
O Qwen3.5 Livre da Alibaba Sinaliza que a Corrida dos Modelos de Peso Aberto na China Ainda Está a Todo Vapor
A Alibaba lançou o Qwen3.5-397B-A17B, o primeiro modelo de sua nova série. Ele processa texto, imagens e vídeo em uma única arquitetura e está disponível gratuitamente como um modelo de pesos abertos.
O modelo conta com 397 bilhões de parâmetros no total, mas apenas 17 bilhões são ativados para uma determinada consulta. Assim como outros grandes modelos de IA, ele utiliza uma arquitetura de mixture-of-experts que ativa somente as partes relevantes da rede de acordo com a tarefa.
A razão entre parâmetros totais e ativos é incomumente alta no Qwen3.5, assim como no Qwen3-Next, sugerindo uma divisão especialmente detalhada entre muitos especialistas especializados. A Alibaba também incorporou uma nova arquitetura de atenção chamada Gated Delta Networks, projetada para reduzir ainda mais os custos computacionais.
A equipe do Qwen afirma que o Qwen3.5 processa solicitações 19 vezes mais rápido que seu predecessor muito maior, o Qwen3-Max, e de 3,5 a 7 vezes mais rápido que seu antecessor direto, o Qwen3-235B, com uma janela de contexto de 256.000 tokens, mantendo um desempenho comparável.

A Alibaba destaca que o Qwen3.5 é significativamente mais rápido que seus predecessores: com 32.000 tokens de contexto, oferece 8,6 vezes mais rendimento que o Qwen3-Max, e com 256.000 tokens essa vantagem aumenta para 19 vezes.
Melhorias em Tarefas de Agente e na Compreensão de Imagens
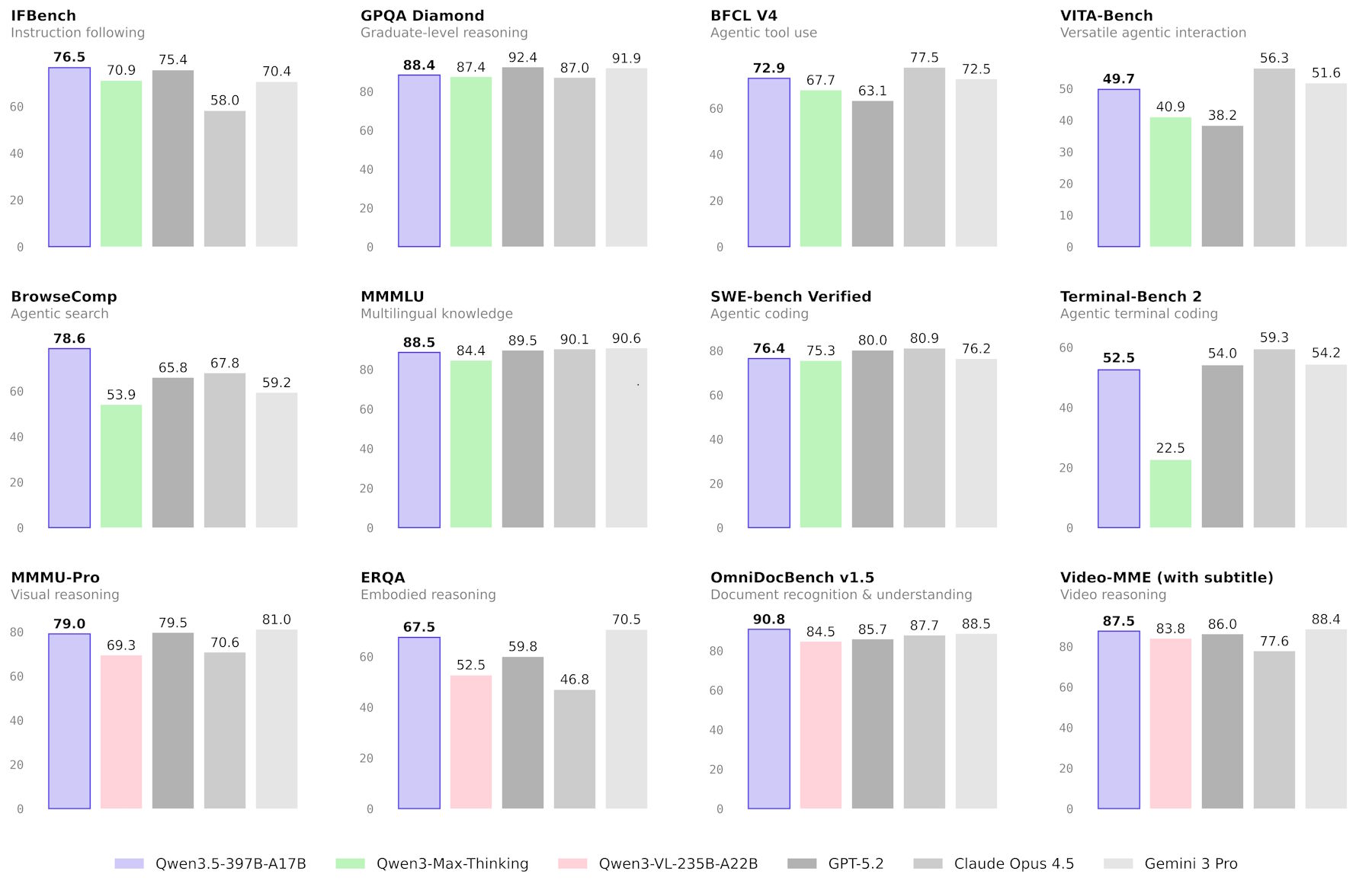
O Qwen3.5 estabelece novos recordes em alguns benchmarks, embora fique atrás do GPT-5.2, Claude 4.5 Opus e Gemini-3 Pro em outros. Os maiores avanços aparecem nas tarefas de agente: no TAU2, que mede o desempenho de um modelo como agente autônomo, o Qwen3.5 marcou 86,7 – apenas atrás do GPT-5.2 (87,1) e do Claude 4.5 Opus (91,6). Em instruções complexas, ele obteve os melhores resultados em IFBench (76,5) e MultiChallenge (67,6). Na prática, o modelo é capaz de criar uma apresentação de slides combinando imagens e comandos.
