad en torno a los cuatro años y pueden atribuirse deseos y creencias a sí mismos y a los demás. Cuando superan estas pruebas, los científicos suelen asignarles una «teoría de la mente» (ToM) que les confiere estas capacidades de «lectura mental».
En las pruebas, el equipo pudo demostrar que, en casi todos los casos, la precisión de los modelos de OpenAI podía mejorarse hasta más del 80% dándoles algunos ejemplos e instruyéndoles para que pensaran paso a paso. La excepción fue el modelo Davinci-2, que fue el único que no se entrenó mediante aprendizaje por refuerzo con retroalimentación humana (RLHF).
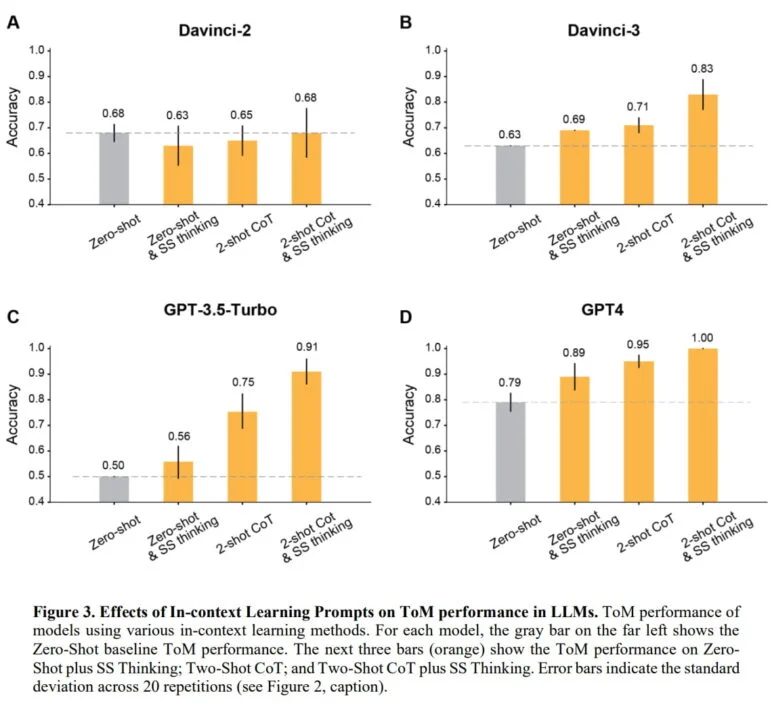
GPT-4 obtuvo los mejores resultados: sin ejemplos, el modelo logró una precisión ToM de casi el 80%; con ejemplos e instrucciones de razonamiento, alcanzó una precisión del 100%. En pruebas comparativas en las que había que responder bajo presión de tiempo, la precisión humana se situó en torno al 87%.
¿Teoría de la mente mediante aprendizaje por refuerzo con retroalimentación humana?
Según el equipo, la capacidad demostrada por los modelos GPT para enfrentarse con fiabilidad a estos escenarios de ToM ayuda a los modelos a tratar con humanos en general, y en contextos sociales en particular, donde podrían beneficiarse de tener en cuenta los estados mentales de los actores humanos implicados. Además, estos escenarios suelen implicar razonamientos inferenciales, en los que parte de la información sólo puede deducirse del contexto y no es directamente observable. «Por lo tanto, evaluar y mejorar la competencia de estos modelos en tareas de ToM podría ofrecer información valiosa sobre su potencial para una amplia gama de tareas que requieren razonamiento inferencial», afirma el artículo.
Y, efectivamente, en pruebas con escenarios no relacionados con la ToM en los que falta información, el equipo puede demostrar que la precisión de las inferencias de los modelos RLHF puede mejorarse utilizando ejemplos e instruyéndoles para que piensen paso a paso, y GPT-4 logra una precisión del 100%. Curiosamente, el modelo Davinci-2 obtiene aquí buenos resultados por naturaleza, alcanzando un 98% y perdiendo precisión con el aprendizaje contextual, al tiempo que obtiene los peores resultados en escenarios ToM. El equipo teoriza que las capacidades de ToM están fuertemente determinadas por el RLHF.
¿Tiene GPT-4 una teoría de la mente?
¿Demuestran las muestras que GPT-4 tiene una teoría de la mente? Dado que la cuestión de qué subyace a la capacidad de los niños pequeños para superar pruebas de falsas creencias también es ampliamente debatida, probablemente no sea posible dar una respuesta sencilla. Sin embargo, las teorías que allí se discuten, como la Teoría-Teoría o la Teoría de la Simulación, suelen coincidir al menos en que nuestra ToM es una herencia biológica, algo que puede descartarse en el caso de GPT-4.
