
O Google está testando uma nova abordagem para modelos de linguagem
O Google está testando um novo tipo de modelo de linguagem chamado Gemini Diffusion — um sistema experimental que gera texto utilizando técnicas de difusão, em vez da tradicional predição palavra por palavra.
Diferentemente dos modelos convencionais, que produzem texto palavra a palavra, o Gemini Diffusion emprega uma técnica inspirada na geração de imagens. O sistema começa com um ruído aleatório e, em múltiplas passagens, molda esse ruído em trechos completos de texto, permitindo correções durante o processo e um controle mais preciso sobre a saída. Segundo a Deepmind, esse método proporciona um resultado mais consistente e logicamente conectado, sendo especialmente eficaz para tarefas que exigem precisão, coerência e iteração, como a geração de código e a edição textual.

Rapidez e Competitividade
O Gemini Diffusion gera seções completas de texto de uma única vez — conseguindo fazê-lo de forma muito mais rápida do que os modelos autoregressivos que operam da esquerda para a direita. A Deepmind relata uma velocidade de 1.479 tokens por segundo (excluindo custos adicionais), com uma latência inicial de apenas 0,84 segundos. Brendan O'Donoghue, pesquisador da Deepmind, afirma que o modelo pode atingir até 2.000 tokens por segundo em tarefas de programação, mesmo considerando etapas como tokenização, pré-preenchimento e verificações de segurança.
Benchmarks e Resultados Comparativos
Em testes comparativos, o desempenho do Gemini Diffusion se equipara, de maneira geral, ao do Gemini 2.0 Flash Lite. Em avaliações de tarefas de programação — como os testes HumanEval (89,6% versus 90,2%) e MBPP (76,0% versus 75,8%) — os resultados são quase idênticos. Além disso, o modelo se destaca levemente em LiveCodeBench (30,9% versus 28,5%) e LBPP (56,8% versus 56,0%). Por outro lado, ele registrou pontuações inferiores em outras áreas, como no teste de raciocínio científico GPQA Diamond (40,4% versus 56,5%) e no exame multilíngue Global MMLU Lite (69,1% versus 79,0%).
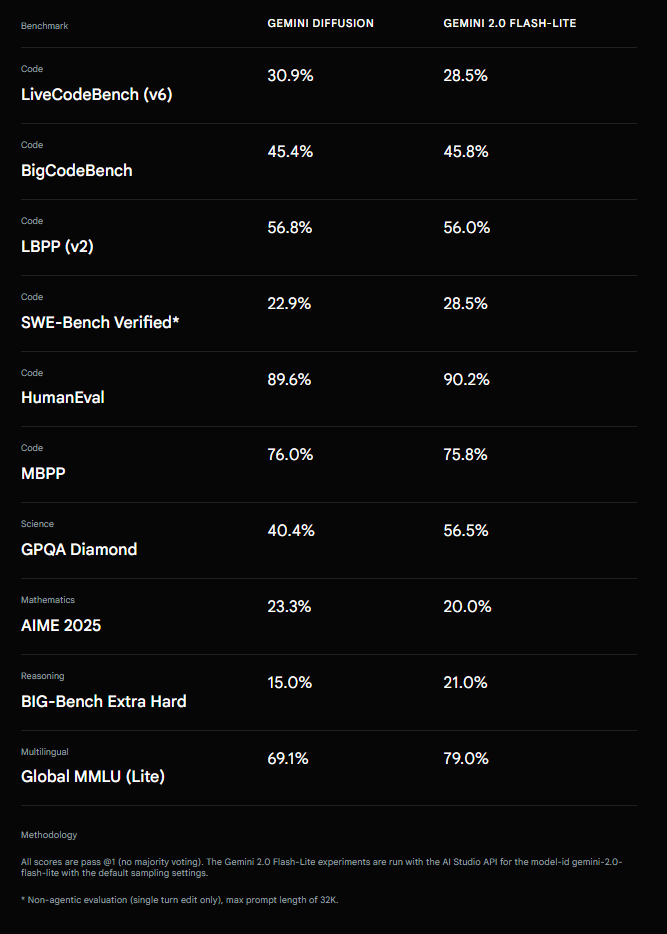
Jack Rae, cientista principal na Google Deepmind, classificou esses resultados como um “momento histórico”. Até então, os modelos autoregressivos vinham superando consistentemente os modelos de difusão na qualidade do texto, e não se sabia se essa lacuna seria fechada. Rae atribui o avanço à pesquisa concentrada e à solução de diversos desafios técnicos.
O Gemini Diffusion encontra-se, por ora, disponível apenas em forma de demonstração experimental.
