
Des chercheurs de Microsoft présentent LLaVA-Med, un assistant d’IA multimodal pour la biomédecine capable de traiter des images et du texte.
Un vaste ensemble de paires d’images et de textes biomédicaux a été utilisé pour former le modèle d’IA multimodale. L’ensemble de données comprend notamment des radiographies du thorax, des IRM, des images d’histologie, de pathologie et de tomodensitométrie. Tout d’abord, le modèle apprend à décrire le contenu de ces images et donc les concepts biomédicaux importants. Ensuite, LLaVA-Med (Large Language and Vision Assistant for BioMedicine) est entraîné à l’aide d’un ensemble d’instructions générées par GPT-4.
Cet ensemble de données est créé par GPT-4 sur la base des textes biomédicaux qui contiennent toutes les informations sur chaque image et peuvent être utilisés pour générer des paires question-réponse sur les images. Dans la phase de réglage fin, LLaVA-Med est ensuite entraîné sur les images et les exemples correspondants de GPT-4.
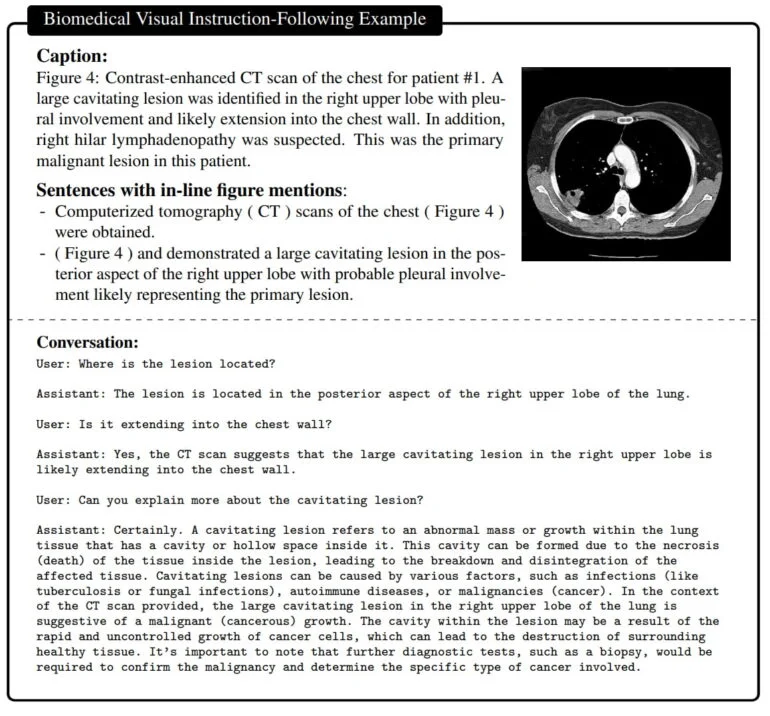
Le résultat est un assistant capable de répondre à des questions sur une image biomédicale en langage naturel.
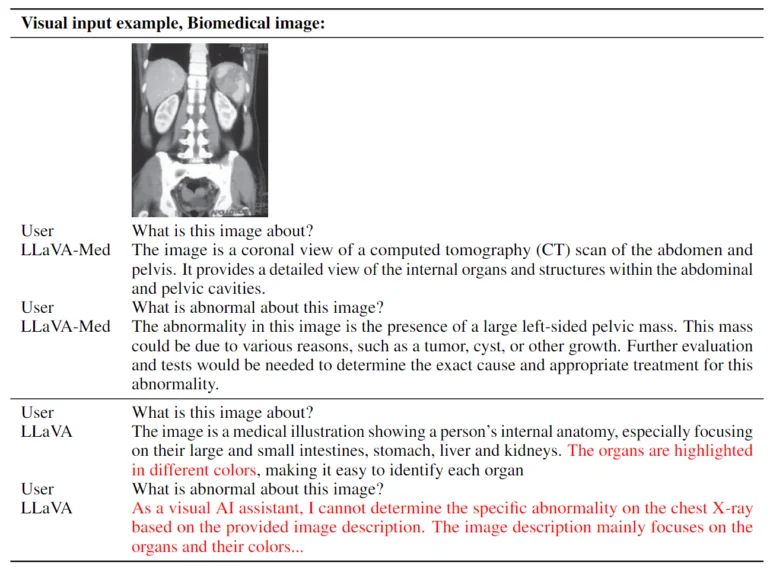
LLaVA-Med a été formé en 15 heures
La méthode d’apprentissage utilisée a permis d’entraîner LLaVA-Med sur huit GPU Nvidia A100 en moins de 15 heures. Il est basé sur un transformateur de vision et le modèle de langage Vicuna, lui-même basé sur LLaMA de Meta. Selon l’équipe, le modèle possède « une excellente capacité de conversation multimodale ». Sur trois ensembles de données biomédicales standard pour répondre à des questions visuelles, LLaVA-Med a surpassé les modèles de pointe précédents sur certaines mesures.
Les assistants multimodaux comme LLaVA-Med pourraient un jour être utilisés dans diverses applications biomédicales, telles que la recherche médicale, l’interprétation d’images biomédicales complexes et l’aide à la conversation dans le domaine des soins de santé.
Cependant, la qualité n’est pas encore suffisante : « Bien que nous pensions que LLaVA-Med représente une étape importante vers la construction d’un assistant visuel biomédical utile, nous notons que LLaVA-Med est limité par des hallucinations et un raisonnement profond médiocre, communs à de nombreux LMM », explique l’équipe. Les travaux futurs se concentreront sur l’amélioration de la qualité et de la fiabilité.
De plus amples informations sont disponibles sur GitHub.