A Alibaba afirma que o Qwen3.5 alcança pontuações elevadas em diversos benchmarks matemático-visuais, incluindo MathVision (88,6) e ZEROBench (12). Ele também lidera na maioria dos testes de compreensão de documentos e reconhecimento de texto. No benchmark mais amplo de compreensão de imagens, o MMMU, o modelo fica ligeiramente atrás do Gemini 3 Pro (87,2) e do GPT-5.2 (86,7), com uma pontuação de 85.
Outros modelos ainda se destacam em raciocínio clássico e codificação: o GPT-5.2 obteve 87,7 no LiveCodeBench, comparado aos 83,6 do Qwen3.5. Em competições matemáticas, como o AIME26, o modelo alcança 91,3, ficando atrás do GPT-5.2 (96,7) e do Claude 4.5 Opus (93,3).
Mais Dados de Treinamento e um Reforço de Aprendizado Mais Intenso Impulsionam os Resultados
A equipe aponta que o salto em relação à série Qwen3 anterior se deve a uma fase de reinforcement learning massivamente expandida durante o treinamento. Em vez de otimizar o modelo para benchmarks individuais, eles aumentaram de forma sistemática a variedade e a dificuldade dos ambientes de treinamento. O maior retorno foi observado nas habilidades de agente.
O framework assíncrono de reinforcement learning do Qwen3.5 distribui a coleta de dados, a execução e o treinamento em clusters de GPU dedicados, sincronizando de forma contínua os parâmetros do modelo entre os componentes.
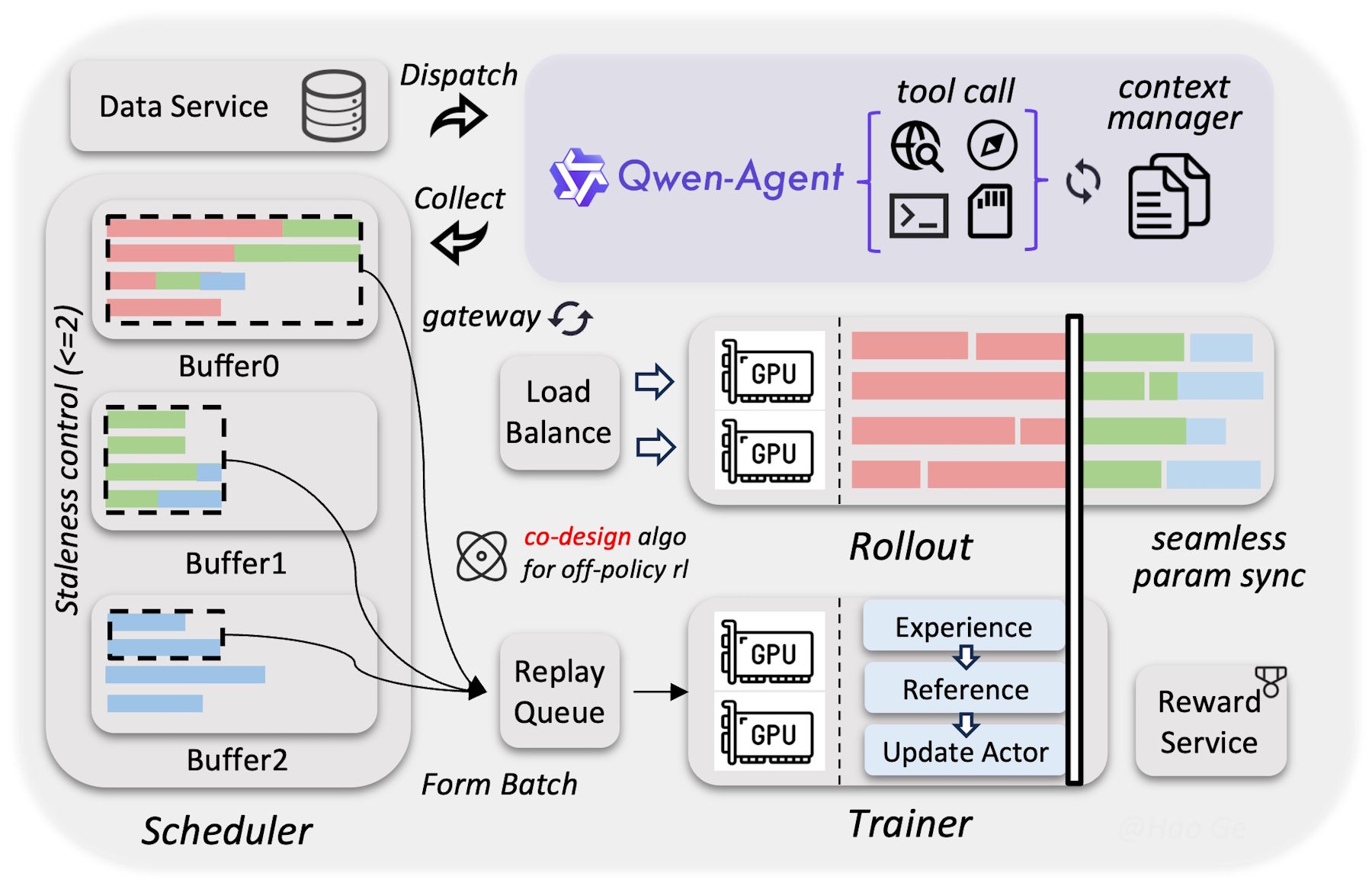
A Alibaba também informa que o modelo foi treinado com significativamente mais dados que seu predecessor, com uma filtragem mais rigorosa. Mesmo com uma arquitetura mais eficiente, o Qwen3.5 alcança o desempenho do Qwen3-Max-Base, que possui mais de um trilhão de parâmetros.
