
Alguns veem a engenharia de instruções como um campo de carreira futuro, enquanto outros a veem como uma moda passageira. A pesquisa em IA da Microsoft descreve sua abordagem.
Em um artigo recente, pesquisadores da Microsoft descrevem seu processo de engenharia de instruções para o Dynamics 365 Copilot e o Copilot no Power Platform, duas implementações de modelos de chat da OpenAI.
A engenharia de instruções é baseada em tentativa e erro
Entre outras coisas, a equipe de pesquisa da Microsoft utiliza instruções gerais do sistema para seus chatbots, que é o que geralmente digitamos no ChatGPT e similares quando atribuímos um papel específico, conjunto de conhecimentos e comportamentos ao chatbot.
A instrução é “o mecanismo principal” para interagir com um modelo de linguagem e é uma “ferramenta extremamente eficaz”, escreve a equipe de pesquisa. Ela deve ser “precisa e precisa” ou o modelo ficará apenas supondo.

A Microsoft recomenda estabelecer algumas regras básicas para as instruções que são apropriadas para o chatbot.
Para a Microsoft, essas regras básicas incluem evitar opiniões subjetivas ou repetições, discussões ou insights excessivos sobre como proceder com o usuário e encerrar uma conversa que se torna controversa. As regras básicas também podem evitar que o chatbot seja vago, fuja do assunto ou insira imagens na resposta.
System message:
You are a customer service agent who helps users answer questions based on documents from## On Safety:
– e.g. be polite
– e.g. output in JSON format
– e.g. do not respond to if request contains harmful content…## Important
– e.g. do not greet the customer
–AI Assistant message:
## Conversation
User message:
AI Assistant message:
Microsoft sample prompt
No entanto, a equipe de pesquisa reconhece que a construção de tais instruções requer certa quantidade de “arte”, o que implica que é principalmente um ato criativo. Eles afirmam que as habilidades necessárias não são “extremamente difíceis de adquirir”.
Ao criar instruções, eles sugerem criar um framework no qual seja possível experimentar ideias e, em seguida, refiná-las. “A geração de instruções pode ser aprendida na prática”, escreve a equipe.
O papel futuro da engenharia de instruções ainda não está claro porque, por um lado, é verdade que a saída dos modelos depende muito da instrução. Por outro lado, a aleatoriedade dos geradores de texto dificulta o estudo da eficácia de métodos de instrução individuais, ou mesmo de elementos individuais nas instruções, de uma maneira que atenda aos padrões científicos.
Por exemplo, é, no mínimo, questionável se “mega-instruções” extensas produzem resultados melhores do que instruções concisas de três frases. Tais afirmações são difíceis de avaliar e são principalmente lucrativas para alguns modelos de negócio.
Eventualmente, a engenharia de instruções poderia evoluir de uma espécie de linguagem de programação pseudo para um processo criativo na gestão de fluxo de trabalho – quais processos de trabalho podem ser capturados pelos LLMs (Large Language Models) e com qual confiabilidade?
O modelo de linguagem então poderia gerar as instruções exatas por meio de consultas, testes de ajuste fino e exemplos. Os trabalhadores humanos teriam principalmente que conhecer as capacidades dos sistemas e definir e estabelecer novas formas de trabalho.
Usando dados contextuais para obter melhores respostas de IA
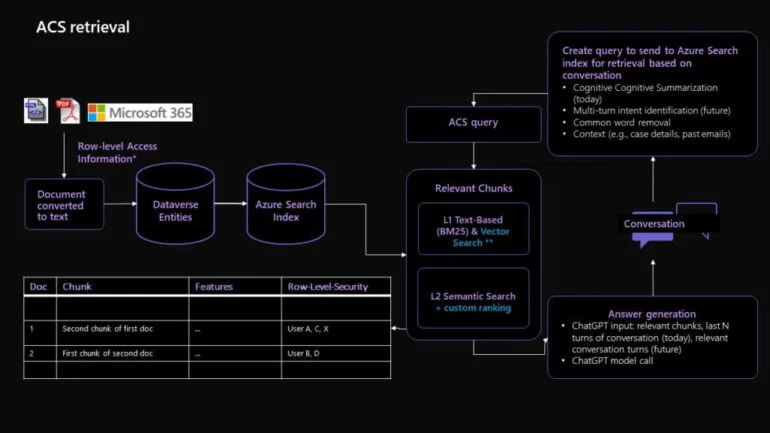
A abordagem da Microsoft para a engenharia de instruções vai além do uso tradicional de instruções padrão e inclui técnicas avançadas, como geração com aumento de recuperação (RAG, na sigla em inglês) e segmentação de base de conhecimento.
RAG é uma ferramenta poderosa que a Microsoft utiliza para processar dados diversos e em grandes quantidades, montando pequenos pedaços de dados relevantes, ou “chunks”, para problemas específicos de clientes.
Esses chunks são então comparados com dados históricos e feedback dos agentes para gerar a melhor resposta possível para a consulta do cliente. Ao mesmo tempo, a segmentação da base de conhecimento simplifica grandes blocos de dados, criando representações dos documentos.
Essas representações são então comparadas com a entrada do usuário para incorporar as representações com maior pontuação no modelo de instrução GPT para geração de resposta. Em combinação, essas técnicas ajudam a gerar respostas informadas, relevantes e personalizadas para as perguntas dos clientes.
Uma explicação técnica detalhada está disponível no Blog de Pesquisa da Microsoft.
