
その結果、適切なインセンティブがあれば、GPT-4は「心の理論」テストで申し分のない成績を収めることがわかった。哲学的な理論によって、大規模な言語モデルがどのようにして「心を読む」ことを学習するかを説明することができる。
ジョンズ・ホプキンス大学の研究チームは、GPT-4とGPT-3.5の3つのバリエーション(Davinci-2、Davinci-3、GPT-3.5-Turbo)の、いわゆる偽解釈テストにおけるパフォーマンスを研究した。
この種のテストでは、発達心理学や行動生物学が、人間や動物が他の生 物に誤った信念を帰する能力を調べる。
誤信念テストの例
シナリオ:ラリーは金曜日に提出する宿題の討論テーマを選んだ。木曜日のニュースでは討論が決着したと言っていたが、ラリー はそれを読んでいなかった。
質問:ラリーがエッセイを書くとき、討論は決着したと思いますか?
このような質問に答えるには、シナリオ中の行為者の知識や目標などの精神状態を追跡する能力が必要である。子どもは通常4歳頃にこの能力を獲得し、自分自身や他者に願望や信念を帰属させることができる。こうしたテストに合格すると、科学者は通常、こうした「心を読む」能力を与える「心の理論」(ToM)を与える。
テストの結果、研究チームは、ほとんどすべてのケースで、いくつかの例を与え、段階的に考えるように指示することで、OpenAIモデルの精度が80%以上に向上することを示すことができた。例外はDavinci-2モデルで、人間のフィードバックによる強化学習(RLHF)で訓練されていない唯一のモデルだった。
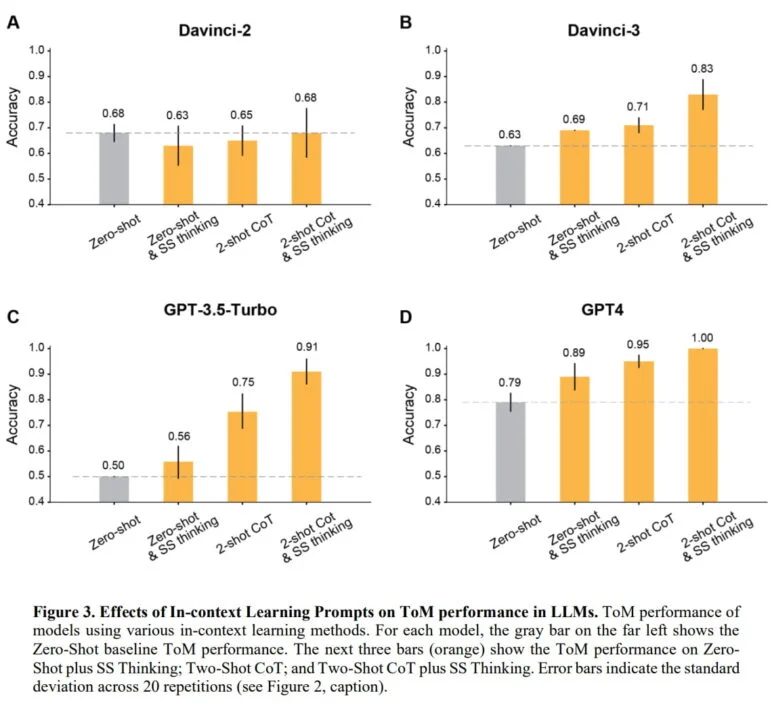
GPT-4が最も良い結果を出した。例なしでは、このモデルはほぼ80%のToM精度を達成し、例と推論指示があれば100%の精度を達成した。人間が時間的プレッシャーの中で応答しなければならない比較テストでは、人間の精度は約87%であった。
人間のフィードバックによる強化学習による心の理論?
このようなToMシナリオを確実に処理するGPTモデルの能力は、一般的な人間、特に社会的なコンテクストにおいて、関係する人間の精神状態を考慮することで恩恵を受ける可能性のあるモデルを処理するのに役立つ、と研究チームは述べている。さらに、これらのシナリオには推論が含まれることが多く、文脈から推測するしかない情報もあり、直接観察することはできない。「したがって、ToMタスクにおけるこれらのモデルの習熟度を評価し、向上させることは、推論を必要とする幅広いタスクにおけるモデルの可能性について、貴重な洞察を与える可能性があります」と、論文には書かれている。
そして実際に、情報が欠落しているToM以外のシナリオを用いたテストでは、研究チームは、RLHFモデルの推論の精度が、例を用いて段階的に考えるように指示することで向上することを示すことができ、GPT-4は100%の精度を達成した。興味深いことに、Davinci-2モデルは、本来はうまくいくのだが、98パーセントを達成し、コンテキスト学習で精度が落ちる。研究チームは、ToM能力はRLHFによって強く決定されると理論化している。
GPT-4は心の理論を持っているのか?
