
これまでAIはスマートフォンのインターフェースをコントロールするのに苦労してきた。しかし、グーグルの研究者たちは解決策を見つけたようだ。
モバイル・ユーザー・インターフェースとの音声ベースのインタラクションを改善するために、グーグル研究所の研究者たちは大規模言語モデル(LLM)の使用を研究している。現在のモバイル・インテリジェント・アシスタントは、画面上の特定の情報に関する質問に答えることができないため、会話によるインタラクションには限界がある。
研究者たちは、ユーザー・インターフェースをテキストに変換するアルゴリズムを含め、モバイル・ユーザー・インターフェースにLLMを適用するための一連の技術を開発した。これらの技術により、開発者は新しい音声ベースのインタラクションを素早く試作し、テストすることができる。LLMは、モデルに問題のタスクの例をいくつか与えることで、文脈に応じたプロンプトを学習するのに適している。
スマートフォン用インターフェースとしての大規模言語モデル
4つの主要なタスクが大規模な実験で研究された。研究者らによると、LLMはこれらのタスクにおいて競争力があり、タスクごとに2つの例しか必要としないことが示された。
1.画面上の質問の生成:例えば、モバイル・ユーザー・インターフェース(UI)が提示された場合、言語モデルは、ユーザー入力を必要とするUI要素に関する関連する質問を生成することができる。この研究によると、言語モデルは、ほぼ完璧な文法(4.98/5)で、画面に表示された入力フィールドに92.8パーセント関連する質問を生成することができた。

