

Como parte do projeto Massively Multilingual Speech, a Meta está lançando modelos de IA que podem converter a linguagem falada em texto e texto em fala em 1.100 idiomas.
O novo conjunto de modelos é baseado no wav2vec da Meta, bem como em um conjunto de dados selecionados de exemplos para 1.100 idiomas e outro conjunto de dados não selecionados para quase 4.000 idiomas, incluindo idiomas falados por apenas algumas centenas de pessoas, para os quais ainda não existe tecnologia de fala, de acordo com a Meta.
O modelo pode se expressar em mais de 1.000 idiomas e identificar mais de 4.000 idiomas. Segundo a Meta, o MMS supera os modelos anteriores cobrindo dez vezes mais idiomas. Você pode obter uma visão geral de todos os idiomas disponíveis aqui.
Novo Testamento ganha novo uso como conjunto de dados de IA
Um componente-chave do MMS é a Bíblia, especificamente o Novo Testamento. O conjunto de dados da Meta contém leituras do Novo Testamento em mais de 1.107 idiomas, com uma duração média de 32 horas.
A Meta utilizou essas gravações em combinação com trechos correspondentes da internet. Além disso, outros 3.809 arquivos de áudio sem rotulação foram utilizados, também com leituras do Novo Testamento, mas sem informações adicionais sobre o idioma.
Uma vez que 32 horas por idioma não são material de treinamento suficiente para um sistema confiável de reconhecimento de fala, a Meta utilizou o wave2vec 2.0 para pré-treinar os modelos MMS com mais de 500.000 horas de fala em mais de 1.400 idiomas. Esses modelos foram posteriormente ajustados para compreender ou identificar inúmeros idiomas.
Os benchmarks mostram que o desempenho do modelo permaneceu praticamente constante, mesmo com o treinamento em um número maior de idiomas diferentes. Na verdade, a taxa de erro diminuiu minimamente em 0,4 pontos percentuais com o aumento do treinamento.
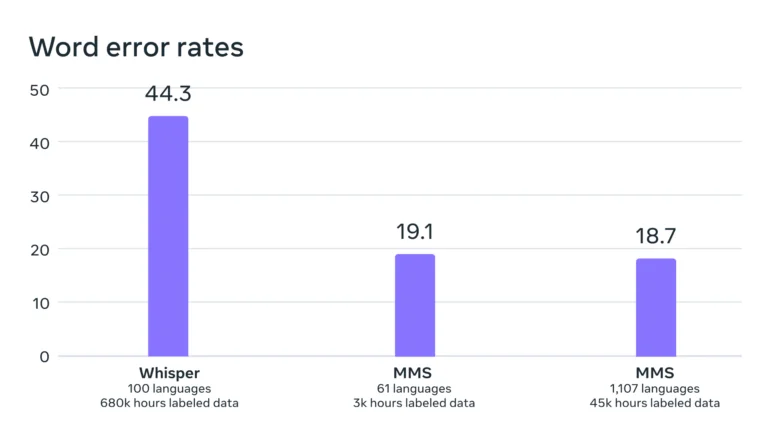
De acordo com a Meta, a taxa de erro do modelo deles é significativamente menor do que a do Whisper da OpenAI, que não foi otimizado explicitamente para um amplo multilinguismo. Uma comparação apenas em inglês seria mais interessante. Os primeiros testadores no Twitter relatam que o Whisper tem um desempenho melhor nesse aspecto.
MMS: Massively Multilingual Speech.
— Yann LeCun (@ylecun) May 22, 2023
– Can do speech2text and text speech in 1100 languages.
– Can recognize 4000 spoken languages.
– Code and models available under the CC-BY-NC 4.0 license.
– half the word error rate of Whisper.
Code+Models: https://t.co/zQ9lWms5TQ
Paper:…
De acordo com a Meta, o fato de as vozes no conjunto de dados serem predominantemente masculinas não afeta negativamente a compreensão ou geração de vozes femininas.
Além disso, o modelo não tende a gerar discursos excessivamente religiosos. A Meta atribui isso à abordagem de classificação utilizada (Classificação Temporal Connectionista), que se concentra mais em padrões e sequências de fala do que no conteúdo e significado das palavras.
No entanto, a Meta alerta que o modelo às vezes transcreve palavras ou frases de forma incorreta, o que pode levar a declarações incorretas ou ofensivas.
Um modelo para milhares de idiomas
O objetivo a longo prazo da Meta é desenvolver um único modelo de linguagem para o maior número possível de idiomas, a fim de preservar idiomas ameaçados. Modelos futuros podem suportar ainda mais idiomas e até mesmo dialetos.
“Nosso objetivo é facilitar o acesso das pessoas à informação e permitir que elas usem dispositivos em seu idioma preferido”, escreve a Meta. Cenários de aplicação específicos incluem tecnologias de realidade virtual e aumentada, ou mensagens.
No futuro, um único modelo poderia ser treinado para todas as tarefas, como reconhecimento de fala, síntese de fala e identificação de fala, levando a um desempenho geral ainda melhor, escreve a Meta.
O código, os modelos pré-treinados do MMS com 300 milhões e um bilhão de parâmetros, respectivamente, e as derivações refinadas para reconhecimento e identificação de fala, assim como a síntese de texto para fala, estão disponíveis pela Meta como modelos de código aberto no Github.
