
Mistral apresenta o Voxtral: modelo open-source de compreensão de voz com custos reduzidos
A empresa francesa de inteligência artificial Mistral revelou o Voxtral, um modelo open-source de compreensão de voz que promete substituir soluções proprietárias por menos da metade do custo. O Voxtral vem em duas versões: uma variante de 24B para aplicações de produção e um modelo compacto de 3B para implantações locais e em dispositivos de borda. Ambos suportam uma janela de contexto de 32.000 tokens, permitindo o processamento de arquivos de áudio de até 30 minutos para transcrição ou 40 minutos para tarefas de compreensão.
Diferentemente das ferramentas básicas de transcrição, o Voxtral integra funcionalidades de perguntas e respostas (Q&A) e sumarização, sem a necessidade de modelos separados de reconhecimento de voz e linguagem. Além disso, permite que os usuários acione funções de backend por meio de comandos de voz, convertendo automaticamente as solicitações faladas em chamadas para APIs.
O modelo suporta reconhecimento automático de fala em inglês, espanhol, francês, português, hindi, alemão, holandês e italiano, mantendo a capacidade de compreensão textual herdada do backbone do Mistral Small 3.1.
Desempenho em benchmarks que supera a concorrência
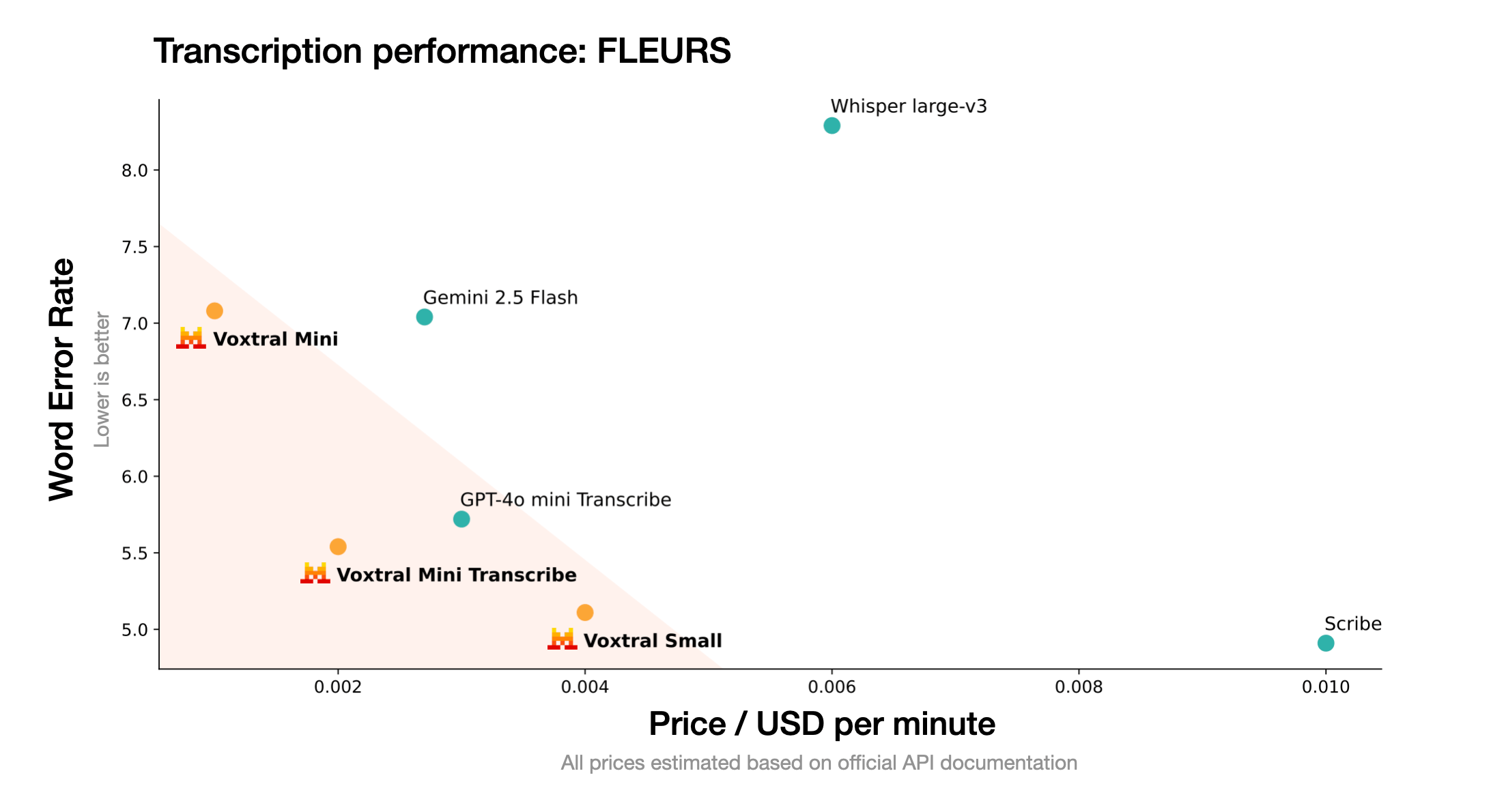
