
大規模多言語音声プロジェクトの一環として、Metaは1,100言語の話し言葉をテキストに、テキストを音声に変換できるAIモデルを発表する。
メタ社によると、この新しいモデルセットは、メタ社のwav2vecと、1,100言語の例文からなる厳選されたデータセット、および、まだ音声技術が存在しない数百人しか話さない言語を含む、ほぼ4,000言語の未選別データセットに基づいている。
このモデルは1,000以上の言語で表現でき、4,000以上の言語を識別できる。メタ社によれば、MMSは10倍の言語をカバーすることで、以前のモデルを凌駕している。利用可能な全言語の概要はこちらで確認できる。
新約聖書がAIデータセットとして新たな用途に
MMSの重要な構成要素は聖書、特に新約聖書である。メタ社のデータセットには、1,107以上の言語、平均32時間の新約聖書の朗読が含まれている。
メタ社はこれらの録音とインターネットからの対応する抜粋を組み合わせて使用した。さらに、3,809のラベルのない音声ファイルも使用された。
1言語あたり32時間では、信頼性の高い音声認識システムには十分なトレーニング素材とは言えないため、Metaはwave2vec 2.0を使って、1,400以上の言語の50万時間以上の音声をMMSモデルの事前トレーニングに使用した。これらのモデルは、多数の言語を理解または識別するために微調整されました。
ベンチマークによると、より多くの異なる言語でトレーニングを行っても、モデルの性能はほぼ一定でした。実際、訓練が増えるにつれて、エラー率は0.4ポイント減少した。
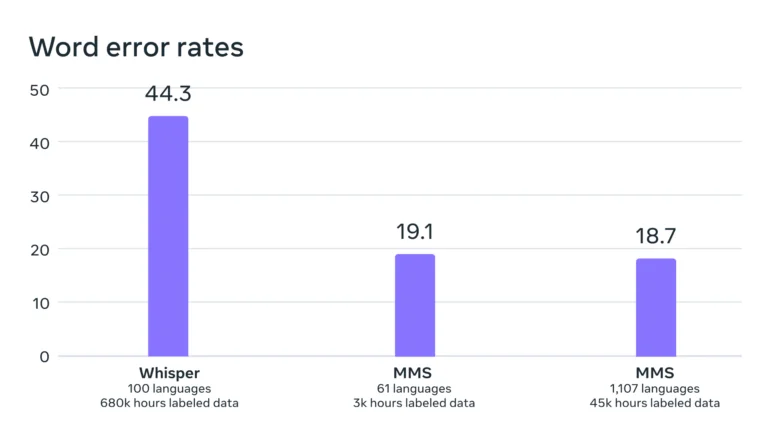
メタによれば、彼らのモデルのエラー率は、幅広い多言語対応に明示的に最適化されていないOpenAIのウィスパーよりもかなり低い。英語だけの比較はもっと興味深いだろう。Twitterの初期のテスターは、この点でWhisperの方が優れていると報告している。
MMS:大規模多言語スピーチ。
– Yann LeCun (@ylecun)2023年5月22日
– 1100の言語でspeech2textとテキストスピーチが可能。
– 4000の音声言語を認識可能。
– コードとモデルはCC-BY-NC 4.0ライセンスで入手可能。
– 単語誤り率はWhisperの半分。
コード モデル: https://t.co/zQ9lWms5TQ
論文:…
Metaによると、データセットの音声が圧倒的に男性であるという事実は、女性の声の理解や生成に悪影響を与えない。
さらに、このモデルは過度に宗教的な言説を生成する傾向はないという。Metaは、これは使用された分類アプローチ(コネクショニスト時間分類)によるもので、言葉の内容や意味よりも、発話パターンやシーケンスに重点を置いているためであるとしている。
しかし、Meta社は、このモデルが単語やフレーズを誤って書き写すことがあり、それが誤った発言や攻撃的な発言につながる可能性があると警告している。
1つのモデルで何千もの言語に対応
メタ社の長期的な目標は、絶滅の危機に瀕している言語を保護するために、できるだけ多くの言語に対応する単一の言語モデルを開発することだ。将来的には、さらに多くの言語や方言に対応できるようになるかもしれない。
「私たちの目標は、人々が情報にアクセスしやすくし、自分の好きな言語でデバイスを使えるようにすることです」とメタは書いている。具体的な応用シナリオとしては、仮想現実や拡張現実技術、あるいはメッセージングなどがある。
将来的には、音声認識、音声合成、音声識別など、すべてのタスクに対して単一のモデルを訓練することで、全体的なパフォーマンスをさらに向上させることができるだろう、とメタ社は書いている。
コード、それぞれ3億と10億のパラメータを持つ事前訓練されたMMSモデル、音声認識と識別のための洗練された派生モデル、およびテキスト音声合成は、Github上のオープンソースモデルとしてMetaから入手可能である。