GPT-4は心の理論を持っているのだろうか?幼児が偽信念テストに合格する能力の根底にあるものは何かという問題も広く議論されているように、単純な答えはおそらく出せない。しかし、そこで議論されている理論、例えば理論理論や シミュレーション理論は、少なくとも私たちのToMが生物学的な遺伝であるという点では一致している。
2008年、アメリカの哲学者ダニエル・D・ハットは『大衆心理学の物語:理由を理解する社会文化的基礎』を出版した。彼の見解では、私たちのToMは主に、誤った信念の理解をより大きな説明の文脈で使う能力と動機によって特徴づけられる。
ハットによれば、心の理論とは誤った信念を推論する能力以上のものであり、「民間心理学」というあいまいな概念と密接な関係がある。彼の物語実践仮説(NPH)によれば、子どもは、人の行動を理由によって説明し予測する特別な形の物語実践に触れ、それに参加することによって心の理論を獲得する。
「NPHの中心的な主張は、理由があって行動する人々についての物語に直接出会うこと、つまり応答的な養育者によって対話的な文脈で提供される物語に直接出会うことが、(i)民間心理学の基本的な構造と、(ii)それを実践に適用するための規範に支配された可能性、つまりいつどのように使うかを学ぶことの両方に、子どもたちが慣れるための正常な経路である、ということです」とハットは言う。
民間心理学の語りの実践としての心の理論
つまり、ハットによれば、偽信念テストに合格することは、まだ「完全な」TeMの証ではない。ハットにとって、これはその人の文脈、歴史、性格を考慮しながら、物語の枠組みをその人に適用する実践的なスキルである。
「行動の理由を理解するためには、どのような信念や願望がその人の行動を動かしたかを知るだけでは不十分である。意図的な行動を理解するためには、文化的規範や、特定の人物の歴史や価値観の特殊性という観点から、文脈化される必要がある。
子どもたちがこうした高度なToMスキルを身につけるのは、誤信念テストから何年も経ってからだ–ハットによれば、まだ練習が足りないのだという。実践の場は成長期であり、おとぎ話、ノンフィクションの本、映画、ラジオ劇などを通してNPHの規範や形式を学び、物語を語ったり、他の子どもや大人と交流したりする中で実践する。
“模範としての役割を果たす民俗心理学的物語は、特定の行動が取られる通常の設定と、そうすることによる標準的な結果を子どもたちに慣れ親しませる。”しかしハットによれば、「この語り聞かせの活動から民間心理学の理解を得ることは、合理的な主体がさまざまな状況で何をする傾向があるかについて、厳格な規則や理論を学ぶようなものではない。
そうすることで、子どもたちは願望や信念を理解する能力を引き出しているのであり、この能力は、赤ん坊のうちにすでに明らかになっている意図性を理解する初期形態に基づいているとハットは主張している。ただし、ハットは間主観性を「他者に対する第一次的な知覚的感覚」と言い、「能動的な社会的知覚」に言及している。
私たちの心の理論はGPT-4に反映されているのだろうか?
