
アレン人工知能研究所(AI2)は、Dolmaを発表しました。 これは、ウェブコンテンツ、科学論文、コード、書籍から収集された3兆トークンを持つオープンソースのデータセットです。 これは、これまで公に利用可能なこの種の最大のオープンソースデータセットです。
Dolmaは、現在AI2で開発中のオープン言語モデル(OLMo)の基盤です。 OLMoは2024年初頭にリリース予定であり、「最高のオープン言語モデル」を開発することを目指して、Dolma(OLMoを養うためのデータ)という広範なデータセットが作成されました。
Dolmaは現在、最大のオープンソースデータセットであり、Hugging Faceプラットフォームを介して開発者や研究者に利用可能です。 そこでは、研究者がそれを作成するために使用したツールも提供されており、結果の再現性が確保されています。
Dolmaは主に英語のデータで構成されています
Dolmaを作成するために、さまざまな情報源のデータがクリーンなテキストドキュメントに変換されました。
最初のバージョンでは、Dolmaは主に英語のテキストに制限されています。 言語認識モデルがデータをフィルタリングするために使用されました。 少数派の方言に対するバイアスを補償するために、チームはモデルが50%の信頼性で英語と分類したすべてのテキストを含めました。 将来のバージョンでは他の言語も含まれる予定です。

次の段階では、研究者たちは重複データ、低品質なコンテンツ、または機密情報をクリーンアップし、コードの例の品質を向上させました。
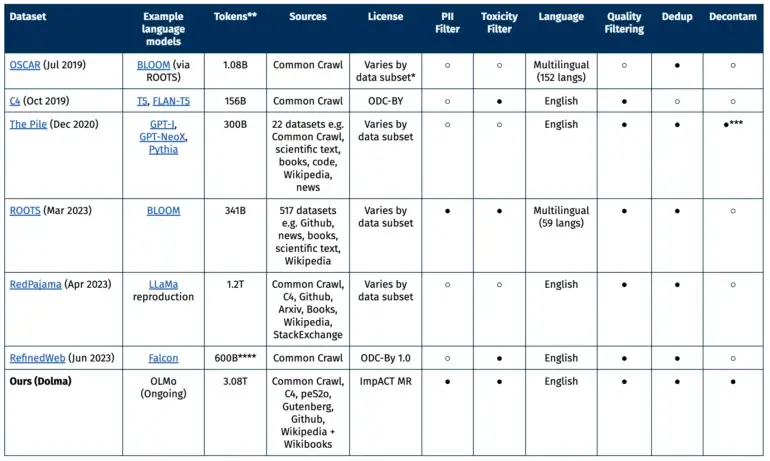
他のオープンデータセットとの比較
データの大部分は、ウェブのデータに焦点を当てた非営利のCommon Crawlプロジェクトから提供されています。 さらに、C4コレクションの他のウェブページ、peS20の学術的なテキスト、The Stackのコードスニペット、Project Gutenbergの本、および英語のWikipediaも含まれています。
AI2の見解では、理想的なデータセットは、いくつかの基準を満たす必要があります。 それはオープンであること、代表的であること、大きさがあること、再現性があることです。 また、特に個人に影響を及ぼす可能性のあるリスクを最小限に抑える必要があります。
以前の研究は、モデルのパラメータ数だけでなく、言語モデルのトレーニングデータの量も性能に重要な役割を果たすことを示しています。
Dolmaの提供とオープンソースの問題
このデータセットは、AI2のImpACTライセンスの下で、中程度のリスクのアーティファクトとしてリリースされます。 研究者は特定の要件を満たす必要があり、連絡先情報を提供し、Dolmaの意図された使用に同意する必要があります。 また、個人情報をリクエストに応じて削除する仕組みも設けられています。
Dolmaはオープンソースのデータセットとしてリリースされた後、一部の批評家はライセンスに多くの条項があると主張しました。 彼らの観点では、Dolmaはオープンであるが、厳密にはオープンソースとはみなされない可能性があります。 また、MetaがLLaMA-2モデルをコードオープンと指定したことも最近、オープンイニシアティブによって批判されました。
