
Les capacités émergentes des grands modèles de langage ont suscité à la fois enthousiasme et inquiétude. Aujourd’hui, des chercheurs de Stanford suggèrent que ces capacités pourraient être davantage un mirage induit par les métriques qu’un véritable phénomène.
L’émergence soudaine de nouvelles capacités lors de la mise à l’échelle de grands modèles de langage est un sujet fascinant et une raison pour ou contre la poursuite de la mise à l’échelle de ces modèles : le GPT-3 d’OpenAI était capable de résoudre des tâches mathématiques simples au-delà d’un certain nombre de paramètres, et un chercheur de Google a dénombré pas moins de 137 capacités émergentes dans des benchmarks de NLP tels que BIG-Bench.
En général, les capacités émergentes sont celles qui se manifestent soudainement dans les modèles dépassant une certaine taille, alors qu’elles sont absentes des modèles plus petits. L’apparition de ces sauts instantanés et imprévisibles a stimulé des recherches approfondies sur l’origine de ces capacités et, plus important encore, sur leur prévisibilité. En effet, dans le domaine de la recherche sur l’alignement de l’IA, l’émergence imprévue de capacités d’IA est considérée comme un indicateur préventif que les réseaux d’IA à grande échelle peuvent développer de manière inattendue des capacités indésirables, voire dangereuses, sans aucun avertissement.
Aujourd’hui, dans un nouvel article, des chercheurs de l’université de Stanford montrent que même si des modèles tels que le GPT-3 développent des compétences mathématiques rudimentaires, elles cessent d’être des compétences émergentes dès lors que l’on change la manière de les mesurer.
Les compétences émergentes sont le résultat d’une mesure spécifique
« Nous remettons en question l’affirmation selon laquelle les LLM possèdent des compétences émergentes, c’est-à-dire des changements clairs et imprévisibles dans les résultats du modèle en fonction de l’échelle du modèle pour des tâches spécifiques.
Généralement, la capacité d’un grand modèle de langage est mesurée en termes de précision, c’est-à-dire la proportion de prédictions correctes par rapport au nombre total de prédictions. Cette mesure n’est pas linéaire, c’est pourquoi les changements dans la précision sont perçus comme des sauts, a déclaré l’équipe.

« Notre explication alternative postule que les compétences émergentes sont un mirage causé principalement par le choix du chercheur d’une métrique qui déforme de manière non linéaire ou discontinue les taux d’erreur par jeton, et en partie par le fait d’avoir trop peu de données de test pour estimer avec précision la performance des petits modèles (ce qui fait que les petits modèles semblent totalement incapables de réaliser la tâche), et en partie par l’évaluation de trop peu de modèles à grande échelle », peut-on lire dans l’article.
En utilisant une mesure linéaire telle que la distance d’édition de jeton, une mesure qui calcule le nombre minimum d’éditions d’un seul jeton nécessaire pour transformer une séquence de jetons en une autre, il n’y a plus de saut visible – au lieu de cela, une amélioration douce, continue et prévisible est observée au fur et à mesure que le nombre de paramètres augmente.
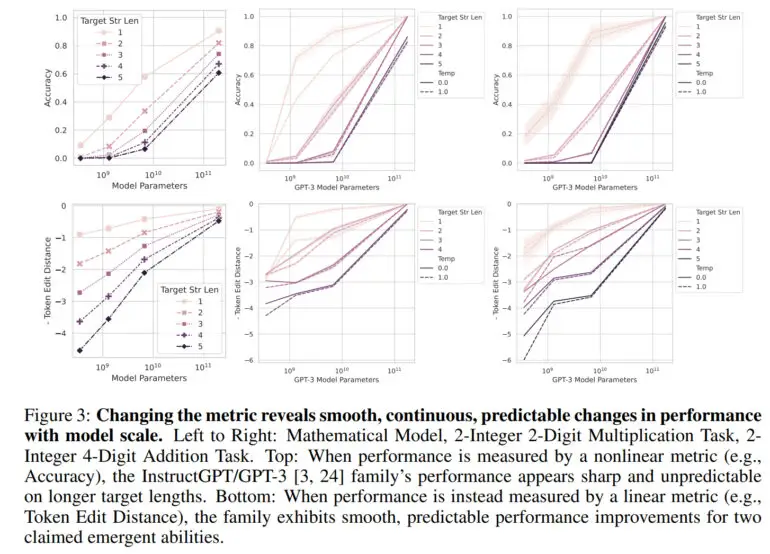
Dans ses travaux, l’équipe montre que les capacités émergentes du GPT-3 et d’autres modèles sont dues à ces métriques non linéaires et qu’aucun bond en avant n’est apparent dans une métrique linéaire. En outre, les chercheurs reproduisent cet effet avec des modèles de vision par ordinateur, dans lesquels l’émergence n’a jamais été mesurée auparavant.
Les capacités émergentes sont « probablement un mirage »
« La principale conclusion est que, pour une tâche fixe et une famille de modèles fixes, le chercheur peut choisir une métrique pour créer une compétence émergente ou choisir une métrique pour éliminer une compétence émergente », a déclaré l’équipe. « Ainsi, les compétences émergentes peuvent être des créations des choix du chercheur, et non une propriété fondamentale de la famille de modèles dans la tâche spécifique »
Toutefois, l’équipe souligne que ce travail ne doit pas être interprété comme signifiant que les grands modèles de langage comme le GPT-4 ne peuvent pas avoir de compétences émergentes. « Notre message est plutôt que les capacités émergentes précédemment revendiquées pourraient être un mirage induit par les analyses des chercheurs.
Pour la recherche sur l’alignement, ce travail pourrait être une bonne nouvelle, car il semble démontrer la prévisibilité des compétences dans les grands modèles de langage. OpenAI a également montré dans un rapport sur GPT-4 qu’elle pouvait prédire avec précision les performances de GPT-4 sur de nombreux points de référence.
Cependant, comme l’équipe n’exclut pas la possibilité de compétences émergentes en soi, la question est de savoir si de telles compétences existent déjà. L’un des candidats pourrait être « l’apprentissage en quelques coups » ou « l’apprentissage en contexte », que l’équipe n’explore pas dans le présent document. Cette capacité a été démontrée en détail pour la première fois dans le GPT-3 et constitue la base de l’ingénierie rapide d’aujourd’hui.