O suporte a idiomas passou de 119 para 201 línguas e dialetos. Um vocabulário ampliado, de 250 mil tokens (em comparação aos 150 mil anteriores), deve acelerar o processamento para a maioria das línguas entre 10% e 60%.
Do Resgate de Labirintos à Execução de Fluxos de Trabalho em Desktop
Como um modelo nativamente multimodal, o Qwen3.5 é capaz de lidar com até duas horas de vídeo, segundo a Alibaba. Em demonstrações publicadas, a empresa apresenta o modelo escrevendo código Python para solucionar um labirinto e mapeando visualmente o caminho mais curto. Em outro exemplo, ele analisa vídeos de tráfego e explica decisões de condução com base nas fases dos semáforos.
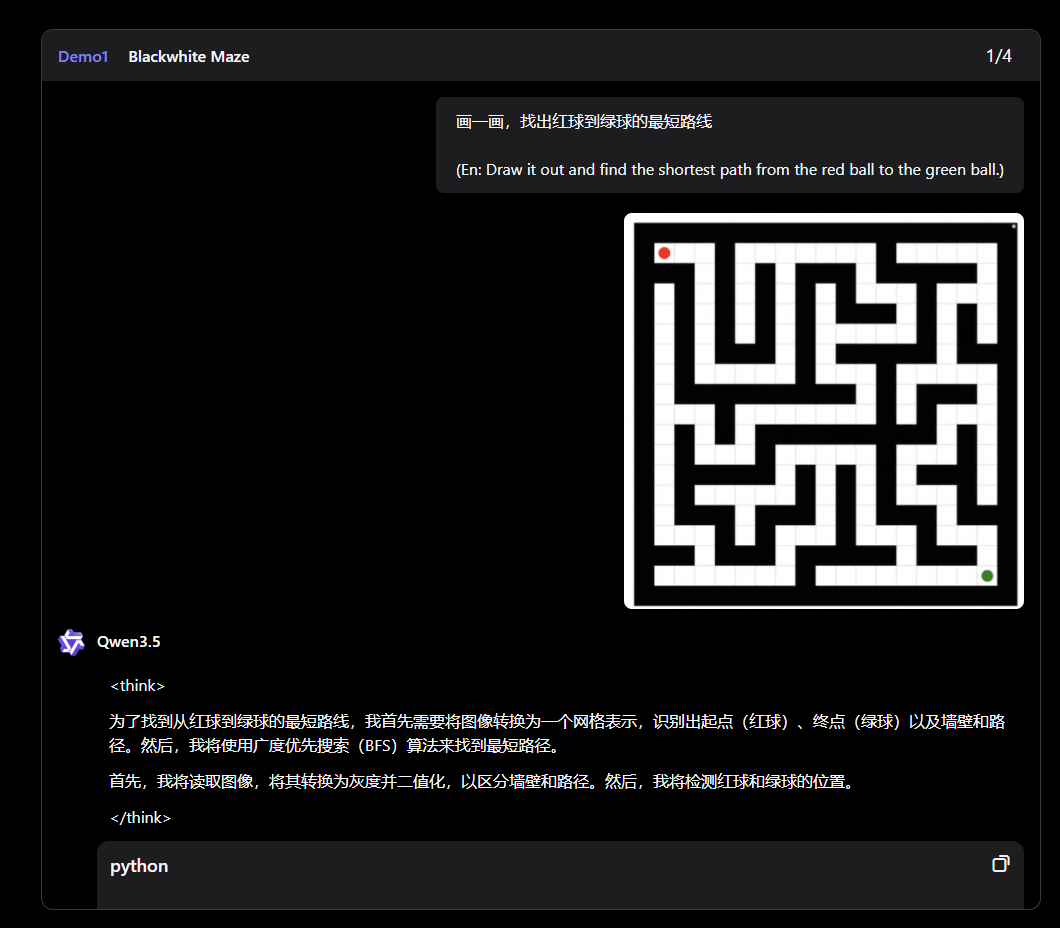
O Qwen3.5 analisa a imagem de um labirinto e escreve, de forma autônoma, código em Python para calcular o caminho mais curto entre o ponto de partida e a chegada.
Como agente de interface gráfica, o Qwen3.5 consegue operar interfaces de smartphones e computadores de forma independente – sendo capaz, por exemplo, de preencher planilhas do Excel ou executar fluxos de trabalho desktop em múltiplas etapas. Para desenvolvedores, a Alibaba oferece integrações com ferramentas como o Qwen Code, que converte instruções em linguagem natural em código funcional.
O próximo desafio, segundo a equipe do Qwen, é passar da escalabilidade do modelo para a integração de sistemas. Agentes futuros deverão contar com memória persistente, melhorar de forma autônoma ao longo do tempo e levar em consideração restrições de custo. Em vez de assistentes baseados em tarefas, a Alibaba pretende construir sistemas autônomos capazes de realizar trabalhos complexos de forma independente durante vários dias.
Disponibilidade