2.画面の要約:LLMは、モバイル・ユーザー・インターフェースの主な機能を効果的に要約することができる。以前に紹介したScreen2Wordsモデルよりも正確な要約を生成し、UIに直接表示されていない情報を推測することもできます。
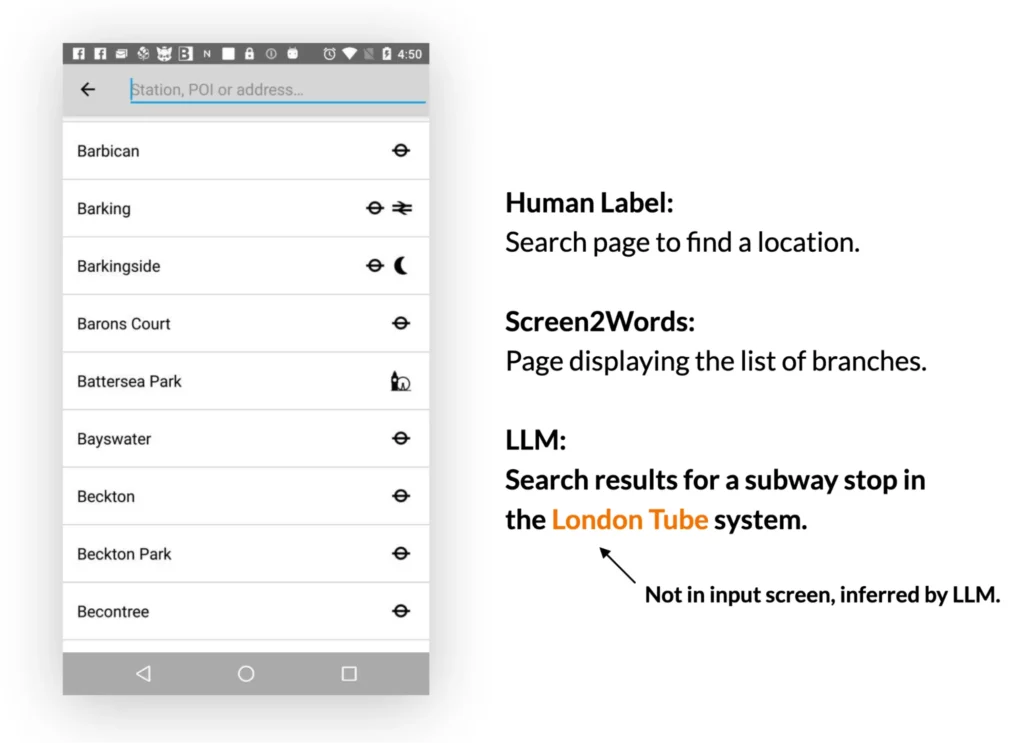
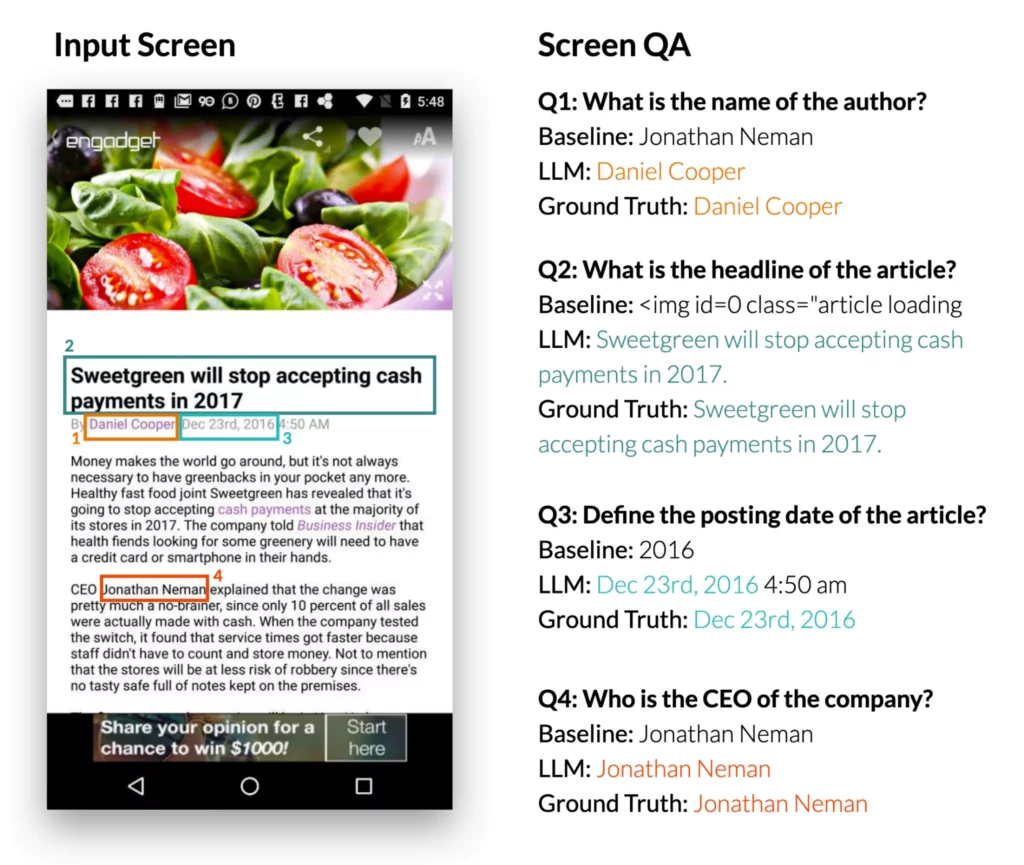
3.画面上の質問に答える:モバイル・ユーザー・インターフェースと、UIに関する情報を必要とする公開質問が提示された場合、LLMは正しい答えを提供することができる。この研究によると、LLMは “見出しは何ですか?”といった質問に答えることができる。LLMは、参照用のDistilBERT QAモデルよりも有意に優れたパフォーマンスを示した。
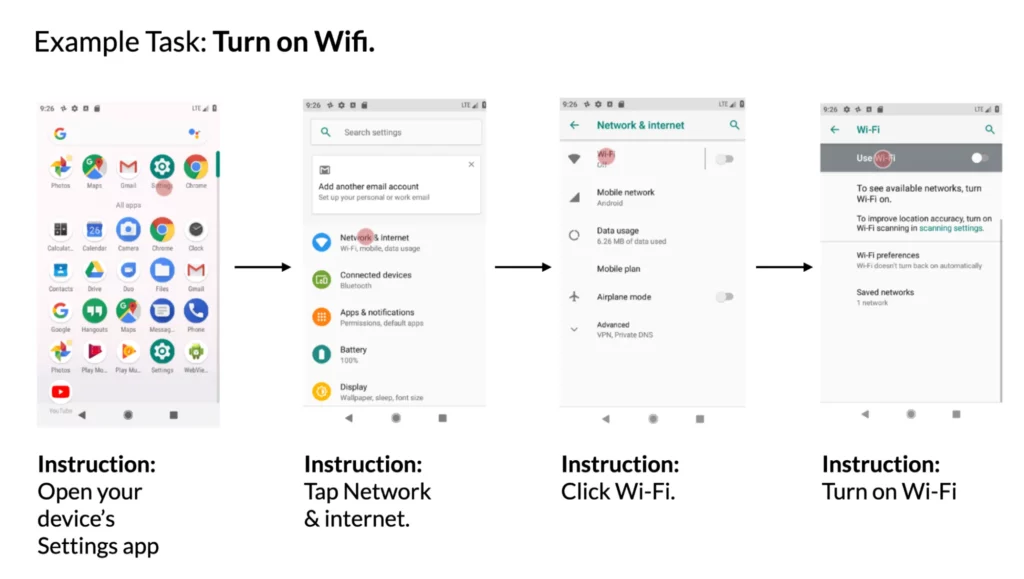
4.UI内のアクションへの命令のマッピング:モバイル・ユーザー・インターフェースと、それを制御するための自然言語の命令が与えられた場合、モデルは、与えられたアクションが実行されるべきオブジェクトIDを予測することができます。例えば、「Gmailを開く」という指示が与えられたとき、モデルはホーム画面上のGmailアイコンを正しく識別することができた。
グーグルの研究者たちは、モバイルUIにおける新しい音声ベースのインタラクションのプロトタイピングは、LLMを使用することで簡素化できると結論づけている。これは、新しいデータベースやモデルの開発に投資する前に、デザイナー、開発者、研究者に新たな可能性を開くものである。
