
Avec LIMA, les chercheurs en IA de Meta présentent un nouveau modèle linguistique qui atteint des performances équivalentes à GPT-4 et Bard dans les scénarios de test, bien qu’il soit réglé avec relativement peu d’exemples.
LIMA est l’acronyme de « Less is More for Alignment », et le nom suggère la fonction du modèle : montrer qu’avec un modèle d’IA largement pré-entraîné, peu d’exemples suffisent pour obtenir des résultats de haute qualité.
dans ce cas, « peu d’exemples » signifie que Meta a sélectionné manuellement 1 000 invites diverses et leurs résultats à partir de sources telles que d’autres articles de recherche, WikiHow, StackExchange et Reddit.
L’équipe a ensuite utilisé ces exemples pour améliorer son propre modèle LLaMA, avec 65 milliards de paramètres, qui a fait l’objet d’une fuite plus tôt et a alimenté le mouvement des modèles de langage open source. Meta a évité le coûteux RLHF, qu’OpenAI utilise pour affiner ses modèles et qu’elle considère comme un élément important de l’avenir de l’IA.
Le style plutôt que la substance
Meta a demandé à des êtres humains de comparer les résultats de LIMA et d’autres modèles, notamment GPT-4, text-davinci-003 et Google Bard. Selon Meta, les évaluateurs humains ont préféré les réponses de LIMA à celles de GPT-4 dans 43 % des cas, sur 200 exemples. LIMA a surpassé Google Bard dans 58 % des cas et text-davinci-003 dans 65 % des cas. Tous ces modèles, à l’exception de LIMA, ont été affinés à l’aide de commentaires humains.
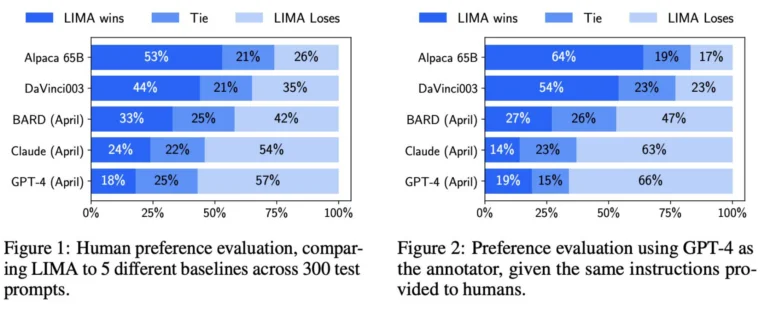
Selon l’équipe de recherche Meta, ces résultats indiquent qu’un modèle linguistique acquiert une grande partie de ses connaissances par le biais d’un pré-entraînement et qu’une mise au point relativement limitée avec quelques exemples suffit pour enseigner aux modèles à générer un contenu de haute qualité.
Par conséquent, l’entraînement intensif avec des commentaires humains utilisé par l’OpenAI n’est peut-être pas aussi important qu’on le pensait. C’est un point sur lequel Meta insiste clairement dans son document de recherche.
L’hypothèse de l’alignement de surface
Meta définit cette découverte comme l' »hypothèse de l’alignement de surface ». Elle suggère que la phase d’alignement après le pré-entraînement consiste principalement à enseigner au modèle un style ou un format spécifique dont il peut se souvenir lorsqu’il interagit avec les utilisateurs.
La mise au point est donc plus une question de style que de fond. Cela contraste avec la pratique courante des processus de mise au point particulièrement étendus et complexes, tels que le RLHF d’OpenAI.
L’équipe de recherche de Meta identifie deux limites de LIMA : premièrement, la constitution d’ensembles de données avec des exemples de haute qualité est une approche difficile à mettre à l’échelle. Deuxièmement, LIMA n’est pas aussi robuste que les modèles déjà disponibles en tant que produits, tels que GPT-4.
Selon l’équipe, LIMA génère la plupart du temps de bonnes réponses, mais un « message contradictoire » ou un « échantillon malheureux » peut entraîner de mauvaises réponses. Néanmoins, LIMA montre que le problème complexe de l’alignement et de l’ajustement d’un modèle d’IA peut être résolu par une approche simple, selon l’équipe de Meta.
Yann LeCun, responsable de la recherche en IA chez Meta, adopte un point de vue pragmatique sur cette dévaluation relative de l’effort derrière le GPT-4 et les modèles similaires : il considère les grands modèles de langage comme un élément du futur proche qui ne jouera pas de rôle à court terme, du moins « sans changements significatifs ».
