
Pesquisadores avaliam modelos de IA por meio do jogo “Ace Attorney”
Pesquisadores submeteram modelos de IA de ponta a um novo tipo de teste — um que avalia a capacidade de raciocinar para conquistar uma vitória no tribunal. Os resultados evidenciam diferenças claras tanto em desempenho quanto em custo.
Uma equipe do Hao AI Lab, da Universidade da Califórnia em San Diego, avaliou os modelos de linguagem atuais utilizando o jogo Phoenix Wright: Ace Attorney, que exige dos jogadores a coleta de evidências, a identificação de contradições e a revelação da verdade por trás das mentiras.
De acordo com o Hao AI Lab, Ace Attorney é particularmente adequado para esse teste, pois requer que os jogadores coletem evidências, descubram contradições e desvendem a verdade oculta nas histórias. Os modelos tiveram que vasculhar longas conversas, identificar inconsistências durante os interrogatórios e selecionar as evidências apropriadas para contestar os depoimentos das testemunhas.
O experimento foi parcialmente inspirado pelo cofundador da OpenAI, Ilya Sutskever, que certa vez comparou a previsão da próxima palavra ao entendimento de uma história de detetive. Recentemente, Sutskever garantiu financiamento adicional de vários bilhões de euros para uma nova iniciativa em IA.
o1 lidera, Gemini segue
Os pesquisadores testaram diversos modelos de IA multimodal e de raciocínio, incluindo o o1 da OpenAI, Gemini 2.5 Pro, Claude 3.7-thinking e Llama 4 Maverick. Tanto o o1 quanto o Gemini 2.5 Pro avançaram até o nível 4, mas o o1 se destacou nos casos mais desafiadores.
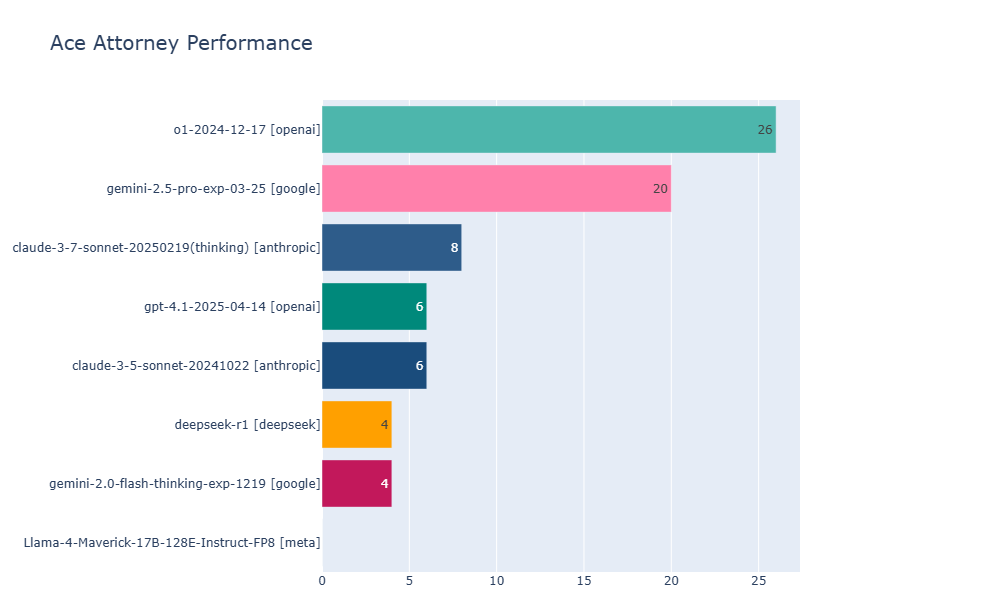
Com pontuações de 26 e 20, os modelos o1-2024-12-17 e Gemini-2.5-Pro atingiram os melhores resultados no teste de desempenho de Ace Attorney.
O teste vai além de uma simples análise de texto ou imagem. Conforme explicado pela equipe, os modelos precisam vasculhar longos contextos, reconhecer contradições, compreender informações visuais com precisão e tomar decisões estratégicas ao longo do jogo.
