
BLIVA est un modèle de langage visuel qui excelle dans la lecture de texte dans les images, ce qui le rend utile dans des scénarios et des applications du monde réel dans divers secteurs.
Des chercheurs de l’université de San Diego ont mis au point BLIVA, un modèle de langage visuel conçu pour mieux traiter les images contenant du texte. Les modèles de langage visuel (VLM) étendent les grands modèles de langage (LLM) en incorporant des capacités de compréhension visuelle pour répondre à des questions sur les images.
Ces modèles multimodaux ont fait des progrès impressionnants dans l’évaluation comparative des questions et réponses visuelles ouvertes. Un exemple est le GPT-4 d’OpenAI qui, dans sa forme multimodale, peut discuter du contenu d’une image à la demande d’un utilisateur, bien que cette capacité ne soit actuellement disponible que dans l’application « Be My Eyes ».
Cependant, l’une des principales limites des systèmes actuels est la capacité à traiter des images contenant du texte, ce qui est courant dans les scénarios du monde réel.
BLIVA combine InstructBLIP et LLaVA
Pour résoudre ce problème, l’équipe a mis au point BLIVA, qui signifie « BLIP avec assistant visuel ». BLIVA incorpore deux types complémentaires d’incrustations visuelles, à savoir les incrustations de requête apprises extraites par un module Q-former pour se concentrer sur les régions de l’image pertinentes pour l’entrée textuelle, similaires à InstructBLIP de Salesforce, et les incrustations de patch encodées extraites directement des patchs de pixels bruts de l’image complète, inspirées par LLaVA (Large Scale Language and Vision Assistant) de Microsoft.
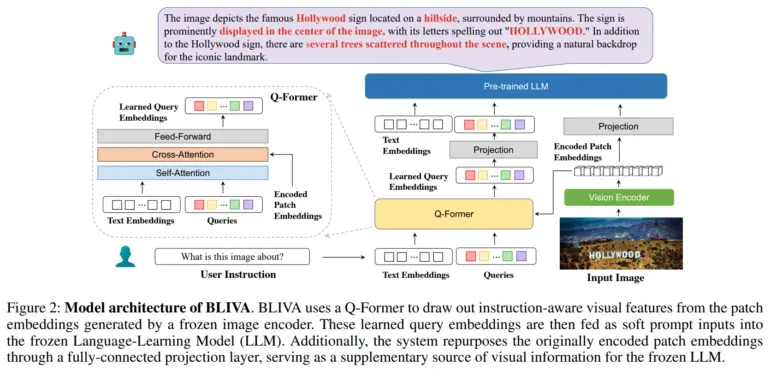
Selon les chercheurs, cette double approche permet à BLIVA d’utiliser à la fois des encastrements affinés basés sur des requêtes adaptées au texte et des encastrements de patchs plus riches qui capturent plus de détails visuels.
BLIVA a été pré-entraîné avec environ 550 000 paires d’images et de légendes, et a été ajusté avec 150 000 exemples de questions et de réponses visuelles, le codeur visuel et le modèle de langage restant figés.
L’équipe a démontré que BLIVA améliore considérablement le traitement des images riches en texte dans des ensembles de données tels que OCR-VQA, TextVQA et ST-VQA. Par exemple, elle a obtenu une précision de 65,38 % dans l’OCR-VQA, contre 47,62 % pour InstructBLIP. Le nouveau système a également surpassé InstructBLIP dans sept des huit points de référence généraux pour les questions et réponses visuelles non textuelles. L’équipe estime que cela démontre les avantages des approches d’intégration multiples pour la compréhension visuelle en général.

Les chercheurs ont également évalué BLIVA sur un nouvel ensemble de données de vignettes de vidéos YouTube avec les questions associées, disponibles sur Hugging Face. BLIVA a atteint une précision de 92 %, ce qui est nettement supérieur aux méthodes précédentes. La capacité de BLIVA à lire du texte dans des images, telles que des panneaux routiers ou des emballages alimentaires, pourrait permettre des applications pratiques dans diverses industries, a déclaré l’équipe. Récemment, les chercheurs de Microsoft ont fait la démonstration d’un assistant d’IA multimodal pour la biomédecine basé sur LLaVA, appelé LLaVA-med.
De plus amples informations et le code sont disponibles sur le Github de BLIVA, et une démo est disponible sur Hugging Face.