Em seus testes, a Mistral demonstrou que o Voxtral Small supera modelos open-source líderes, como o Whisper large-v3, além de competir de igual para igual com o GPT-4o mini Transcribe e o Gemini 2.5 Flash em todas as tarefas avaliadas. Em tarefas de curta duração em inglês e no benchmark Mozilla Common Voice, o Voxtral conseguiu superar o ElevenLabs Scribe, considerado um dos melhores do mercado.
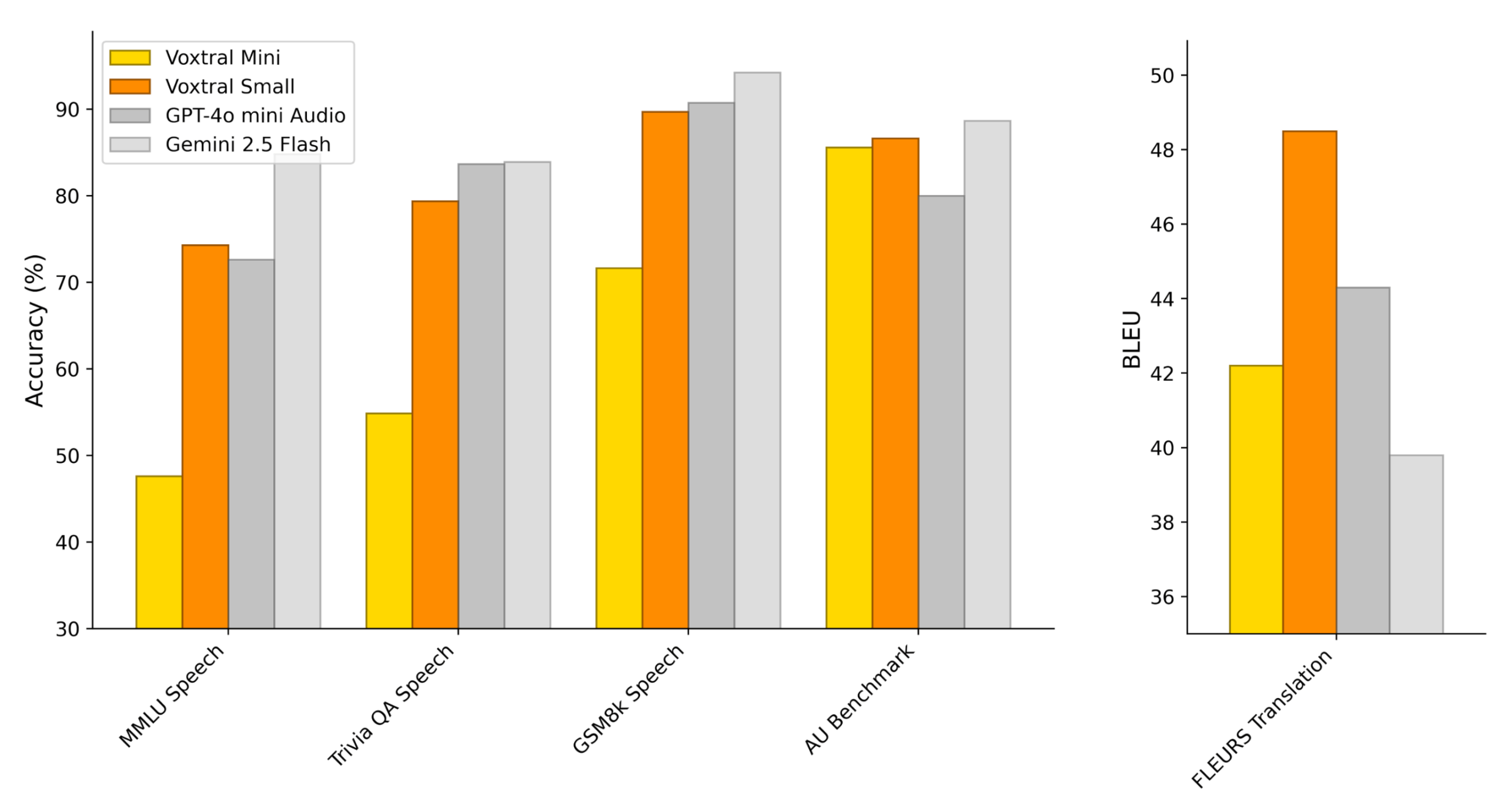
Segundo os benchmarks da Mistral, o Voxtral consegue acompanhar modelos significativamente maiores, como o GPT-4o mini e o Gemini 2.5 Flash. No benchmark multilingue FLEURS, focado em reconhecimento de fala, o Voxtral Small alegadamente supera o Whisper em todas as nove línguas testadas. Para tarefas de compreensão auditiva, o desempenho é comparável aos de outros modelos de ponta, entregando resultados excepcionais na tradução de áudio.
Preços econômicos que desafiam alternativas proprietárias
A Mistral posiciona o Voxtral como uma opção acessível, com preços de API a partir de US$0,001 por minuto. A empresa afirma que o Voxtral Mini Transcribe oferece desempenho superior ao Whisper, da OpenAI, a menos da metade do custo para aplicações sensíveis a preços, enquanto o Voxtral Small equilibra custos e desempenho de maneira semelhante ao ElevenLabs Scribe. Recursos empresariais incluem opções de implantação privada para setores regulados