
最近の調査によると、ChatGPTはオンラインでの問い合わせに答える際、医師の質と共感を上回ります。ただし、注意点もある。
JAMA Internal Medicine誌に掲載された最近の研究によると、ChatGPTはオンラインでの問い合わせに答える際、質と共感の点で医師を上回ることが明らかになった。この研究では、Redditのr/AskDocsフォーラムで患者からの質問に答える際のChatGPTのパフォーマンスを医師と比較して評価した。
無作為に選ばれた195の質問を対象とした横断的研究では、医師の回答よりもチャットボットの回答が好まれることがわかった。ChatGPTは、品質と共感において有意に高い評価を得た。
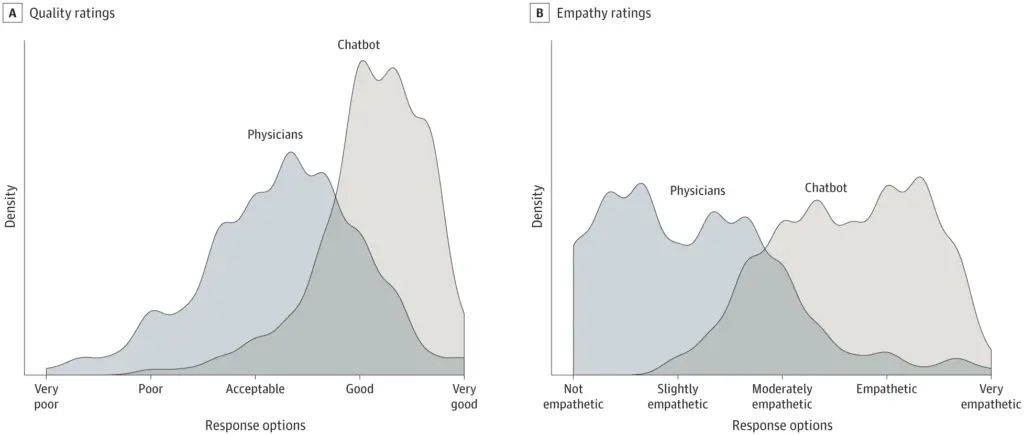
注目すべきは、この研究ではGPT3.5という古いバージョンを使用していることで、より最近のGPT-4のアップデートでさらに良い結果が得られる可能性が示唆されている。
チャットボットによる医師の補助
研究者らは、AIアシスタントが患者の質問に対する回答を考案する手助けをすることで、医師と患者の双方に利益をもたらす可能性があると書いている。医師が編集するための回答を作成するチャットボットの使用を含め、臨床現場におけるこの技術のさらなる探求が必要である。無作為化試験は、AIアシスタントが回答を改善し、医師の燃え尽きを減らし、患者の転帰を改善する可能性を評価することができる。
患者からの問い合わせに対する迅速で共感的な回答は、不必要な診療所の受診を減らし、リソースを解放することができる。メッセージングはまた、患者の公平性を促進するための重要なリソースであり、移動に制限のある人、不規則な仕事のスケジュールの人、医療費への不安のある人に有益である。
有望な結果にもかかわらず、この研究には限界がある。オンラインフォーラムでの質問は、患者と医師の典型的なやり取りを反映していない可能性があり、電子カルテからパーソナライズされた詳細を提供するチャットボットの能力は評価されていない。
さらに、この研究では、AIが生成する医療アドバイスで大きな懸念となる、チャットボットの回答の正確性や捏造された情報について評価していない。最終的なレビューのために人間が輪の中にいるときでさえ、ミスをしないようにするよりもミスを捕まえる方が難しいことがある。しかし、人間も間違いを犯すことを忘れてはならない。
著者らは、臨床現場におけるAIアシスタントの潜在的な影響を見極めるためには、より多くの研究が必要であると結論づけている。彼らは、AIが生成したコンテンツの正確性や、虚偽または捏造された情報の可能性について人間がレビューする必要性など、倫理的な懸念に対処することを強調している。
注目すべきは、ChatGPTは特に医療タスクに最適化されているわけではないということだ。グーグルは、医療用に強化された大規模言語モデルMed-PaLM 2を開発している。グーグルは、このモデルは医学的な精査をパスできると主張しており、専門家とのテストを開始する予定だ。
