
Habilidades emergentes em grandes modelos de linguagem geraram excitação e preocupação. Agora, pesquisadores de Stanford sugerem que essas habilidades podem ser mais uma miragem induzida por métricas do que um fenômeno real.
O surgimento repentino de novas habilidades ao dimensionar grandes modelos de linguagem é um tópico fascinante e uma razão para e contra o dimensionamento adicional desses modelos: o GPT-3 da OpenAI foi capaz de resolver tarefas matemáticas simples acima de um certo número de parâmetros, e um pesquisador do Google contou nada menos que 137 habilidades emergentes em benchmarks de PNL como o BIG-Bench.
Em geral, habilidades emergentes (ou capacidades) referem-se àquelas que de repente se manifestam em modelos acima de um tamanho específico, mas estão ausentes em modelos menores. O aparecimento de tais saltos instantâneos e imprevisíveis estimulou uma extensa pesquisa sobre as origens dessas habilidades e, mais crucialmente, sua previsibilidade. Isso ocorre porque, dentro do campo da pesquisa de alinhamento de IA, o surgimento imprevisto de habilidades de IA é considerado um indicador preventivo de que redes de IA em grande escala podem inesperadamente desenvolver habilidades indesejadas ou até perigosas sem qualquer aviso.
Agora, em um novo trabalho de pesquisa, pesquisadores da Universidade de Stanford mostram que, embora modelos como o GPT-3 desenvolvam habilidades matemáticas rudimentares, elas deixam de ser habilidades emergentes quando você muda a maneira como as mede.
Habilidades emergentes são o resultado de uma métrica específica
“Colocamos em questão a afirmação de que os LLMs possuem habilidades emergentes, pelas quais queremos dizer especificamente mudanças nítidas e imprevisíveis nas saídas do modelo em função da escala do modelo em tarefas específicas”.
Normalmente, a capacidade de um modelo de linguagem grande é medida em termos de precisão, que é a proporção de previsões corretas do número total de previsões. Essa métrica não é linear, e é por isso que as mudanças na precisão são vistas como saltos, disse a equipe.

“Nossa explicação alternativa postula que as habilidades emergentes são uma miragem causada principalmente pela escolha pelo pesquisador de uma métrica que deforma de forma não linear ou descontínua as taxas de erro por token e, parcialmente, pela posse de poucos dados de teste para estimar com precisão o desempenho de modelos menores (fazendo com que modelos menores pareçam totalmente incapazes de executar a tarefa) e parcialmente pela avaliação de poucos modelos de grande escala”, afirma o artigo.
Usando uma métrica linear, como a distância de edição de token, uma métrica que calcula o número mínimo de edições de um único token necessárias para transformar uma sequência de tokens em outra, não há mais um salto visível – em vez disso, uma melhoria suave, contínua e previsível é observada à medida que o número de parâmetros aumenta.
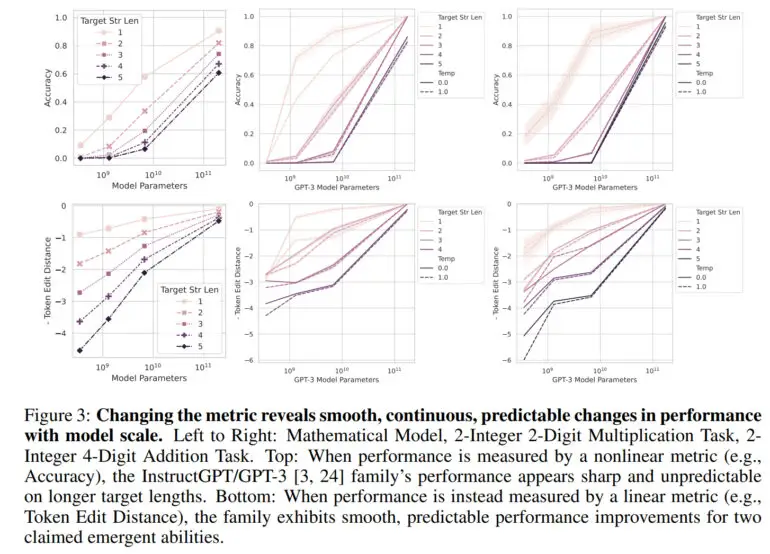
Em seu trabalho, a equipe mostra que as capacidades emergentes do GPT-3 e de outros modelos são devidas a essas métricas não lineares e que nenhum salto drástico é aparente em uma métrica linear. Além disso, os pesquisadores reproduzem esse efeito com modelos de visão computacional, nos quais a emergência não foi medida antes.
Habilidades emergentes são “provavelmente uma miragem”
“A principal conclusão é que, para uma tarefa fixa e uma família de modelos fixos, o pesquisador pode escolher uma métrica para criar uma habilidade emergente ou escolher uma métrica para eliminar uma habilidade emergente”, disse a equipe. “Logo, as habilidades emergentes podem ser criações das escolhas do pesquisador, não uma propriedade fundamental da família modelo na tarefa específica.”
No entanto, a equipe enfatiza que este trabalho não deve ser interpretado como significando que grandes modelos de linguagem como GPT-4 não podem ter habilidades emergentes. “Em vez disso, nossa mensagem é que as habilidades emergentes anteriormente reivindicadas podem provavelmente ser uma miragem induzida por análises de pesquisadores”.
Para pesquisas de alinhamento, este trabalho pode ser uma boa notícia, pois parece demonstrar a previsibilidade de habilidades em grandes modelos de linguagem. A OpenAI também mostrou em um relatório sobre o GPT-4 que pode prever com precisão o desempenho do GPT-4 em muitos benchmarks.
No entanto, como a equipe não descarta a possibilidade de habilidades emergentes por si só, a questão é se tais habilidades já existem. Um candidato pode ser “aprendizado de poucos tiros” ou “aprendizado em contexto”, que a equipe não explora neste trabalho. Essa capacidade foi demonstrada pela primeira vez em detalhes no GPT-3 e é a base para a engenharia rápida de hoje.
