
API呼び出しに特化した言語モデルToolLLaMAは、16,000以上のAPIを使用しており、ChatGPTのパフォーマンスに達しています。
中国の研究者たちは、ToolLLMというフレームワークを発表しました。これはオープンソースモデルをAPIの使用においてChatGPTと同等の品質に高めるもので、これまでこれらのモデルは商用オファリングに大きく遅れていました。
ToolLLMはオープンソースモデルLLaMAを基にしています。研究チームは、Metaのモデルを高品質なデータセットであるToolBenchでトレーニングしました。このデータセットはChatGPTを使用して自動生成され、特化したToolLLaMAが作成されました。ToolBenchには49のカテゴリにわたるAPI呼び出しを含む命令が含まれています。
この種のリクエストの例としては、「映画の夜を企画していて、いくつかの映画の提案が必要です。アメリカのベストロマンス映画と、近くの適切な場所を教えてもらえますか?」が挙げられます。このようなリクエストを解決するには、モデルは適切なAPIを正しく呼び出す必要があります。例えば、映画の検索APIやホテルの検索APIなどです。
決定木はデータセットの作成を支援します
チームはToolBenchデータセットを構築する際、Depth-First Search Decision Tree(DFSDT)と呼ばれる技術も使用しています。これにより、GPT-4のような言語モデルが、APIのリクエストに対する最適な解決策を見つけるために複数の探索パスを辿ることができます。研究者によれば、実験ではDFSDTは、ネイティブなモデルやチェーン推論などの他の手法と比較して、難しいタスクの解決において明確な優位性を示しています。
ToolLLaMAの能力をさらに向上させるため、研究者は16,000以上のAPIのセットから各ステートメントに対して関連するAPIを自動的に推薦するニューラルAPIリコメンダーもトレーニングしました。
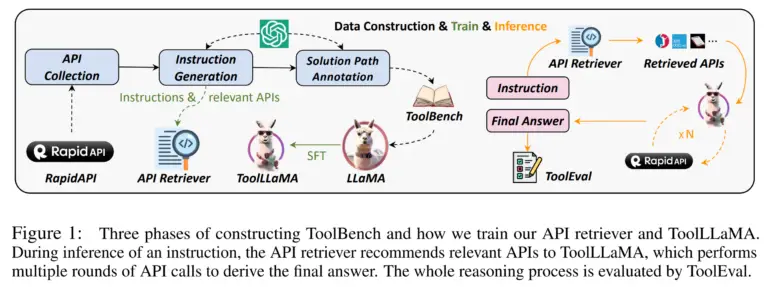
リコメンダーをToolLLaMAに統合することで、APIの手動選択なしで複雑なツールの使用を自動化するパイプラインが作成されます。
ToolLLaMAはAPIの呼び出しにおいてChatGPTの品質に達成します
ToolLLaMAの能力を評価するために、研究チームは自動評価モデルToolEvalを導入しています。このモデルは2つの主要指標、成功率(指示を成功裏に完了させる能力)と勝率(既存の方法とのソリューションの品質の比較)を測定します。
ToolEvalの比較において、ToolLLaMAモデルはChatGPTと同等の成功率を達成しており、それにもかかわらず明らかに少ない例でトレーニングされています。ToolLLaMAはまた、以前に未知だったAPIにも、それらのドキュメンテーションを読むことで成功裏に対処することができます。Googleによって最近公開された研究も、そのようなドキュメンテーションを学習することが有益であることを示しています。それはthe Decoderのコンテンツで提供されています。