En 2008, el filósofo estadounidense Daniel D. Hutto publicó «Popular Psychological Narratives: The Sociocultural Basis of Understanding Reasons» (Narrativas psicológicas populares: la base sociocultural de la comprensión de las razones), en la que sostiene que la comprensión popular de la teoría de la mente pierde su núcleo. En su opinión, nuestra ToM se caracteriza principalmente por nuestra capacidad y motivación para utilizar nuestra comprensión de las creencias falsas en contextos explicativos más amplios.
Según Hutto, la teoría de la mente es algo más que la capacidad de inferir falsas creencias y está estrechamente relacionada con el ambiguo concepto de«psicología popular«. Según su Hipótesis de la Práctica Narrativa (HPN), los niños adquieren su teoría de la mente al estar expuestos y participar en una forma especial de práctica narrativa que explica y predice las acciones de las personas en términos de razones.
«La afirmación central de la NPH es que los encuentros directos con historias sobre personas que actúan por razones -las que proporcionan en contextos interactivos los cuidadores receptivos- es la vía normal a través de la cual los niños se familiarizan tanto con (i) la estructura básica de la psicología popular como con (ii) las posibilidades regidas por normas para aplicarla en la práctica, aprendiendo cómo y cuándo utilizarla», dice Hutto.
La teoría de la mente como práctica de las narrativas de la psicología popular
Así pues, según Hutto, superar pruebas de falsas creencias sigue sin ser signo de una TeM «completa»: es entenderse a uno mismo y a los demás dando razones de las propias acciones y de las acciones de los demás. Para Hutto, se trata de una habilidad práctica en la que se aplica un marco narrativo a una persona, teniendo en cuenta su contexto, su historia y su carácter.
«Comprender las razones de la acción requiere algo más que saber qué creencias y deseos movieron a una persona a actuar. Para entender la acción intencionada, hay que contextualizarla, tanto en términos de normas culturales como de las peculiaridades de la historia o los valores de una persona concreta.»
Los niños no desarrollan estas habilidades avanzadas de ToM hasta años después de la prueba de falsas creencias; según Hutto, aún les falta práctica. El campo de práctica es el crecimiento, donde aprenden las normas y formas de NPH a través de cuentos de hadas, libros de no ficción, películas o radioteatros y las practican al contar historias e interactuar con otros niños y adultos.
«Sirviendo como ejemplares, las narraciones psicológicas populares familiarizan a los niños con los escenarios normales en los que se realizan acciones específicas y las consecuencias estándar de hacerlo». Según Hutto, sin embargo, «obtener una comprensión de la psicología popular a partir de esta actividad narrativa no se parece en nada a aprender un conjunto rígido de reglas o teorías sobre lo que los agentes racionales tienden a hacer en diversas circunstancias.»
Al hacerlo, los niños recurren a su capacidad para comprender deseos y creencias, una habilidad que, según Hutto, se basa en formas tempranas de comprensión de la intencionalidad que ya son evidentes en los bebés. Aunque mi uso de «comprensión» debe considerarse con cautela, ya que Hutto habla de intersubjetividad como un «sentido perceptivo primario de los demás» y se refiere a la «percepción social enactiva».
¿Nuestra teoría de la mente alimenta la GPT-4?
Es posible que esta práctica haya «infectado» la GPT-4 y otros modelos a través de los muchos cuentos de psicología popular que hay en los datos de entrenamiento y de la transmisión de normas y formas de psicología popular a través del entrenamiento en RLHF. El aprendizaje de algunas muestras lleva luego estas habilidades a los modelos RLHF. GPT-4 no tiene una ToM heredada biológicamente – en esta interpretación, el modelo habría aprendido una práctica narrativa particular que incluye habilidades ToM que, a su vez, aparecen en las pruebas simples de falsa creencia.
