
BLIVAは、画像中のテキストを読み取ることに優れた視覚言語モデルであり、実世界のシナリオや様々な業界のアプリケーションに有用である。
カリフォルニア大学サンディエゴ校の研究者は、テキストを含む画像をよりうまく扱うように設計された視覚言語モデル、BLIVAを開発した。視覚言語モデル(VLM)は、画像に関する質問に答えるための視覚的理解能力を組み込むことで、大規模言語モデル(LLM)を拡張する。
これらのマルチモーダルモデルは、オープンエンドの視覚的質問と回答のベンチマークにおいて目覚ましい進歩を遂げている。その一例がOpenAIのGPT-4であり、マルチモーダルな形態では、ユーザーからのプロンプトに応じて画像コンテンツについて議論することができる。
しかし、現在のシステムの大きな限界は、実世界のシナリオで一般的なテキストを含む画像を扱う能力である。
InstructBLIPとLLaVAを組み合わせたBLIVA
この問題に対処するため、研究チームは「視覚アシスタント付きBLIP」の略であるBLIVAを開発した。すなわち、SalesforceのInstructBLIPに似た、テキスト入力に関連する画像の領域に焦点を当てるためのQ-formerモジュールによって抽出された学習クエリー埋め込みと、MicrosoftのLLaVA(Large Scale Language and Vision Assistant)に触発された、全画像の生のピクセルパッチから直接抽出された符号化パッチ埋め込みである。
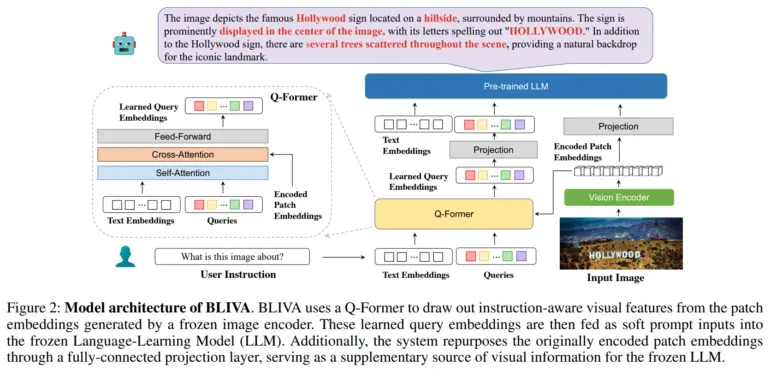
研究者らによると、この二重アプローチにより、BLIVAは、テキストに適応したクエリに基づく精緻な埋め込みと、視覚的な詳細を捉えるより豊かなパッチ埋め込みの両方を使用することができる。
BLIVAは、約55万組の画像とキャプションで事前に訓練され、視覚エンコーダーと言語モデルを凍結したまま、15万例の視覚的質問と回答でチューニングされている。
研究チームは、OCR-VQA、TextVQA、ST-VQAなどのデータセットにおいて、BLIVAがテキストリッチ画像の処理を大幅に改善することを実証した。例えば、OCR-VQAでは65.38%の精度を達成したのに対し、InstructBLIPでは47.62%であった。また、テキスト以外の視覚的な質問と回答に関する8つの一般的なベンチマークのうち7つで、新システムはInstructBLIPを上回った。研究チームは、これは一般的な視覚的理解における複数の埋め込みアプローチの利点を実証していると考えている。

研究チームはまた、Hugging Faceで公開されている、YouTube動画のサムネイルと関連する質問の新しいデータセットでBLIVAを評価した。BLIVAは92パーセントの精度を達成し、従来の方法よりもかなり高い精度を示した。BLIVAが道路標識や食品パッケージなどの画像中のテキストを読み取る能力を持つことで、様々な産業での実用化が可能になると研究チームは述べている。最近、マイクロソフトの研究者たちは、LLaVA-medと呼ばれる、LLaVAをベースにした生物医学用のマルチモーダルAIアシスタントのデモを行った。
詳細とコードはBLIVAのGithubで公開されており、デモはHugging Faceで見ることができる。
