
Pesquisadores da Sakana AI apresentaram o Text-to-LoRA (T2L), um método que adapta grandes modelos de linguagem para novas tarefas utilizando apenas uma descrição textual simples – sem necessidade de dados de treinamento adicionais.
Grandes modelos de linguagem normalmente são especializados utilizando técnicas como o LoRA (Low-Rank Adaptation). O LoRA funciona através da inserção de pequenas matrizes de baixo escalonamento em determinadas camadas do modelo, tornando o processo de adaptação muito mais eficiente do que um ajuste completo. Em vez de atualizar bilhões de parâmetros, apenas alguns milhões necessitam de modificação.
No entanto, cada nova tarefa geralmente exige seus próprios dados de treinamento e hiperparâmetros cuidadosamente ajustados, tornando o processo demorado e intensivo em recursos. O Text-to-LoRA automatiza essa etapa. O sistema utiliza uma hiper-rede treinada em 479 tarefas do Super Natural Instructions Dataset. Ao aprender a conectar descrições de tarefas às configurações corretas do LoRA, o T2L consegue gerar os pesos para o LoRA de uma nova tarefa em apenas uma etapa – mesmo que jamais tenha encontrado essa tarefa antes.
A Sakana AI desenvolveu três variantes do T2L: a T2L-L (55 milhões de parâmetros), que gera ambas as matrizes do LoRA simultaneamente; a T2L-M (34 milhões de parâmetros), que compartilha uma camada de saída para ambas; e a T2L-S (5 milhões de parâmetros), que gera apenas as classificações individuais das matrizes.
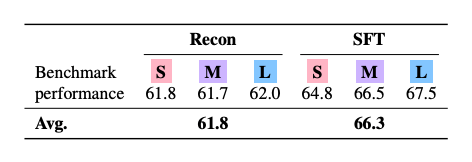
A equipe comparou duas abordagens de treinamento para o T2L: o treinamento por reconstrução, no qual o sistema aprende a recriar adaptadores LoRA já existentes, e o ajuste fino supervisionado (SFT), onde o modelo é treinado diretamente nas tarefas-alvo. Os modelos SFT tiveram melhor desempenho, alcançando em média 66,3% do benchmark de referência, frente a 61,8% dos modelos baseados em reconstrução. Os pesquisadores atribuem essa vantagem à capacidade do SFT de agrupar tarefas semelhantes de forma mais eficaz.
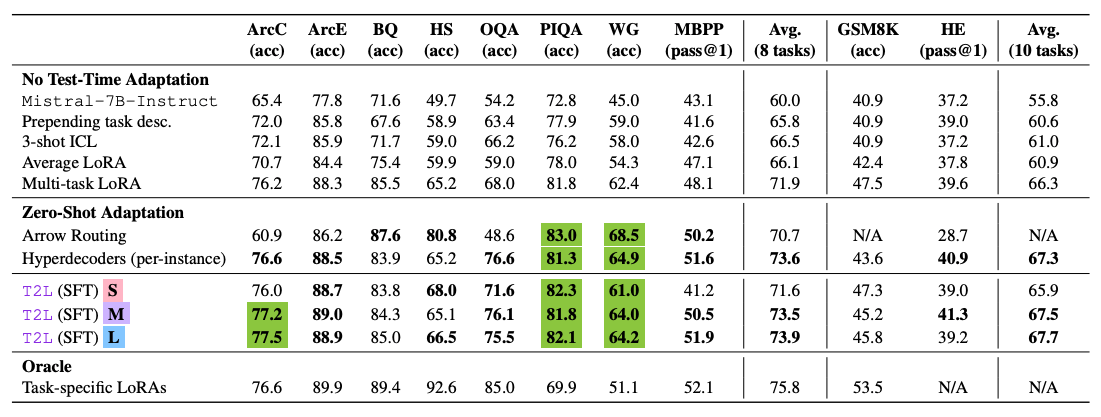
Em testes realizados em dez benchmarks padrão, o melhor modelo T2L alcançou uma performance média de 67,7%. Em uma comparação direta envolvendo oito benchmarks, o T2L obteve 74,0%, ficando apenas atrás dos adaptadores LoRA específicos para cada tarefa, que alcançaram 75,8% – cerca de 98% do desempenho de referência, mas sem a necessidade de um treinamento adicional.
Adaptando para Tarefas Desconhecidas
O T2L é capaz de lidar com tarefas completamente novas, superando linhas de base de LoRA multi-tarefas e outros métodos. Contudo, seu desempenho depende de quão próximo a nova tarefa está dos dados utilizados no treinamento – quanto maior essa correspondência, melhores os resultados.
Descrições claras e focadas na tarefa proporcionam resultados comparáveis aos dos adaptadores especializados, enquanto descrições vagas resultam em desempenho inferior.

De acordo com o estudo, o T2L é altamente eficiente, exigindo mais de quatro vezes menos operações computacionais do que o ajuste completo e dispensando dados de treinamento específicos para a tarefa. Além disso, o método funcionou de maneira confiável com modelos como o Llama-3.1-8B e o Gemma-2-2B.
Apesar de apresentar algumas limitações – como sua sensibilidade à redação do prompt e um desempenho inferior aos adaptadores LoRA especializados em tarefas complexas e fora do escopo dos dados de treinamento – os pesquisadores veem o T2L como um avanço significativo rumo à adaptação automatizada de modelos.
O código e as instruções de instalação estão disponíveis no GitHub.
