
LongCat-Image prova que 6 bilhões de parâmetros podem superar modelos maiores com melhor higiene de dados
A empresa chinesa de tecnologia Meituan lançou o LongCat-Image, um novo modelo de imagens open-source que desafia a mentalidade de que “quanto maior, melhor”. Com apenas 6 bilhões de parâmetros, o modelo supostamente supera concorrentes significativamente maiores tanto em fotorealismo quanto na renderização de texto, graças à curadoria rigorosa dos dados e a uma abordagem inteligente para lidar com o texto.
Enquanto rivais como Tencent e Alibaba continuam ampliando seus modelos — sendo que o Hunyuan3.0 reúne até 80 bilhões de parâmetros — a Meituan optou por seguir o caminho oposto. A equipe ressalta que a escalabilidade forçada só desperdiça hardware sem, de fato, melhorar a qualidade visual das imagens. Em vez disso, o LongCat-Image utiliza uma arquitetura similar à popular Flux.1-dev, construída a partir de um Transformer de Difusão Multimodal híbrido (MM-DiT).
O sistema processa dados de imagem e texto por meio de dois “caminhos de atenção” separados nas camadas iniciais, que se fundem posteriormente. Essa estratégia permite que o comando textual exerça um controle mais preciso sobre a geração das imagens, sem elevar a carga computacional.
Limpeza dos dados de treinamento elimina o aspecto “plástico”
Um dos maiores problemas apontados pelos pesquisadores das IAs de imagens atuais é o treinamento com dados contaminados. Quando os modelos aprendem a partir de imagens geradas por outras IAs, acabam adquirindo uma textura “plástica” ou “gordurosa”, aprendendo atalhos em vez de capturar a complexidade do mundo real.
A solução adotada pela equipe foi simples, porém agressiva: eliminar todo o conteúdo gerado por IA do conjunto de dados durante as fases de pré-treinamento e treinamento intermediário. De modo similar, a Alibaba utilizou essa abordagem com o Qwen-Image, permitindo a reinserção — somente na etapa final de ajuste fino — de dados sintéticos cuidadosamente selecionados.
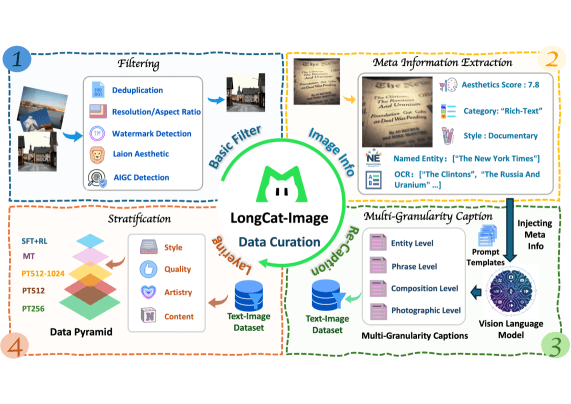
A pipeline de preparação de dados, dividida em quatro etapas, filtra o conteúdo sintético e utiliza modelos de linguagem visual para criar descrições detalhadas das imagens.
Além disso, os desenvolvedores implementaram uma técnica inovadora de aprendizado por reforço: um modelo de detecção que penaliza o gerador sempre que identifica artefatos próprios de IA. Essa abordagem incentiva o LongCat-Image a criar texturas realistas o suficiente para enganar o detector.
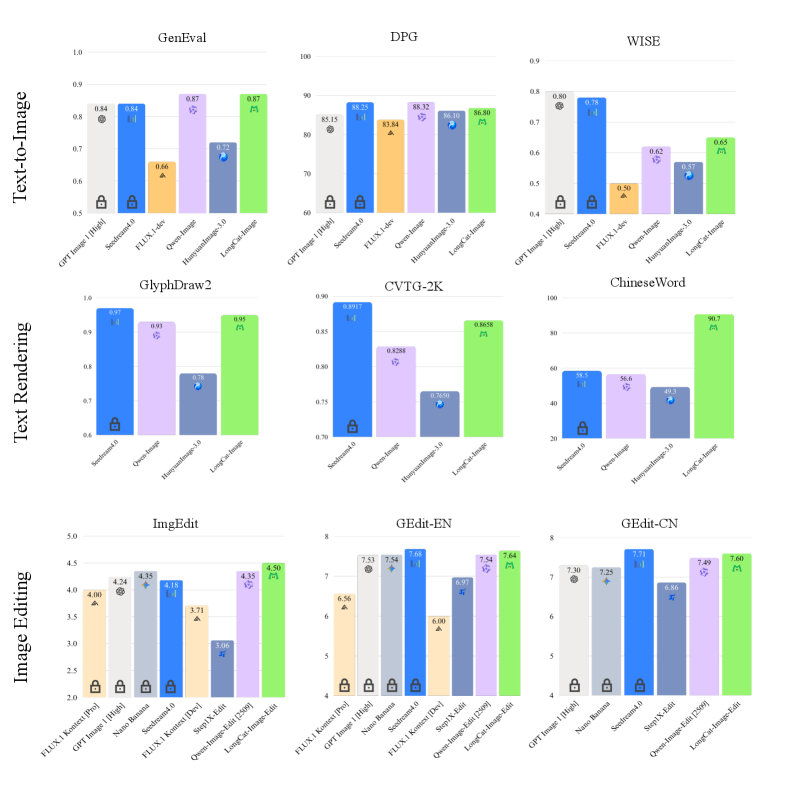
Em testes comparativos, o modelo de 6 bilhões de parâmetros supera consistentemente modelos muito maiores, como o Qwen-Image-20B e o HunyuanImage-3.0. Por ser extremamente eficiente, ele também requer menos VRAM, o que é vantajoso para quem deseja executá-lo localmente.
Processamento letra por letra garante precisão na renderização de textos
Um dos trunfos do LongCat-Image é a forma como ele lida com o texto presente nas imagens. A maioria dos modelos falha na ortografia ao tratar as palavras como tokens abstratos, em vez de identificar letras individuais. Para contornar essa limitação, o LongCat-Image adota uma abordagem híbrida: utiliza o Qwen2.5-VL-7B para compreender o comando geral, mas, ao identificar texto entre aspas, alterna para um tokenizador em nível de caracteres. Assim, o modelo constrói o texto letra por letra, em vez de depender da memorização de padrões visuais para cada palavra.

