
LIMAにより、メタ社のAI研究者は、比較的少ない例数でチューニングされているにもかかわらず、テストシナリオにおいてGPT-4やBardと同等の性能を達成する新しい言語モデルを発表した。
LIMAは “Less is More for Alignment “の略で、このモデルの機能を表しています。つまり、広範囲に事前訓練されたAIモデルであれば、少ない例数で高品質の結果が得られることを示すものです。
この場合の「少ない例」とは、Metaが他の研究記事、WikiHow、StackExchange、Redditなどのソースから1,000の多様なプロンプトとその出力を手動で選択したことを意味する。
その後、チームはこれらの例を使用して、先にリークされ、オープンソース言語モデルムーブメントを煽った、650億のパラメータを持つ独自のLLaMAモデルを改良した。Metaは、OpenAIがモデルの微調整に使用しており、AIの将来にとって重要な部分であると考えている、高価なRLHFを回避した。
実質よりスタイル
Metaは、LIMAとGPT-4、text-davinci-003、Google Bardを含む他のモデルの結果を人間に比較させた。Metaによると、人間の評価者は、200の例において、GPT-4と比較して43%の割合でLIMAの回答を好んだ。LIMAはGoogle Bardを58パーセント、text-davinci-003を65パーセント上回った。LIMAを除くこれらのモデルはすべて、人間のフィードバックによって改良された。
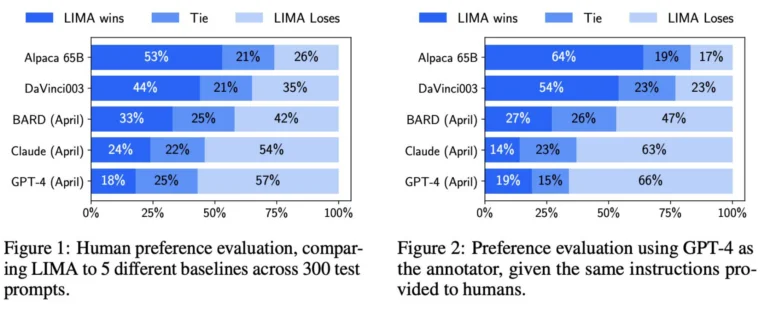
Metaの研究チームは、これらの結果から、言語モデルは事前学習によってその知識の多くを獲得し、少数の例による比較的限定的な微調整で、高品質なコンテンツを生成するモデルを教えるのに十分であることを示していると指摘している。
その結果、OpenAIが採用している人間のフィードバックによる大規模なトレーニングは、以前考えられていたほど重要ではない可能性がある。この点は、メタ社が研究論文の中で明確に強調している。
“サーフェイス・アライメント仮説”
Metaはこの発見を “表面アライメント仮説 “と定義している。この仮説は、事前トレーニング後のアライメント段階は、ユーザーと対話する際にモデルが記憶できる特定のスタイルやフォーマットを教えることが主な目的であることを示唆している。
したがって、ファインチューニングは、実質よりもスタイルに関するものである。これは、OpenAIのRLHFのような、特に広範で複雑な微調整プロセスの一般的な実践とは対照的である。
Metaの研究チームは、LIMAの限界を2つ挙げている。1つ目は、質の高い事例でデータセットを構築することは、スケールが難しいアプローチであること。第二に、LIMAはGPT-4のような既に製品として利用可能なモデルほど堅牢ではない。
研究チームによると、LIMAはほとんど良い答えを生成するが、「敵対的なプロンプト」や「不運なサンプル」によって悪い答えになることがある。それでもLIMAは、AIモデルの整合と調整という複雑な問題が、シンプルなアプローチで解決できることを示している、とMetaチームは言う。
メタ社のAI研究責任者であるヤン・ルクンは、GPT-4や同様のモデルの背後にある努力が相対的に軽んじられることについて、現実的な見方をしている。彼は、大規模な言語モデルは近未来の要素であり、少なくとも「大きな変化がなければ」短期的には役割を果たさないと見ている。
