
マイクロソフトの研究者が、画像とテキストを処理できるバイオ医療用のマルチモーダルAIアシスタント、LLaVA-Medをデモ。
このマルチモーダルAIモデルのトレーニングには、バイオメディカル画像とテキストのペアの大規模なデータセットが使用された。データセットには、胸部X線、MRI、組織学、病理学、CT画像などが含まれる。まず、モデルはこれらの画像の内容、ひいては重要な生物医学的概念を記述することを学習する。次に、LLaVA-Med(Large Language and Vision Assistant for BioMedicine)がGPT-4によって生成された命令のデータセットを用いて学習される。
このデータセットはGPT-4によって、各画像に関する全ての情報を含む生物医学的テキストに基づいて作成され、画像に関する質問と答えのペアを生成するために使用できる。微調整の段階で、LLaVA-MedはGPT-4からの画像と対応する例で学習される。
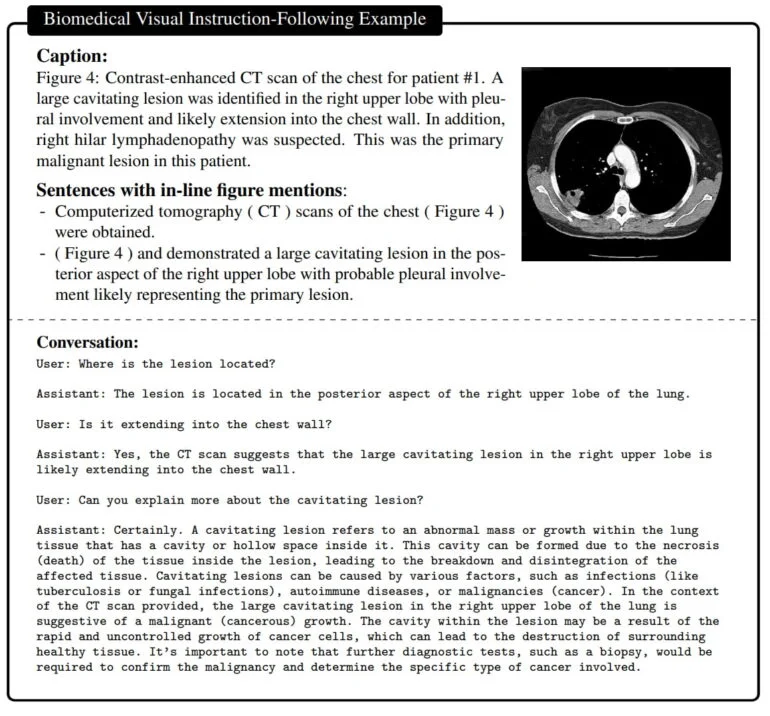
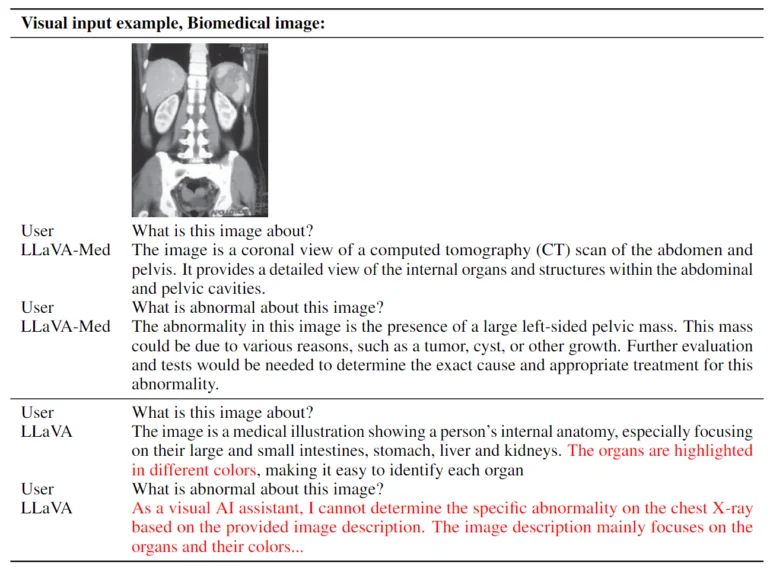
その結果、バイオメディカル画像に関する質問に自然言語で回答できるアシスタントが完成する。
LLaVA-Medは15時間でトレーニングされた
使用されたトレーニング方法により、LLaVA-Medは8つのNvidia A100 GPUで15時間以内にトレーニングされた。これはVision TransformerとVicuna言語モデルに基づいており、MetaのLLaMAをベースにしている。研究チームによると、このモデルは「優れたマルチモーダル会話能力」を持っているという。視覚的な質問に答えるための3つの標準的な生物医学データセットにおいて、LLaVA-Medはいくつかの指標で以前の最先端モデルを上回った。
LLaVA-Medのようなマルチモーダル・アシスタントは、医療研究、複雑な生物医学的画像の解釈、ヘルスケアにおける会話支援など、さまざまな生物医学的アプリケーションで利用される日が来るかもしれない。
LLaVA-Medは、有用なバイオメディカル視覚アシスタントの構築に向けた重要な一歩であると確信していますが、LLaVA-Medは、多くのLMMに共通する幻覚や貧弱な深層推論によって制限されていることに注意してください」と研究チームは述べている。今後の課題は、品質と信頼性の向上です」と研究チームは述べている。
詳細はGitHubを参照されたい。