Modelo de edição separado mantém a qualidade das imagens
Em vez de concentrar todas as funções em um único sistema, a equipe desenvolveu uma ferramenta independente denominada LongCat-Image-Edit. Durante o treinamento, os dados sintéticos específicos para edição demonstraram degradar a qualidade fotorealística do modelo principal, o que levou à criação deste módulo separado.

O modelo dedicado à edição é capaz de lidar com tarefas complexas como transferências de estilo, inserção de objetos mantendo a perspectiva correta e a substituição completa de elementos. Parte de um ponto intermediário do treinamento, onde o sistema ainda é flexível para adquirir novas habilidades, o modelo aprende a seguir instruções sem comprometer a naturalidade das imagens.

A Meituan disponibilizou os pesos de ambos os modelos no GitHub e no Hugging Face, além dos pontos de verificação do treinamento intermediário e do código completo da pipeline de treinamento.
Resumo
- A Meituan lançou o LongCat-Image, um modelo de imagem open-source compacto com 6 bilhões de parâmetros que supera modelos maiores em termos de precisão na renderização de textos e fotorealismo.
- Esse desempenho é alcançado por meio de uma rigorosa filtragem de imagens geradas por IA durante o treinamento, aliado a um método especializado de codificação de texto que processa as letras individualmente, penalizando artefatos artificiais.
- Além do modelo de geração, foi lançado um módulo separado para edição de imagens, bem como disponibilizado o código completo da pipeline de treinamento.
