
DeepFloyd IFは、テキストを特にうまく扱うテキストから画像へのモデルで、基本的にはグーグルのImagenのオープンソース版である。
2022年5月、グーグルは当時リリースされたばかりのOpenAIのDALL-E 2を凌駕するテキスト画像変換モデルImagenのデモを行った。チームと示された例によると、このモデルはテキストから画像への合成精度と品質においてDALL-Eを上回った。また、画像の中にテキストを生成することもできた。これは、オープンソースのモデルではこれまでできなかったことである。
Stable Diffusionや DALL-E 2など、他の生成AIモデルと同様、Googleチームは、テキストプロンプトを埋め込みに変換し、拡散モデルによって画像にデコードされるフローズン・テキスト・エンコーダーに依存している。しかし、他のモデルとは異なり、Imagenはマルチモーダルに学習されたCLIPEではなく、大規模なT5-XXL言語モデルを使用している。研究チームは、実際に画像合成を担当する拡散モデルの訓練よりも、生成される画像の品質が言語モデルの大きさによってより向上することを示すことさえできた。
DeepFloyd IFはオープンソースのImagen
現在、StabilityAIに所属するDeepFloydチームは、このアーキテクチャを再現し、IFと呼ばれる一種のオープンソース画像をリリースした。同チームによると、IFはImagenの高い画像品質と言語理解能力を示しているという。IFは、LAION-5Bデータセットから約12億枚の画像で学習された。
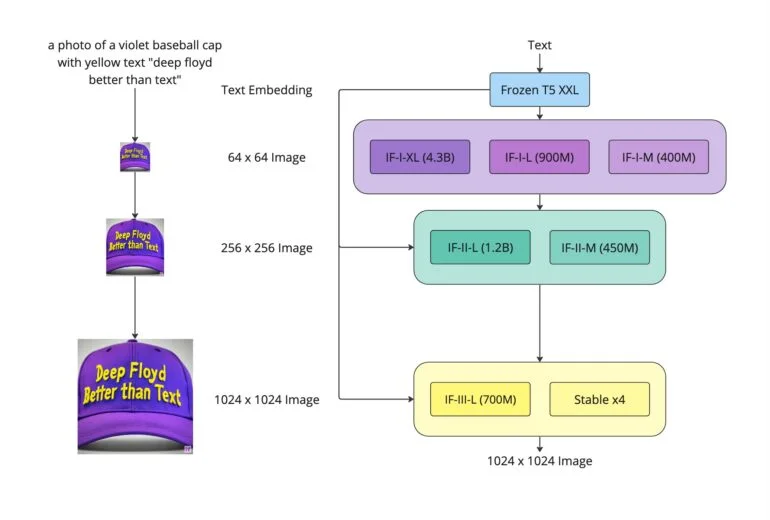
テストではGoogle Imagenを凌駕し、COCOデータセットでFIDゼロショットスコア6.66を達成。




チームによると、IFはImage-to-Image-TranslationとImpaintingもサポートしている。
Imagenと同様に、DeepFloyd IFは画像の解像度を1,024 x 1,024ピクセルに高める2つの超解像モデルを持ち、最大43億のパラメータを持つ異なるモデルサイズを提供する。1,024ピクセルのアップスケーラーを持つ最大モデルでは、チームは24ギガバイトのVRAMを推奨しているが、256ピクセルのアップスケーラーを持つ最大モデルでは、依然として16ギガバイトのVRAMが必要である。
DeepFloydが示すテキストから画像への合成の次のレベル
DeepFloyd社によると、この研究は、カスケード拡散モデルの最初の段階における、より大きなUNetアーキテクチャの可能性を示しており、したがって、テキストから画像への合成の有望な将来を示している。言い換えれば、DeepFloydのIFは、生成AIがさらに良くなる可能性を明確に示しており、オープンソースコミュニティが将来、GoogleのPartiのようなモデルを実現する可能性を示している。
IFモデルの最初のバージョンは、研究目的、言い換えれば非商用目的、つまりフィードバックを一時的に収集することのみを目的とした制限付きライセンスが適用される。このフィードバックが収集された後、DeepFloydとStabilityAIのチームは、商業的に互換性のあるバージョンを完全に無料でリリースする予定である。
DeepFloydのIFにはGithubがあり、デモはHuggingFaceで公開されている。詳細はDeepFloydのウェブサイトをご覧ください。