“O design do jogo impulsiona a IA para além de tarefas puramente textuais e visuais, exigindo que ela converta o entendimento em ações contextualizadas. É mais difícil ocorrer overfitting, pois o sucesso aqui demanda raciocínio sobre um espaço de ações adaptado ao contexto — não apenas memorização”, explicam os pesquisadores.
O overfitting ocorre quando um modelo de linguagem memoriza os dados de treinamento — incluindo aleatoriedades e erros — de forma que seu desempenho em novos exemplos seja prejudicado. Esse problema também se verifica em modelos de raciocínio otimizados para tarefas matemáticas e de programação. Embora esses modelos possam se tornar mais eficientes na busca por soluções corretas, essa eficiência tende a reduzir a diversidade dos caminhos considerados.
Gemini 2.5 Pro oferece melhor custo-benefício
O Gemini 2.5 Pro mostrou ser significativamente mais econômico que os outros modelos testados. Segundo o Hao AI Lab, ele é de seis a quinze vezes mais barato que o o1, dependendo do cenário. Em um caso particularmente extenso do Nível 2, o o1 gerou custos superiores a US$ 45,75, enquanto o Gemini 2.5 Pro completou a tarefa por US$ 7,89.
Além disso, o Gemini 2.5 Pro superou o GPT-4.1 — que não é especificamente otimizado para o raciocínio — em termos de custo, registrando US$ 1,25 por milhão de tokens de entrada, em comparação aos US$ 2 do GPT-4.1. Os pesquisadores observam, entretanto, que os custos reais podem ser um pouco maiores devido às exigências do processamento de imagens.
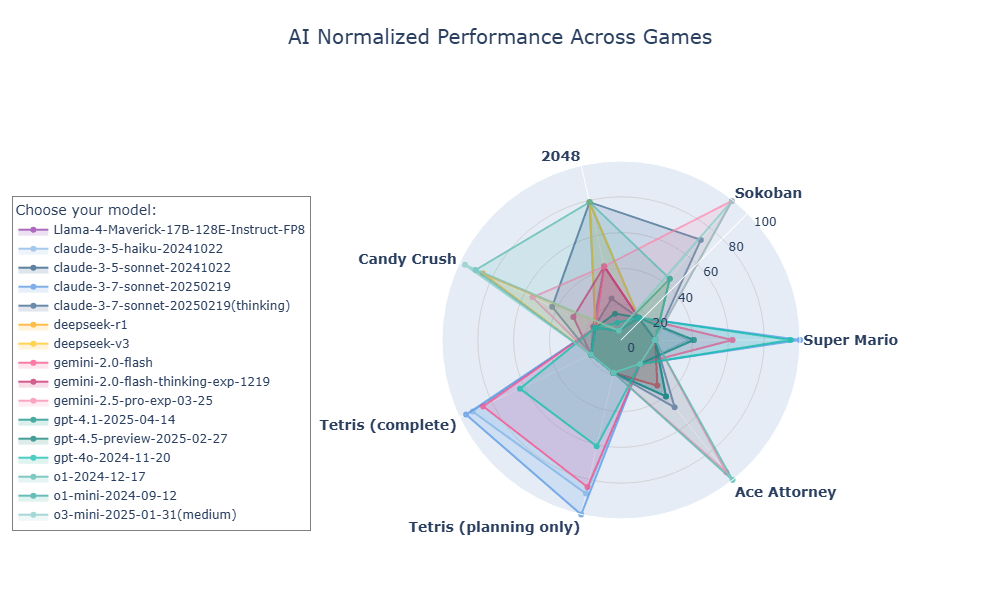
No benchmark Game Arena, o Hao AI Lab já comparou os atuais modelos de linguagem em jogos como 2048, Tetris, Sokoban e Candy Crush. Desde fevereiro, a equipe vem avaliando esses modelos em uma variedade de jogos, incluindo Candy Crush, 2048, Sokoban, Tetris e Super Mario. Entre os títulos testados até o momento, Ace Attorney se destaca como o jogo com as mecânicas mais exigentes no que diz respeito ao raciocínio.