e a possibilidade de ajustes finos específicos para cada domínio. Atualizações futuras devem incorporar segmentação de locutores, marcações de áudio para detecção de idade e emoções, além de marcações temporais a nível de palavra.
Chegada ao Modo de Voz do Le Chat
Tanto a versão 24B quanto a 3B do Voxtral estão disponíveis para download sob a licença Apache-2.0 na Hugging Face, com acesso via API oferecido pela Mistral. Os modelos serão integrados ao Modo de Voz do Le Chat, que será lançado para todos os usuários nas próximas semanas.
Resumo
- A empresa francesa de IA Mistral lançou o Voxtral, um modelo open-source de compreensão de voz que integra transcrição e interpretação de áudio, com funcionalidades de perguntas e respostas e sumarização sem necessidade de modelos separados.
- Disponível em duas versões — um modelo de 24B para produção e uma versão compacta de 3B — o Voxtral supera concorrentes líderes, como o Whisper large-v3 e o ElevenLabs Scribe, em diversos benchmarks, oferecendo suporte em oito idiomas e resultados avançados em tradução e compreensão de áudio.
- Com preços significativamente inferiores às alternativas proprietárias, o Voxtral também oferece opções de implantação privada e, em breve, integrará o Modo de Voz do Le Chat, estando disponível para download sob licença Apache-2.0 e com acesso via API.
