
メタは、新しいAIモデルを発表しました。このモデルは直接35の言語に話し言葉を、100の言語にテキストを翻訳する能力を持っています。
新しいモデル「SeamlessM4T」は、Metaの長年にわたるAI翻訳プロジェクト(No Language Left Behind(NLLB)、Universal Speech Translator、Massively Multilingual Speechなど)の技術を組み合わせており、1つのモデルにまとめています。M4TはMassively Multilingual & Multimodal Machine Translation(大規模な多言語・多モーダル機械翻訳)の略です。
Metaによれば、以前の複数のモデルを1つのシステムに統合することで、エラーや遅延を減少させ、翻訳プロセスの効率と品質を向上させています。
このモデルはマルチモーダルであり、35の言語の音声を含むテキストを100の言語に翻訳できます。モデルはテキストからテキストへ、音声から音声へ、テキストから音声へ、音声からテキストへと翻訳することができ、自動的に音声を認識することもできます。
Metaによれば、SeamlessM4Tは35の言語を(テキストを介さずに)話し言葉に直接翻訳できる初のモデルです。このモデルは、Metaが明示的に目標とする「銀河ヒッチハイク・ガイド」で言及されているバベル魚に類似した普遍的な翻訳者への「重要な一歩」と見なされています。
AIは、メタがそのソーシャルプラットフォームにおける言語の壁を乗り越えるのに役立つ可能性があります。
メタによると、SeamlessM4Tは重要な翻訳基準で新しいトップレベルの結果を達成し、OpenAIのWhisperを上回っています。自分自身で確認したい場合、こちらでインタラクティブなデモを試すことができます。
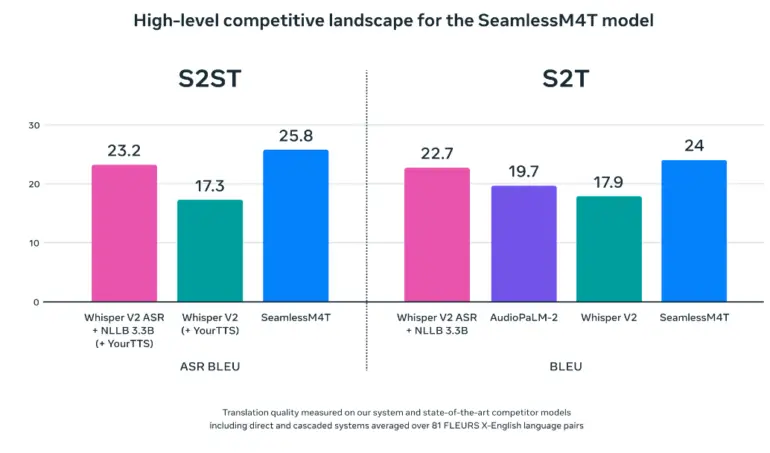
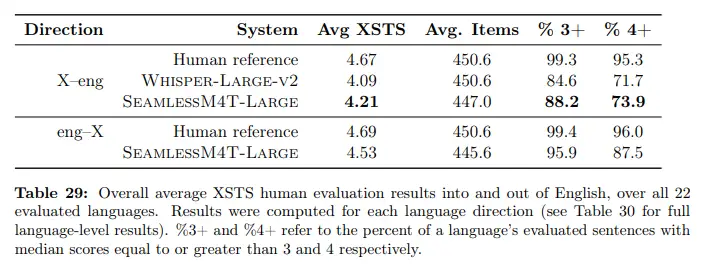
最大のモデルであるSeamlessM4T-Largeも、Whisperに比べて人間の評価でも優れていますが、その差は自動ベンチマークよりも小さいです。どちらのモデルも、品質の面で人間の翻訳には及びませんが、その差は新しいモデルごとに縮小しています。
メタは、このモデルをCC BY-NC 4.0ライセンスのもとでGitHub上でオープンソースモデルとしてリリースしていますが、商用利用はできません。メタのCEOであるマーク・ザッカーバーグによれば、このモデルは将来的にはFacebook、Instagram、WhatsApp、Messenger、Threadsなど、同社自身のソーシャルプラットフォームに統合される予定です。
モデルに加えて、メタは「SeamlessAlign」というデータセットも提供しています。これはSeamlessM4Tのトレーニングに使用するためにチームが編纂したもので、37の言語で470,000時間のコンテンツを含む、多言語翻訳のための最大のオープンデータセットだとメタは述べています。今後、100の言語に拡張することも検討されており、これは普遍的な翻訳者に向けた次のステップとなるでしょう。

