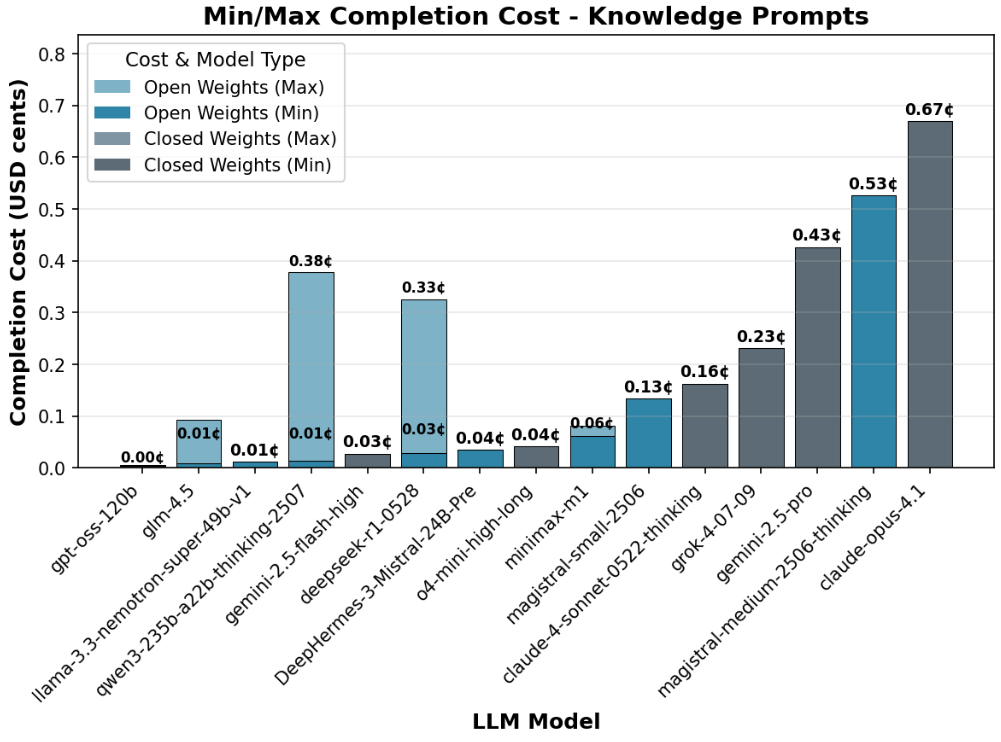
Maior consumo de tokens pode reduzir a eficiência dos modelos de raciocínio abertos
Modelos de raciocínio de peso aberto costumam utilizar muito mais tokens do que os modelos fechados, o que os torna menos eficientes por consulta, segundo a Nous Research. Modelos como DeepSeek e Qwen utilizam de 1,5 a 4 vezes mais tokens que aqueles da OpenAI e do Grok-4 — podendo chegar a usar até 10 vezes mais tokens em tarefas simples de conhecimento. Os modelos Magistral, da Mistral, se destacam pelo uso especialmente elevado de tokens.
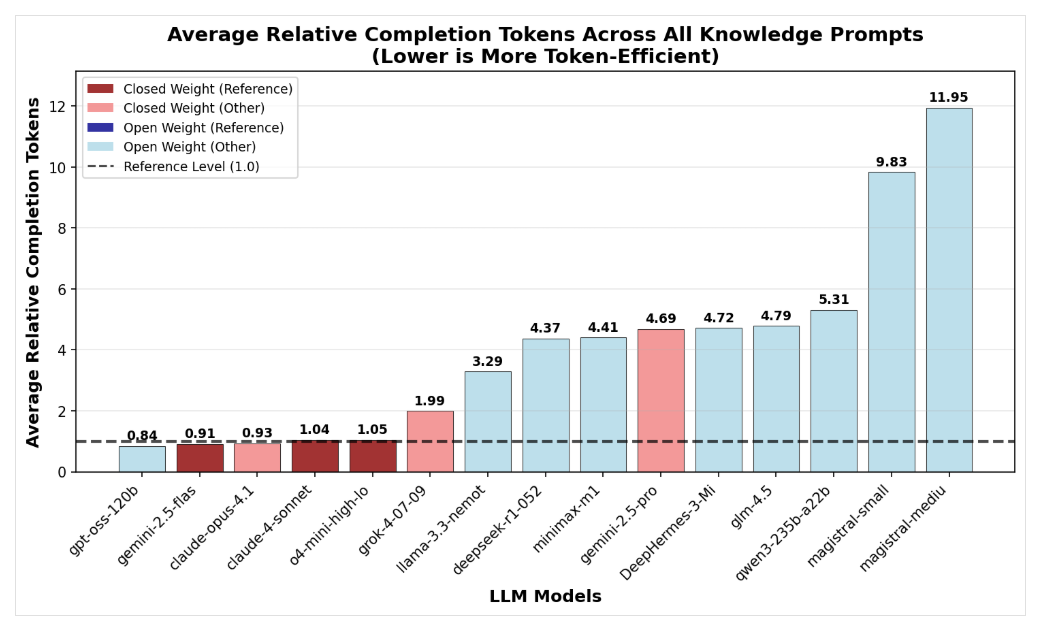
Em contraste, o modelo gpt-oss-120b da OpenAI, que apresenta trajetórias de raciocínio muito curtas, demonstra que os modelos abertos podem ser eficientes, especialmente na resolução de problemas matemáticos. O uso de tokens varia consideravelmente conforme o tipo de tarefa realizada. Para detalhes completos e gráficos, consulte a Nous Research.