
これまで、オープンソースモデルの品質を比較する簡単な方法はなかった。eスポーツにヒントを得たシステムが、その一助となるかもしれない。
Vicunaオープンソースモデルの責任者であるLarge Model System Organisation(LMSYS)は、大規模言語モデルのパフォーマンスを比較するためのベンチマークプラットフォーム「Chatbot Arena」を立ち上げた。さまざまなモデルが、匿名でランダムに選ばれた対戦相手と競い合う。ユーザーは、気に入った回答に投票することで、モデルのパフォーマンスを評価する。
これらの評価に基づいて、チェスや特にeスポーツで広く使用されているEloレーティングシステムに従ってモデルがランク付けされます。原則として、ユーザーはどのような質問もでき、長時間の会話も可能だが、モデルの名前を直接尋ねることはできない。
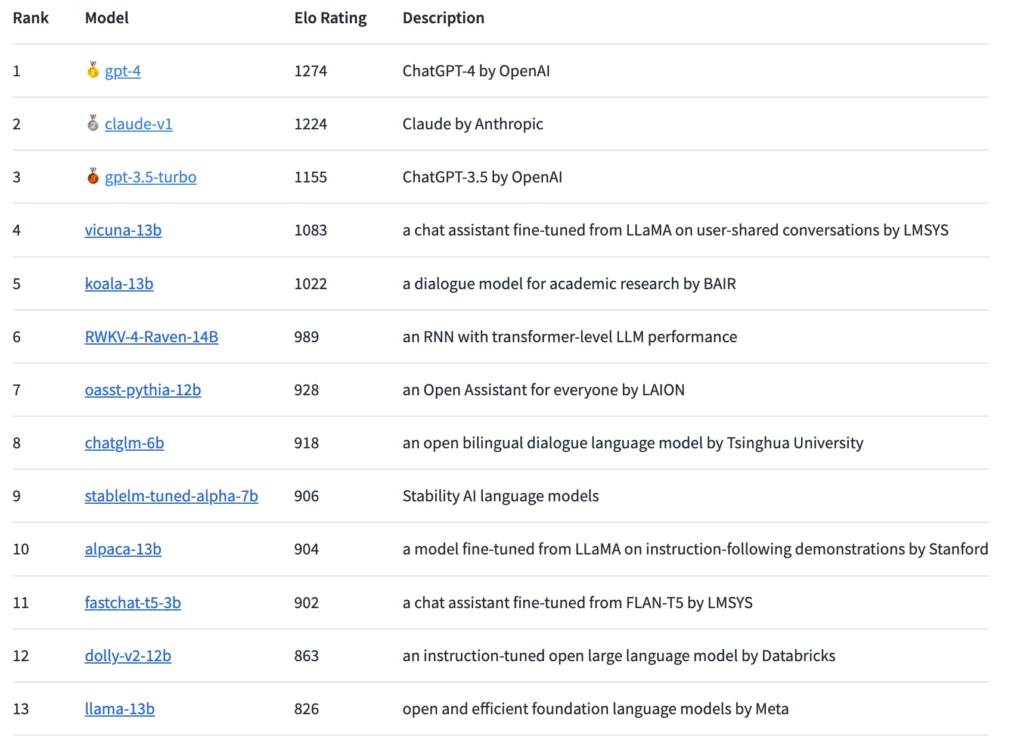
GPT-4が最高Eloを獲得するも、クロードが僅差で続く
この方法では、現在GPT-4がランキングトップで、僅差でClaude-v1とGPT-3.5-turboが続いている。オープンソースのモデルで最も順位が高いのはVicuna-13Bである。今後、研究者たちは、より多くのオープンソースとクローズドソースのモデルを統合し、ランキングをより正確に細分化することを計画している。
MetaのLLaMA言語モデルが流出して以来、ChatGPTのように、人間の指示に従い、チャットボットと同様の方法でユーザーの質問に答えるように設計されたオープンソースの言語モデルがいくつか登場している。しかし、これらのモデルを、特にオープンな質問に対して効果的に評価することは困難です。
チャットボット・アリーナ
ここで、Chatbot Arenaは有望なアプローチを提供する。大規模な言語モデルを評価するためのEloシステムは、すでにAnthropicによってClaudeの評価に使用されている。
アリーナでは、モデル同士が直接競争し、ユーザーはモデルとの対話によってベストモデルに投票する。プラットフォームはすべてのユーザーとのやりとりを収集するが、未知のモデルの名前とともに投票された票のみを使用する。LMSYSによると、開始から1週間後には約4,700件の有効な匿名投票が寄せられ、5月初めにはこの数は約13,000件にまで増加した。
LMSYS社によれば、これまでのところ、プロプライエタリ・モデルとオープンソース・モデルの間に「かなりのギャップ」が見られるという。しかし、オープンソース・モデルのパラメータ数は30億から140億と、かなり少ない。引き分けを除けば、GPT-4はVicuna-13Bに対して82%、GPT-3.5-turboに対しては79%の勝利を収めている。AnthropicのClaudeはアリーナでGPT-3.5を破り、GPT-4と互角に渡り合っている。
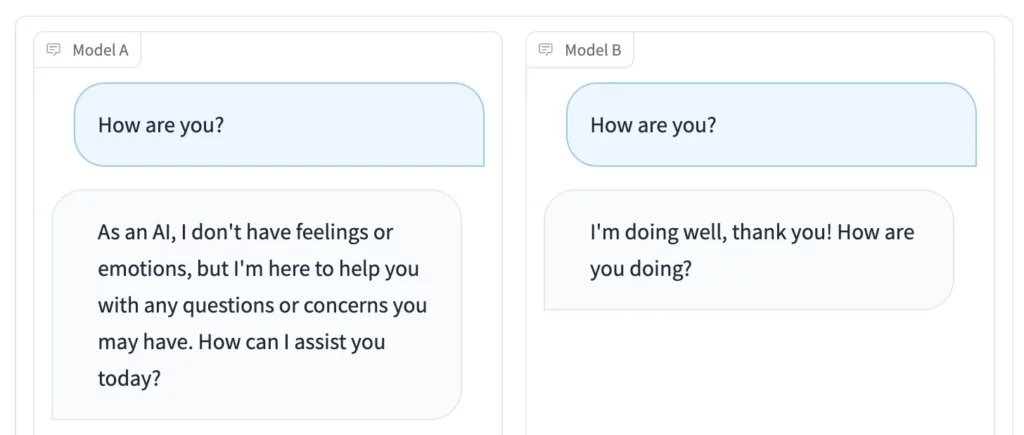
アリーナ競技に加えて、Side by Sideモードは特に便利です。個々のオープンソース言語モデルを選択し、同時に同じ刺激を与えることができます。結果はリアルタイムで比較することができます。
投票に参加したい場合、またはあなたにとって有用なオープンソース言語モデルを見つけたい場合は、チャットボット・アリーナにアクセスしてください。元GitHub CEOのNathaniel FriedmanによるPlaygroundプラットフォームも同様の仕組みだ。
