
Dans le cadre du projet Massively Multilingual Speech, Meta lance des modèles d’IA capables de convertir la langue parlée en texte et le texte en parole dans 1 100 langues.
Le nouvel ensemble de modèles est basé sur wav2vec de Meta, ainsi que sur un ensemble de données sélectionnées d’exemples pour 1 100 langues et un autre ensemble de données non sélectionnées pour près de 4 000 langues, y compris des langues parlées par seulement quelques centaines de personnes, pour lesquelles il n’existe pas encore de technologie vocale, selon Meta.
Le modèle peut s’exprimer dans plus de 1 000 langues et en identifier plus de 4 000. Selon Meta, le MMS surpasse les modèles précédents en couvrant dix fois plus de langues. Vous pouvez obtenir un aperçu de toutes les langues disponibles ici.
Le Nouveau Testament devient un nouvel ensemble de données d’IA
La Bible, et plus particulièrement le Nouveau Testament, est un élément clé du MMS. L’ensemble de données de Meta contient des lectures du Nouveau Testament dans plus de 1 107 langues, avec une durée moyenne de 32 heures.
Meta a utilisé ces enregistrements en combinaison avec des extraits correspondants provenant de l’internet. En outre, 3 809 autres fichiers audio non étiquetés ont été utilisés, également avec des lectures du Nouveau Testament, mais sans informations supplémentaires sur la langue.
Étant donné que 32 heures par langue ne constituent pas un matériel d’entraînement suffisant pour un système de reconnaissance vocale fiable, Meta a utilisé wave2vec 2.0 pour pré-entraîner les modèles MMS avec plus de 500 000 heures de parole dans plus de 1 400 langues. Ces modèles ont ensuite été affinés pour comprendre ou identifier de nombreuses langues.
Les analyses comparatives montrent que les performances des modèles sont restées pratiquement constantes, même avec l’entraînement dans un plus grand nombre de langues différentes. En fait, le taux d’erreur a diminué de 0,4 point de pourcentage avec l’augmentation de la formation.
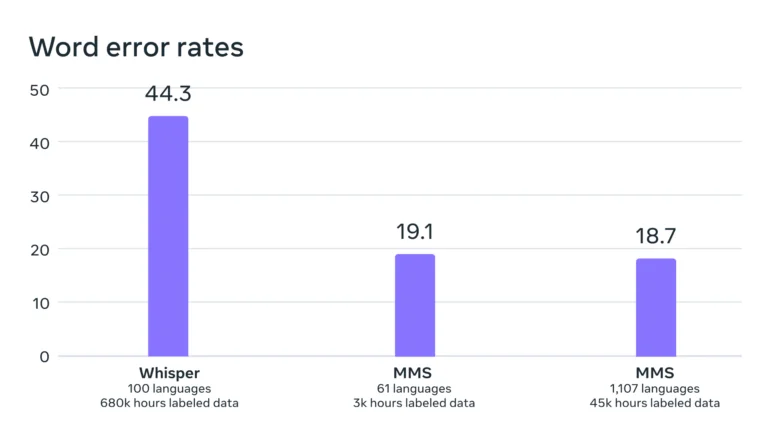
Selon Meta, le taux d’erreur de son modèle est nettement inférieur à celui de Whisper d’OpenAI, qui n’a pas été explicitement optimisé pour un large multilinguisme. Une comparaison en anglais uniquement serait plus intéressante. Les premiers testeurs sur Twitter signalent que Whisper est plus performant à cet égard.
MMS : Massively Multilingual Speech (parole massivement multilingue).
– Yann LeCun (@ylecun) 22 mai 2023
– Peut faire du speech2text et du text speech dans 1100 langues.
– Peut reconnaître 4000 langues parlées.
– Code et modèles disponibles sous la licence CC-BY-NC 4.0.
– taux d’erreur de moitié inférieur à celui de Whisper.
Code Modèles : https://t.co/zQ9lWms5TQ
Article :..
Selon Meta, le fait que les voix de l’ensemble de données soient majoritairement masculines n’affecte pas négativement la compréhension ou la génération de voix féminines.
En outre, le modèle n’a pas tendance à générer des discours trop religieux. Meta attribue cela à l’approche de classification utilisée (classification temporelle connexionniste), qui se concentre davantage sur les modèles et les séquences de discours que sur le contenu et la signification des mots.
Meta met toutefois en garde contre le fait que le modèle transcrit parfois des mots ou des phrases de manière incorrecte, ce qui peut conduire à des déclarations erronées ou offensantes.
Un modèle pour des milliers de langues
L’objectif à long terme de Meta est de développer un modèle linguistique unique pour le plus grand nombre de langues possible afin de préserver les langues menacées. Les futurs modèles pourraient prendre en charge encore plus de langues et même de dialectes.
« Notre objectif est de faciliter l’accès des gens à l’information et de leur permettre d’utiliser des appareils dans leur langue préférée », écrit Meta. Parmi les scénarios d’application spécifiques figurent les technologies de réalité virtuelle et augmentée, ou la messagerie.
À l’avenir, un seul modèle pourrait être entraîné pour toutes les tâches, telles que la reconnaissance vocale, la synthèse vocale et l’identification vocale, ce qui permettrait d’améliorer encore les performances globales, écrit Meta.
Le code, les modèles MMS pré-entraînés avec 300 millions et un milliard de paramètres respectivement, et les dérivations affinées pour la reconnaissance et l’identification de la parole, ainsi que la synthèse vocale, sont disponibles auprès de Meta en tant que modèles open source sur Github.