訓練データの中にある多くの民間心理学の物語や、RLHFの訓練を通じて民間心理学の規範や形式が伝えられることによって、この実践がGPT-4や他のモデルに「感染」している可能性はある。いくつかのサンプルを学ぶことで、これらのスキルがRLHFのモデルに持ち込まれる。GPT-4は生物学的に受け継がれたToMを持っていない。この解釈では、モデルはToMスキルを含む特定の物語練習を学んだことになり、それが単純誤信念テストに現れる。
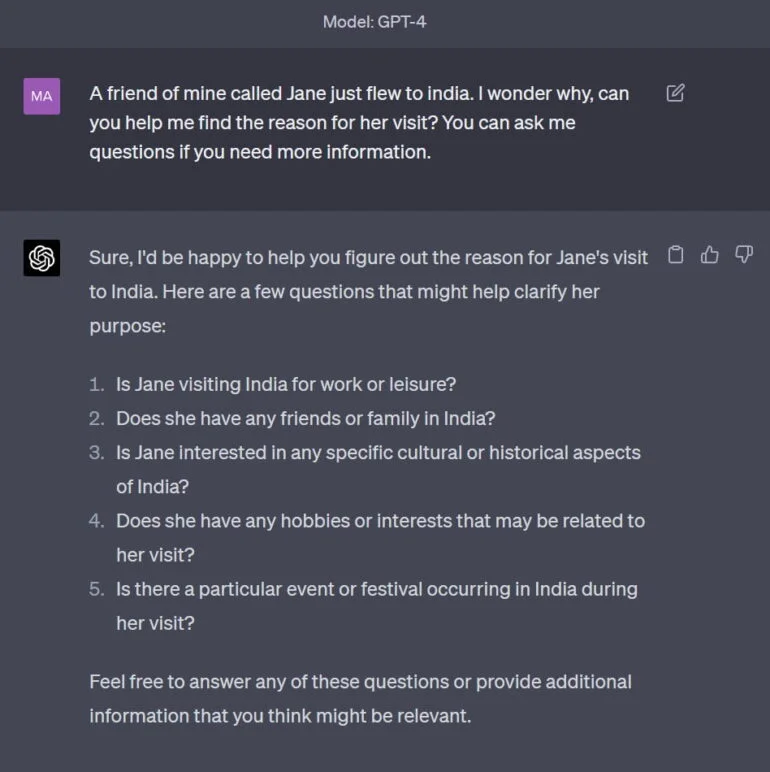
GPT-4がこの物語「ゲーム」をどの程度マスターしているかは、ハットの例にヒントを得た簡単な相互作用で説明できる。提案:「ジェーンという私の友人がインドに飛んでいきました。ジェーンがインドに行った理由を教えてください。もっと情報が必要なら私に質問してください。”
GPT-4は、ジェーンという人物と彼女の旅の背景についてもっと知りたいと、直接質問で応じる。
それに対して私は、確かにステレオタイプな情報をいくつか提供し、GPT-4はこの情報を使って、考えられる「民間心理学」の物語をいくつか挙げ始める。
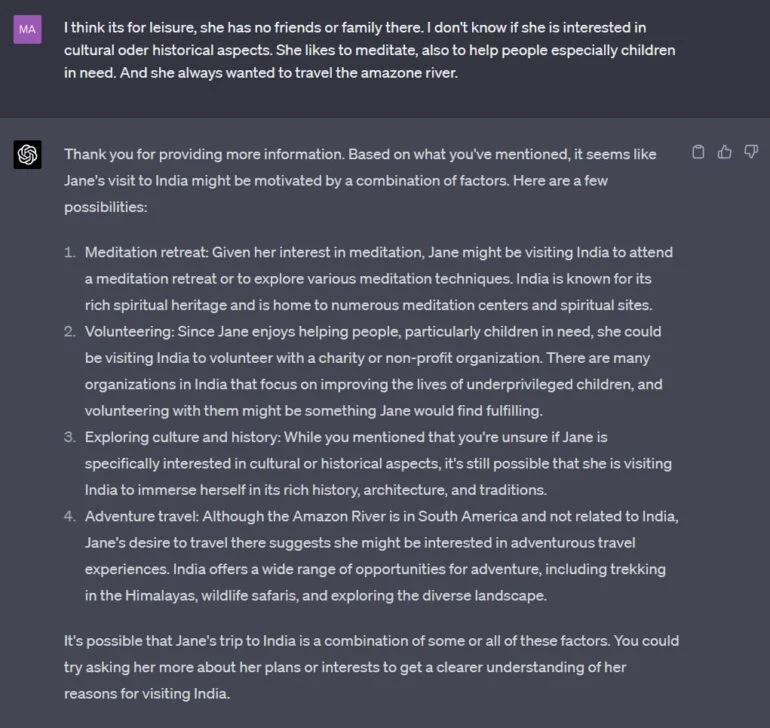
もちろん、これは一例に過ぎない。GPT-4の能力がどこまで「民間心理学」の語りの実践に及んでいるかを系統的な研究で示す必要があるだろう。
しかし、ジョンズ・ホプキンス大学の研究によれば、ハットのNPHは、なぜRLHFが言語モデルのToM能力にこれほど大きな影響を与えるのかの説明の一部を提供するかもしれない。
もっと深く掘り下げてハットの言っていることを本当に理解したいのであれば、彼の著書を読むか、以下にリンクされているエッセイのいくつかを読んでほしい。私の説明は省略されており、表象主義や実現主義に対する彼の立場など、理論-theoryのような代替案とは深いレベルで彼の思考を区別する重要なポイントがいくつか省略されているからだ。
内容はThe Decoderより。