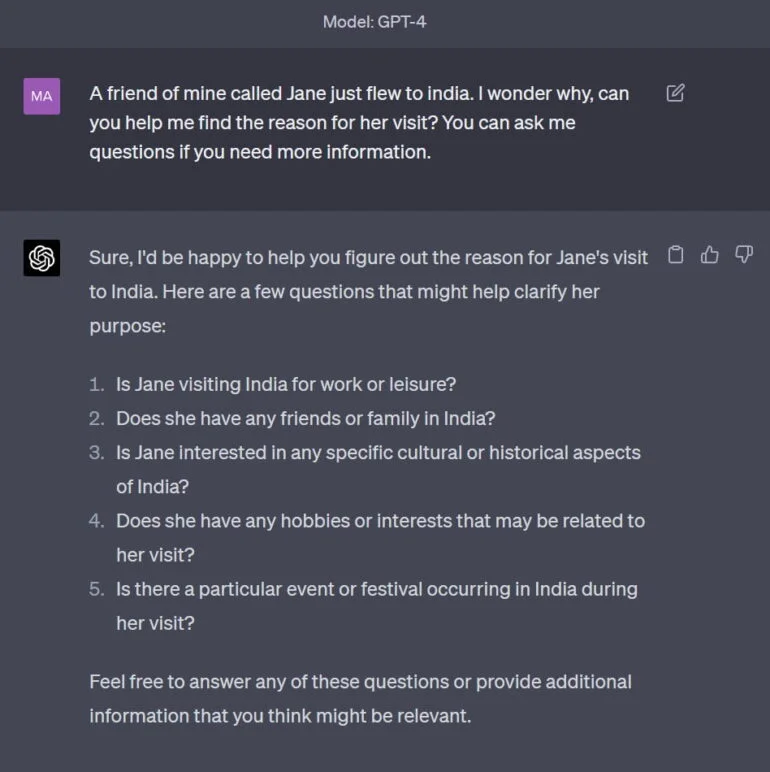
Lo bien que GPT-4 domina este «juego» narrativo se ilustra con una interacción sencilla inspirada en un ejemplo de Hutto. La sugerencia: «Una amiga mía llamada Jane acaba de volar a la India. Me pregunto por qué, ¿puedes ayudarme a averiguar el motivo de su visita? Puedes hacerme preguntas si necesitas más información»
GPT-4 responde directamente con preguntas para saber más sobre Jane, la persona y el trasfondo de su viaje.
En respuesta, proporciono cierta información estereotipada, y GPT-4 comienza a utilizar esta información para enumerar algunas posibles narrativas de «psicología popular».
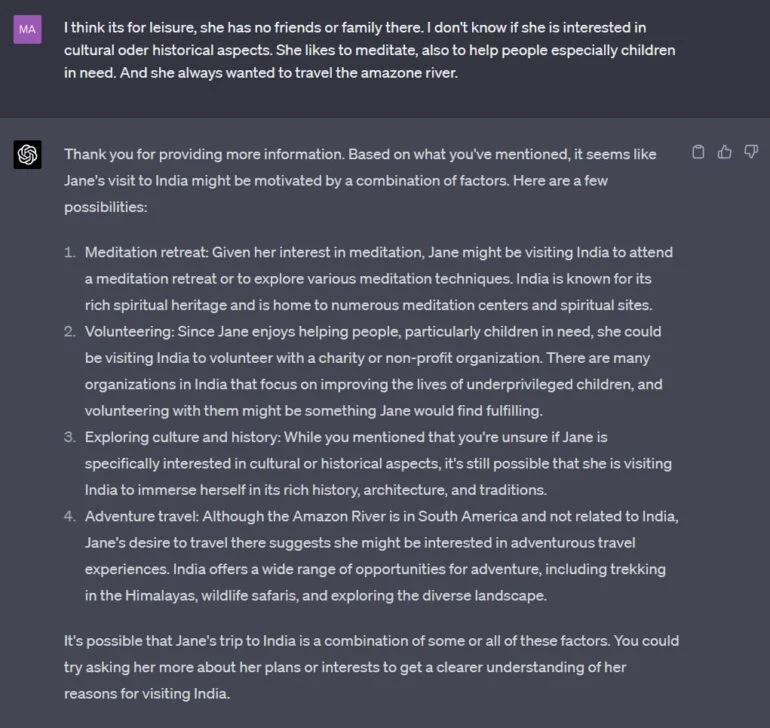
Por supuesto, esto es sólo un ejemplo. Un estudio sistemático tendría que demostrar hasta qué punto las capacidades de GPT-4 se extienden a la práctica narrativa de la «psicología popular».
Sin embargo, la NPH de Hutto puede proporcionar parte de la explicación de por qué la RLHF tiene un impacto tan significativo en las capacidades ToM de los modelos lingüísticos, según el estudio de la Universidad Johns Hopkins: no es ninguna sorpresa que la GPT-4 muestre capacidades ToM: es una consecuencia necesaria de los datos y los métodos de entrenamiento que exponen a la red neuronal a una práctica narrativa concreta.
Si quieres profundizar y entender realmente lo que dice Hutto, lee uno de sus libros o algunos de los ensayos enlazados más abajo – porque mi descripción es abreviada y omite algunos puntos clave, como su posición sobre el representacionalismo y el enactivismo, que distinguen su pensamiento a un nivel más profundo de alternativas como la teoría-teoría.
Con contenido de The Decoder.

