
Com o LIMA, os pesquisadores de IA da Meta apresentam um novo modelo de linguagem que alcança desempenho equivalente ao GPT-4 e ao Bard em cenários de teste, embora seja ajustado com relativamente poucos exemplos.
LIMA significa “Less is More for Alignment” (Menos é Mais para Alinhamento), e o nome sugere a função do modelo: mostrar que, com um modelo de IA extensivamente pré-treinado, poucos exemplos são suficientes para obter resultados de alta qualidade.
“Poucos exemplos” neste caso significa que a Meta selecionou manualmente 1.000 prompts diversificados e suas saídas de fontes como outros artigos de pesquisa, WikiHow, StackExchange e Reddit.
A equipe então utilizou esses exemplos para aprimorar seu próprio modelo LLaMA, com 65 bilhões de parâmetros, que vazou anteriormente e impulsionou o movimento de modelos de linguagem de código aberto. A Meta evitou o caro RLHF, que a OpenAI utiliza para ajustar seus modelos e considera uma parte importante do futuro da IA.
Estilo sobre substância
A Meta fez com que seres humanos comparassem os resultados do LIMA e de outros modelos, incluindo o GPT-4, o text-davinci-003 e o Google Bard. Segundo a Meta, os avaliadores humanos preferiram as respostas do LIMA em 43% das vezes em comparação com o GPT-4, em 200 exemplos. O LIMA superou o Google Bard em 58% das vezes e o text-davinci-003 em 65% das vezes. Todos esses modelos, exceto o LIMA, foram refinados com feedback humano.
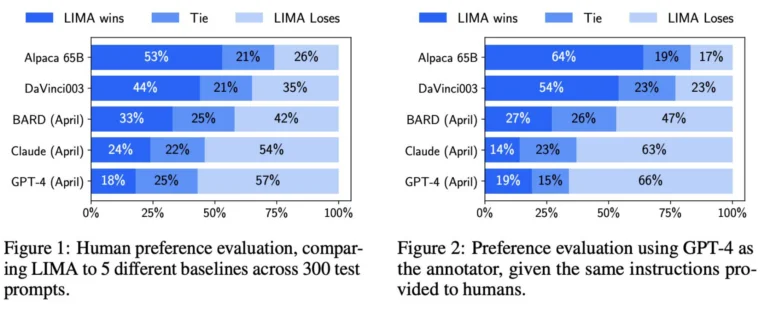
A equipe de pesquisa da Meta sugere que esses resultados indicam que um modelo de linguagem adquire grande parte de seu conhecimento por meio do pré-treinamento e que um ajuste fino relativamente limitado com alguns exemplos é suficiente para ensinar os modelos a gerar conteúdo de alta qualidade.
Como resultado, o treinamento extensivo com feedback humano usado pela OpenAI pode não ser tão importante como anteriormente se pensava. Esse é um ponto que a Meta destaca claramente em seu artigo de pesquisa.
A “Hipótese de Alinhamento Superficial”
A Meta define essa descoberta como a “hipótese de alinhamento superficial”. Ela sugere que a fase de alinhamento após o pré-treinamento se trata principalmente de ensinar ao modelo um estilo ou formato específico que ele pode lembrar ao interagir com os usuários.
Assim, o ajuste fino está mais relacionado ao estilo do que à substância. Isso contrasta com a prática comum de processos de ajuste fino especialmente extensos e complexos, como o RLHF da OpenAI.
A equipe de pesquisa da Meta identifica duas limitações do LIMA: Primeiro, construir conjuntos de dados com exemplos de alta qualidade é uma abordagem desafiadora que é difícil de escalar. Segundo, o LIMA não é tão robusto quanto os modelos que já estão disponíveis como produtos, como o GPT-4.
Segundo a equipe, o LIMA gera principalmente respostas boas, mas um “prompt adversarial” ou uma “amostra infeliz” podem resultar em respostas fracas. Ainda assim, o LIMA mostra que o problema complexo de alinhar e ajustar um modelo de IA pode ser resolvido com uma abordagem simples, segundo a equipe da Meta.
O chefe de pesquisa em IA da Meta, Yann LeCun, adota uma visão pragmática dessa desvalorização relativa do esforço por trás do GPT-4 e modelos similares: ele vê os grandes modelos de linguagem como um elemento do futuro próximo que não desempenhará um papel a curto prazo, pelo menos “sem mudanças significativas”.

Um comentário
Fala André, tudo bem?
Muito bom o conteúdo. Parabéns.
Queria tirar uma dúvida com você. Nas imagens, temos dados de “empate” e pelo que entendi no seu texto, você jogou esse parâmetro pro lado do LIMA. Tem algum motivo pra isso? Ou os dados do parágrafo quinto não fazem alusão à imagem abaixo do respectivo parágrafo?
Na imagem, diz que foram 300 prompts, e no seu texto, informa 200. Fiquei um pouco confuso aqui.
Abcs,