
Demonstração científica com aprendizado de máquina revela sequências de DNA ‘extremas' com atividades personalizadas.
A inteligência artificial (IA) explodiu em nossos feeds de notícias, com o ChatGPT e outras tecnologias de IA relacionadas se tornando foco de ampla escrutínio público. Além dos populares chatbots, os biólogos estão encontrando maneiras de aproveitar a IA para investigar as funções essenciais dos nossos genes.
Anteriormente, pesquisadores da Universidade da Califórnia em San Diego que investigam sequências de DNA que ativam genes utilizaram a inteligência artificial para identificar uma peça enigmática ligada à ativação de genes, um processo fundamental envolvido no crescimento, desenvolvimento e doenças. Utilizando o aprendizado de máquina, um tipo de inteligência artificial, o professor James T. Kadonaga, da Escola de Ciências Biológicas, e seus colegas descobriram a região do promotor central downstream (DPR), um código de ativação de DNA “porta de entrada” que está envolvido no funcionamento de até um terço dos nossos genes.
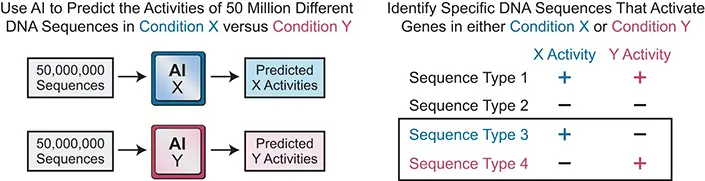
A partir dessa descoberta, Kadonaga e os pesquisadores Long Vo ngoc e Torrey E. Rhyne utilizaram o aprendizado de máquina para identificar sequências de DNA “extremas” sintéticas com funções especificamente projetadas na ativação de genes. Publicando no periódico Genes & Development, os pesquisadores testaram milhões de sequências de DNA diferentes por meio do aprendizado de máquina (IA), comparando o elemento de ativação do gene DPR em seres humanos versus moscas-das-frutas (Drosophila). Ao usar a IA, eles conseguiram encontrar sequências de DPR raras e personalizadas que estão ativas em humanos, mas não em moscas-das-frutas e vice-versa. Mais genericamente, essa abordagem poderia agora ser usada para identificar sequências de DNA sintético com atividades que poderiam ser úteis na biotecnologia e medicina.
“No futuro, essa estratégia poderia ser usada para identificar sequências de DNA sintéticas extremas com aplicações práticas e úteis. Em vez de comparar seres humanos (condição X) com moscas-das-frutas (condição Y), poderíamos testar a capacidade do medicamento A (condição X), mas não do medicamento B (condição Y), de ativar um gene”, disse Kadonaga, um professor distinto do Departamento de Biologia Molecular. “Esse método também poderia ser usado para encontrar sequências de DNA personalizadas que ativem um gene no tecido 1 (condição X), mas não no tecido 2 (condição Y). Existem inúmeras aplicações práticas dessa abordagem baseada em IA. As sequências de DNA extremas sintéticas podem ser muito raras, talvez uma em um milhão – se elas existirem, poderão ser encontradas usando a IA.”
A aprendizagem de máquina é um ramo da IA em que os sistemas de computador continuamente melhoram e aprendem com base em dados e experiência. Na nova pesquisa, Kadonaga, Vo ngoc (um ex-pesquisador pós-doutorado da UC San Diego, agora na Velia Therapeutics) e Rhyne (um associado de pesquisa) utilizaram um método conhecido como regressão de vetor de suporte para “treinar” modelos de aprendizagem de máquina com 200.000 sequências de DNA estabelecidas com base em dados de experimentos de laboratório do mundo real. Essas foram as metas apresentadas como exemplos para o sistema de aprendizagem de máquina. Em seguida, eles “alimentaram” 50 milhões de sequências de DNA de teste nos sistemas de aprendizagem de máquina para seres humanos e moscas-das-frutas e pediram que comparassem as sequências e identificassem sequências únicas nos dois enormes conjuntos de dados.
Embora os sistemas de aprendizagem de máquina tenham mostrado que as sequências humanas e de moscas-das-frutas se sobrepõem em grande parte, os pesquisadores focaram na questão central de saber se os modelos de IA poderiam identificar casos raros em que a ativação do gene é altamente ativa em humanos, mas não em moscas-das-frutas. A resposta foi um “sim” retumbante. Os modelos de aprendizagem de máquina conseguiram identificar sequências de DNA específicas de humanos (e específicas de moscas-das-frutas). Importante destacar que as funções preditas pela IA das sequências extremas foram verificadas no laboratório de Kadonaga por meio de métodos convencionais de teste de laboratório.
“Antes de embarcar nesse trabalho, nós não sabíamos se os modelos de IA eram ‘inteligentes' o suficiente para prever as atividades de 50 milhões de sequências, especialmente sequências ‘extremas' atípicas com atividades incomuns. Portanto, é muito impressionante e bastante notável que os modelos de IA pudessem prever as atividades das raras sequências extremas, uma em um milhão”, disse Kadonaga, acrescentando que seria praticamente impossível realizar os comparáveis 100 milhões de experimentos de laboratório que a tecnologia de aprendizagem de máquina analisou, pois cada experimento de laboratório levaria quase três semanas para ser concluído.
As sequências raras identificadas pelo sistema de aprendizado de máquina servem como uma demonstração bem-sucedida e estabelecem o cenário para outros usos de aprendizado de máquina e outras tecnologias de IA na biologia.
“No cotidiano, as pessoas estão descobrindo novas aplicações para ferramentas de IA, como o ChatGPT. Aqui, demonstramos o uso da IA para o design de elementos de DNA personalizados na ativação de genes. Esse método deve ter aplicações práticas na biotecnologia e pesquisa biomédica”, disse Kadonaga. “Mais amplamente, os biólogos provavelmente estão apenas começando a explorar o poder da tecnologia de IA.”
A pesquisa foi financiada pelos Institutos Nacionais de Saúde (R35 GM118060).
Fonte: UCSD
