
Las nuevas capacidades de los grandes modelos lingüísticos han generado tanto entusiasmo como preocupación. Ahora, investigadores de Stanford sugieren que estas capacidades pueden ser más un espejismo inducido por la métrica que un fenómeno real.
La aparición repentina de nuevas habilidades al escalar grandes modelos lingüísticos es un tema fascinante y un motivo a favor y en contra de seguir escalando estos modelos: el GPT-3 de OpenAI era capaz de resolver tareas matemáticas sencillas a partir de un cierto número de parámetros, y un investigador de Google contó no menos de 137 habilidades emergentes en pruebas de PNL como BIG-Bench.
En general, las habilidades (o capacidades) emergentes se refieren a aquellas que se manifiestan repentinamente en modelos por encima de un tamaño específico, pero que están ausentes en modelos más pequeños. La aparición de estos saltos instantáneos e imprevisibles ha estimulado una amplia investigación sobre los orígenes de estas capacidades y, lo que es más importante, sobre su previsibilidad. Esto se debe a que, dentro del campo de la investigación de la alineación de la IA, la aparición imprevista de habilidades de IA se considera un indicador preventivo de que las redes de IA a gran escala pueden desarrollar inesperadamente habilidades no deseadas o incluso peligrosas sin previo aviso.
Ahora, en un nuevo trabajo de investigación, investigadores de la Universidad de Stanford demuestran que, aunque modelos como GPT-3 desarrollan habilidades matemáticas rudimentarias, dejan de ser habilidades emergentes cuando se cambia la forma de medirlas.
Las habilidades emergentes son el resultado de una métrica específica
«Ponemos en duda la afirmación de que los LLM poseen habilidades emergentes, con lo que nos referimos específicamente a cambios claros e impredecibles en los resultados del modelo en función de su escala en tareas específicas».
Normalmente, la capacidad de un gran modelo lingüístico se mide en términos de precisión, que es la proporción de predicciones correctas sobre el número total de predicciones. Esta métrica no es lineal, por lo que los cambios en la precisión se perciben como saltos, explica el equipo.

«Nuestra explicación alternativa postula que las habilidades emergentes son un espejismo causado principalmente por la elección por parte del investigador de una métrica que deforma de forma no lineal o discontinua las tasas de error por token, y en parte por tener muy pocos datos de prueba para estimar con precisión el rendimiento de los modelos más pequeños (lo que hace que los modelos más pequeños parezcan totalmente incapaces de realizar la tarea), y en parte por evaluar muy pocos modelos a gran escala», afirma el artículo.
Utilizando una métrica lineal como la distancia de edición de tokens, que calcula el número mínimo de ediciones de un solo token necesarias para transformar una secuencia de tokens en otra, ya no hay un salto visible, sino que se observa una mejora suave, continua y predecible a medida que aumenta el número de parámetros.
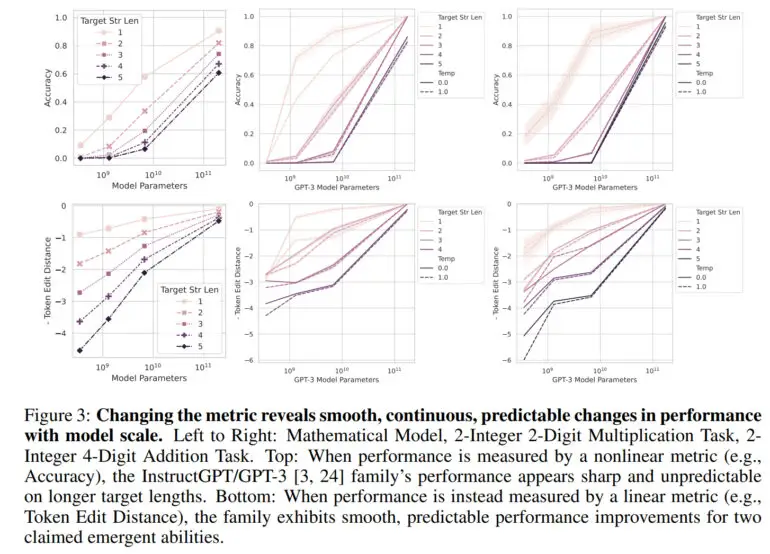
En su trabajo, el equipo demuestra que las capacidades emergentes de GPT-3 y otros modelos se deben a estas métricas no lineales y que no se aprecia ningún salto drástico en una métrica lineal. Además, los investigadores reproducen este efecto con modelos de visión por ordenador, en los que la emergencia no se había medido antes.
Las capacidades emergentes son «probablemente un espejismo»
«La principal conclusión es que, para una tarea fija y una familia de modelos fijos, el investigador puede elegir una métrica para crear una habilidad emergente o elegir una métrica para eliminar una habilidad emergente», afirma el equipo. «Así, las habilidades emergentes pueden ser creaciones de las elecciones del investigador, no una propiedad fundamental de la familia de modelos en la tarea específica»
Sin embargo, el equipo subraya que este trabajo no debe interpretarse como que los grandes modelos lingüísticos como GPT-4 no pueden tener habilidades emergentes. «Por el contrario, nuestro mensaje es que las capacidades emergentes anteriormente reivindicadas pueden ser probablemente un espejismo inducido por los análisis de los investigadores».
Para la investigación de la alineación, este trabajo podría ser una buena noticia, ya que parece demostrar la previsibilidad de las habilidades en los grandes modelos lingüísticos. OpenAI también ha demostrado en un informe sobre GPT-4 que puede predecir con exactitud su rendimiento en muchos puntos de referencia.
Sin embargo, como el equipo no descarta la posibilidad de habilidades emergentes per se, la cuestión es si tales habilidades ya existen. Un candidato podría ser el «aprendizaje de pocos disparos» o «aprendizaje en contexto», que el equipo no explora en este artículo. Esta capacidad se demostró por primera vez en GPT-3 y es la base de la ingeniería rápida actual.

