
Hasta ahora, no había una manera fácil de comparar la calidad de los modelos de código abierto. Un sistema inspirado en los e-sports podría ayudar.
La Organización del Sistema de Modelos Grandes (LMSYS), responsable del modelo de código abierto Vicuna, ha lanzado la plataforma de referencia «Chatbot Arena» para comparar el rendimiento de los grandes modelos de lenguaje. Diferentes modelos compiten entre sí en duelos anónimos y seleccionados al azar. Los usuarios luego clasifican el rendimiento de los modelos votando por sus respuestas preferidas.
Con base en esas clasificaciones, los modelos son clasificados según el sistema de clasificación Elo, ampliamente utilizado en el ajedrez y especialmente en los e-sports. En principio, los usuarios pueden hacer cualquier pregunta e incluso tener conversaciones largas, pero no pueden solicitar directamente el nombre del modelo, ya que esto descalificaría su voto para la clasificación.
El GPT-4 alcanza el Elo más alto, pero Claude está cerca
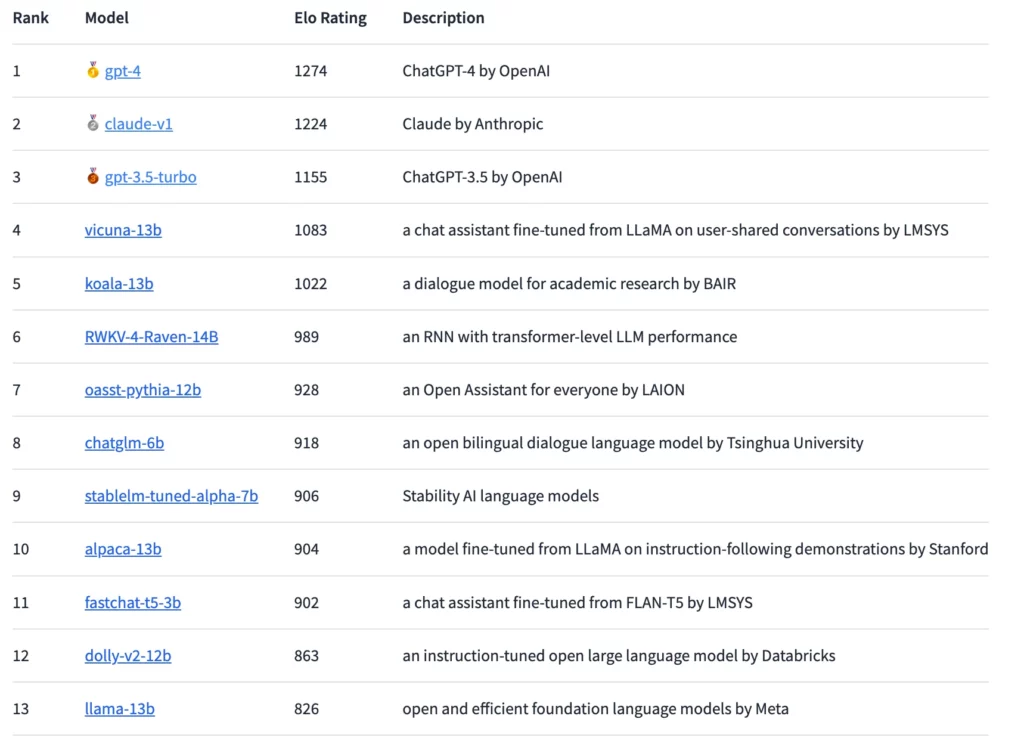
Utilizando este método, el GPT-4 actualmente lidera el ranking, seguido de cerca por el Claude-v1 y el GPT-3.5-turbo con una diferencia ligeramente mayor. El modelo de código abierto con la clasificación más alta es el Vicuna-13B. En el futuro, los investigadores planean integrar más modelos de código abierto y cerrado y detallar las clasificaciones de manera más precisa.
Desde la filtración del modelo de lenguaje LLaMA de Meta, han surgido varios modelos de lenguaje de código abierto que, al igual que el ChatGPT, están diseñados para seguir instrucciones humanas y responder preguntas de los usuarios de manera similar a un chatbot. Sin embargo, la dificultad radica en evaluar estos modelos de manera efectiva, especialmente para preguntas abiertas.
Entra en escena la Chatbot Arena
Aquí es donde la Chatbot Arena ofrece un enfoque prometedor. El sistema Elo para evaluar grandes modelos de lenguaje ya ha sido utilizado por Anthropic en la evaluación del modelo Claude.
En la arena, los modelos compiten directamente entre sí y los usuarios votan por el mejor modelo interactuando con ellos. La plataforma recopila todas las interacciones de los usuarios, pero solo utiliza los votos emitidos con los nombres de los modelos desconocidos. Según LMSYS, aproximadamente se recibieron 4.700 votos anónimos válidos una semana después del lanzamiento, y hasta principios de mayo, ese número había crecido a alrededor de 13.000.
Hasta ahora, los resultados muestran una «brecha sustancial» entre los modelos propietarios y de código abierto, según LMSYS. Sin embargo, los modelos de código abierto representados en la arena también tenían significativamente menos parámetros, que van desde tres mil millones hasta 14 mil millones. Excluyendo los empates, el GPT-4 gana el 82% de los duelos contra el Vicuna-13B y el 79% de los duelos contra el GPT-3.5-turbo. El modelo Claude de Anthropic supera al GPT-3.5 en la arena y está al mismo nivel que el GPT-4.
Además de la competencia en la Arena, el modo Side-by-Side es particularmente conveniente: puedes seleccionar modelos de lenguaje de código abierto individuales y alimentarlos con el mismo estímulo al mismo tiempo. Los resultados se pueden comparar en tiempo real.
Accede a la Chatbot Arena si deseas participar en la votación o encontrar un modelo de lenguaje de código abierto útil para ti. La plataforma Playground del ex CEO de GitHub, Nathaniel Friedman, funciona de manera similar.

