
DeepFloyd IF es un modelo texto-imagen que maneja el texto especialmente bien y es básicamente una versión de código abierto de Imagen de Google.
En mayo de 2022, Google mostró Imagen, un modelo de texto a imagen que superaba a DALL-E 2 de OpenAI, que acababa de salir al mercado en ese momento. Según el equipo y los ejemplos mostrados, el modelo superaba a DALL-E en precisión y calidad de síntesis de texto a imagen. También era capaz de generar texto en imágenes, una capacidad que ningún modelo de código abierto había logrado hacer con fiabilidad.
Al igual que con otros modelos de IA generadores, como Stable Diffusion o DALL-E 2, el equipo de Google se basó en un codificador de texto congelado que convierte las indicaciones de texto en incrustaciones, que luego un modelo de difusión descodifica en una imagen. Sin embargo, a diferencia de otros modelos, Imagen no utiliza el CLIPE entrenado multimodalmente, sino el gran modelo de lenguaje T5-XXL. El equipo fue incluso capaz de demostrar que la calidad de las imágenes generadas aumenta más con el tamaño del modelo de lenguaje que con el entrenamiento del modelo de difusión, que es en realidad el responsable de la síntesis de imágenes.
DeepFloyd IF es Imagen de código abierto
Ahora, el equipo de DeepFloyd, afiliado a StabilityAI, ha replicado esta arquitectura y ha lanzado una especie de imagen de código abierto llamada IF. Según el equipo, IF demuestra la alta calidad de imagen y las capacidades de comprensión del lenguaje de Imagen. Se entrenó con alrededor de 1.200 millones de imágenes del conjunto de datos LAION-5B.
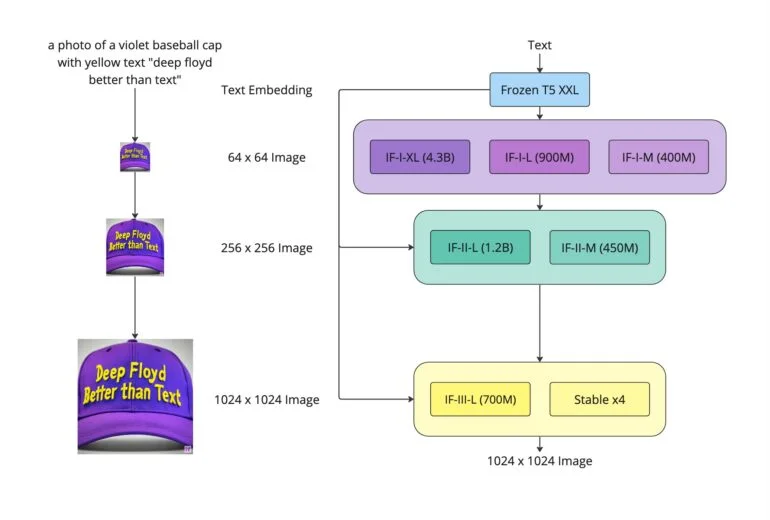
En las pruebas, incluso supera a Google Imagen, logrando una puntuación FID Zero-Shot de 6,66 en el conjunto de datos COCO, por delante también de otros modelos disponibles como Stable Diffusion.




Según el equipo, IF también admite la traducción de imagen a imagen y el impainting.
Al igual que Imagen, DeepFloyd IF dispone de dos modelos de superresolución que aumentan la resolución de las imágenes a 1.024 x 1.024 píxeles y ofrece diferentes tamaños de modelo con hasta 4.300 millones de parámetros. Para el modelo más grande con un escalador de 1.024 píxeles, el equipo recomienda 24 gigabytes de VRAM, mientras que el modelo más grande con un escalador de 256 píxeles sigue necesitando 16 gigabytes de VRAM.
DeepFloyd muestra el siguiente nivel de síntesis de texto a imagen
Según DeepFloyd, el trabajo muestra el potencial de las arquitecturas UNet de mayor tamaño en la primera fase de los modelos de difusión en cascada y, por tanto, un futuro prometedor para la síntesis de texto a imagen. En otras palabras, el IF de DeepFloyd muestra claramente que la IA generativa puede mejorar aún más y que la comunidad de código abierto podría lograr en el futuro modelos como el Parti de Google, que supera a Imagen en algunos aspectos.
La primera versión del modelo IF está sujeta a una licencia restringida, destinada únicamente a fines de investigación -es decir, no comerciales- para recoger temporalmente opiniones. Una vez recopilada esta retroalimentación, el equipo de DeepFloyd y StabilityAI lanzará una versión comercialmente compatible de forma totalmente gratuita.
El SI de DeepFloyd tiene un Github, una demo está disponible en HuggingFace. Más información en la web de DeepFloyd.