O modelo de pesos abertos Qwen3.5-397B-A17B está disponível para download no Hugging Face e é distribuído sob a licença Apache 2.0, que permite uso comercial e modificações. Desenvolvedores podem experimentá-lo diretamente no navegador através da interface Qwen Chat, nos modos Auto, Thinking ou Fast.
A versão hospedada, Qwen3.5-Plus, com uma janela de contexto de um milhão de tokens, está disponível via API por meio do Alibaba Cloud Model Studio e oferece suporte à busca na web, intérprete de código e raciocínio adaptativo. Além disso, o Qwen3.5 pode ser integrado a ferramentas como o Qwen Code, atuando como um agente de codificação.
O modelo é cobrado a US$0,40 por milhão de tokens de entrada e US$2,40 por milhão de tokens de saída via API – uma fração dos valores praticados pela OpenAI ou Anthropic para modelos com desempenho comparável em benchmarks, um padrão bastante adotado pelos laboratórios chineses de IA.
Os Laboratórios de IA Chineses Mantêm o Ritmo
O Qwen3.5 chega em meio a uma intensa corrida entre laboratórios de IA chineses. Recentemente, a Zhipu AI lançou o GLM-5, um modelo de código aberto com 744 bilhões de parâmetros, disputando com o Claude Opus 4.5 e o GPT-5.2 em tarefas de codificação e de agente. A Moonshot AI apresentou o Kimi K2.5, um modelo capaz de coordenar até 100 subagentes em paralelo. A MiniMax lançou o M2.5, prometendo uma “inteligência com custo tão baixo que é quase irrelevante”. E a Baidu conquistou a primeira posição entre todos os modelos chineses no ranking LMArena com o Ernie 5.0 e seus 2,4 trilhões de parâmetros.
O que esses modelos têm em comum? Desempenho em benchmark semelhante ao de modelos ocidentais, disponibilidade aberta e, para quem deseja acesso via API, preços extremamente competitivos em comparação aos seus equivalentes ocidentais. O próximo modelo de grande porte da Deepseek, com um trilhão de parâmetros, ainda está atrasado, mas há rumores de que pode ser lançado ainda esta semana.
