
Vídeos de falhas no YouTube revelam uma grande deficiência dos principais modelos de IA: eles têm dificuldade com surpresas e raramente reconsideram suas primeiras impressões. Até mesmo sistemas avançados, como o GPT-4o, se atrapalham com reviravoltas simples.
Pesquisadores da Universidade de British Columbia, do Vector Institute for AI e da Nanyang Technological University colocaram os principais modelos de IA à prova utilizando mais de 1.600 vídeos de falhas do YouTube provenientes do conjunto de dados Oops!.
A equipe criou um novo benchmark, chamado BlackSwanSuite, para testar como esses sistemas lidam com eventos inesperados. Assim como acontece com as pessoas, os modelos de IA se deixam enganar por momentos surpreendentes — mas, diferentemente dos humanos, eles se recusam a mudar suas opiniões mesmo depois de ver o que realmente ocorreu.
Um exemplo: um homem balança um travesseiro próximo a uma árvore de Natal. A IA assume que ele está mirando em alguém nas proximidades. Na realidade, o travesseiro derruba os enfeites da árvore, que acabam atingindo uma mulher. Mesmo após assistir ao vídeo completo, a IA mantém sua hipótese inicial, embora incorreta.
Os vídeos abrangem diversas categorias, com a maioria apresentando acidentes de trânsito (24%), acidentes com crianças (24%) ou acidentes em piscinas (16%). O que os une é uma reviravolta imprevisível que frequentemente passa despercebida.
Três tipos de tarefas
Cada vídeo é dividido em três segmentos: a preparação, a surpresa e as consequências. O benchmark desafia os modelos de linguagem com diferentes tarefas para cada etapa. Na tarefa de “Previsor”, a IA vê apenas o início do vídeo e tenta prever o que acontecerá a seguir. Na tarefa de “Detetive”, são mostrados apenas o começo e o fim, e a IA deve explicar o que ocorreu no meio. Já na tarefa de “Repórter”, a IA assiste ao vídeo completo e precisa atualizar suas hipóteses após conhecer toda a história.

O benchmark inclui 15.469 questões distribuídas entre as três tarefas baseadas em vídeo. Os testes abrangeram tanto modelos fechados, como o GPT-4o e o Gemini 1.5 Pro, quanto sistemas de código aberto, como o LLaVA-Video, VILA, VideoChat2 e VideoLLaMA 2. Os resultados evidenciam fragilidades marcantes. Na tarefa de Detetive, o GPT-4o obteve apenas 65% de acertos, enquanto os humanos chegaram a 90%.
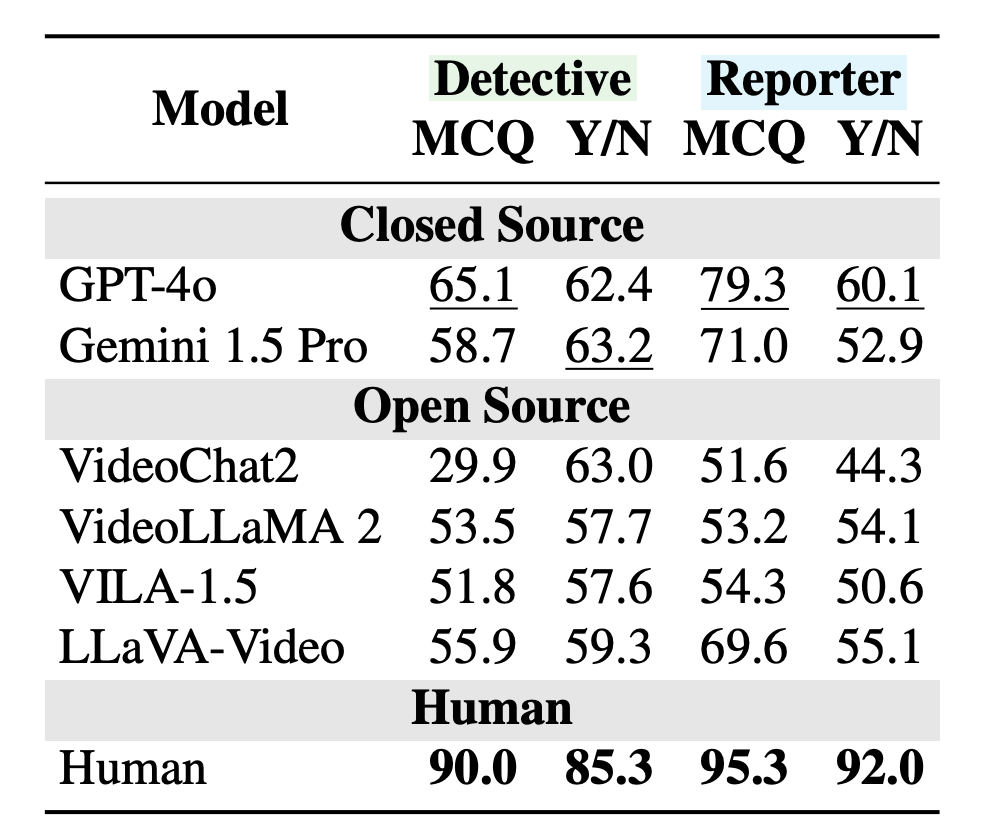
A diferença aumentou ainda mais quando os modelos precisaram reconsiderar suas hipóteses iniciais. Ao serem solicitados a rever suas previsões após assistir ao vídeo completo, o GPT-4o alcançou somente 60% de acerto — 32 pontos percentuais a menos do que os 92% dos humanos. Os sistemas tendem a insistir em suas primeiras impressões, ignorando as novas evidências. Outros modelos, como o Gemini 1.5 Pro e o LLaVA-Video, demonstraram o mesmo padrão, e o desempenho caiu drasticamente em vídeos que até mesmo as pessoas acharam difíceis de interpretar à primeira vista.
Caminhões de lixo não deixam cair árvores, certo?
A raiz do problema está na forma como esses modelos de IA são treinados. Eles aprendem identificando padrões em milhões de vídeos e esperam que esses padrões se repitam. Assim, quando um caminhão de lixo solta uma árvore em vez de coletar o lixo, a IA se confunde por não reconhecer esse padrão.

O GPT-4o segue suas impressões iniciais e escolhe a resposta errada. Para identificar o problema, a equipe substituiu a percepção visual da IA por descrições detalhadas escritas por humanos das cenas, o que elevou o desempenho do LLaVA-Video em 6,4%. Ao adicionar ainda mais explicações, o desempenho aumentou em mais 3,6%, totalizando um ganho de 10%.
Ironicamente, isso só reforça a fraqueza dos modelos: se a IA apresenta bom desempenho apenas quando os humanos realizam a tarefa perceptual, ela falha em “ver” e “compreender” antes de iniciar um raciocínio real. Por outro lado, os humanos são rápidos em repensar suas suposições ao receber novas informações, algo que os modelos atuais de IA ainda não conseguem fazer.
Essa limitação pode ter consequências sérias em aplicações do mundo real, como carros autônomos e sistemas autônomos, pois a vida é cheia de surpresas: crianças correndo para a rua, objetos que caem de caminhões e outros comportamentos inesperados dos condutores.
A equipe de pesquisadores disponibilizou o benchmark no GitHub e no Hugging Face, esperando que outros pesquisadores utilizem essa ferramenta para testar e aprimorar seus próprios modelos de IA. Enquanto os sistemas líderes se surpreenderem com vídeos de falhas simples, ainda não estarão prontos para lidar com a imprevisibilidade do mundo real.
