
Grâce à un nouvel ensemble de données, Deepmind s’est associé à de nombreuses autres institutions pour combler le manque de données dans la formation des robots et permettre la généralisation des capacités des robots à tous les types de robots. Les premiers résultats sont prometteurs.
Google Deepmind, en collaboration avec 33 laboratoires universitaires, a lancé un nouvel ensemble de données et de modèles conçus pour promouvoir l’apprentissage généralisé en robotique à travers différents types de robots.
Les données proviennent de 22 types de robots différents. L’objectif est de développer des modèles de robots capables de mieux généraliser leurs capacités entre différents types de robots.
Vers un robot polyvalent
Jusqu’à présent, un modèle de robot distinct devait être formé pour chaque tâche, chaque robot et chaque environnement. Cela nécessite la collecte d’un grand nombre de données. De plus, le moindre changement dans une variable signifiait que le processus devait être recommencé, selon Deepmind.
L’objectif de l’initiative Open-X est de trouver un moyen de rassembler des connaissances sur différents robots (corporations) et de former un robot universel. Cette idée a conduit au développement de l’ensemble de données d’incarnation Open-X et de RT-1-X, un modèle de robot transformateur dérivé de RT-1 (Robotic Transformer-1) et entraîné sur le nouvel ensemble de données.
Des tests effectués dans cinq laboratoires de recherche différents ont montré une augmentation moyenne de 50 % du taux de réussite des tâches lorsque le RT-1-X a pris le contrôle de cinq robots courants par rapport à des modèles de contrôle spécifiques à un robot.
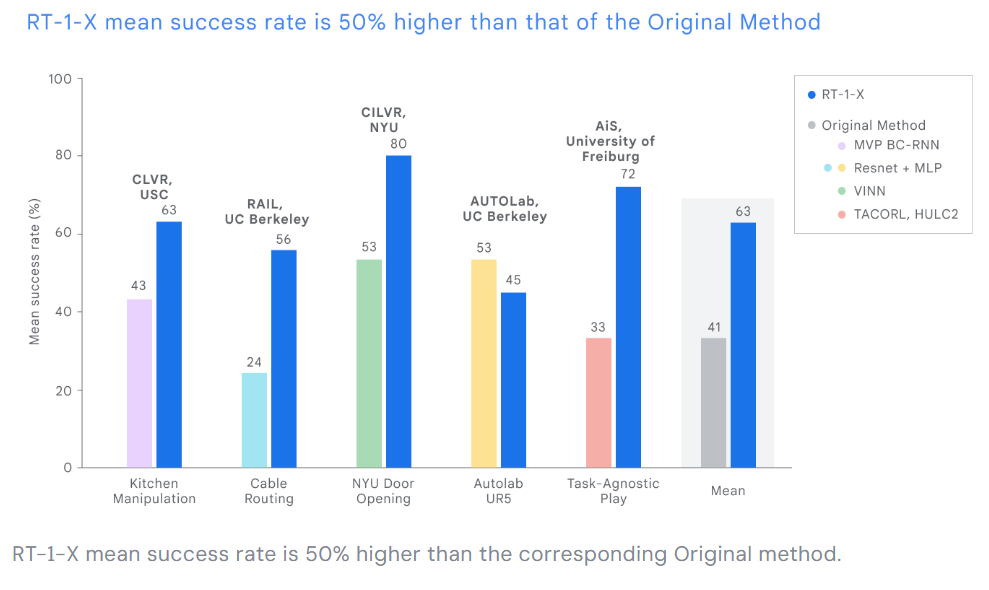
Un ensemble de données pour l’entraînement de robots polyvalents
L’ensemble de données Open X Embodiment a été développé en collaboration avec des laboratoires de recherche universitaires de plus de 20 institutions. Il regroupe les données de 22 robots représentant plus de 500 capacités et 150 000 tâches dans plus d’un million de flux de travail.
Selon Deepmind, cet ensemble de données constitue un outil important pour la formation d’un modèle généraliste capable de contrôler de nombreux types de robots, d’interpréter différentes instructions, de faire des déductions de base sur des tâches complexes et de généraliser efficacement.
Capacités émergentes du modèle de robot
La version RT-2 du modèle d’action du langage visuel RT-2-X, présentée cet été, a triplé ses capacités en tant que robot potentiel du monde réel après avoir été entraînée avec l’ensemble de données Open-X. Les expériences ont montré que le co-entraînement avec des données provenant d’autres plateformes a donné au RT-2-X des capacités supplémentaires qui n’étaient pas présentes dans l’ensemble de données RT-2 original.
Le modèle RT-2 utilise de grands modèles de langage pour le raisonnement et comme base de ses actions. Par exemple, il peut expliquer pourquoi une pierre est un meilleur marteau improvisé qu’un morceau de papier, et appliquer cette capacité à différents scénarios d’application.
Après une formation sur l’ensemble de données X, il a été en mesure d’améliorer ces compétences. Par exemple, RT-2-X a montré une meilleure compréhension des relations spatiales entre les objets, étant capable de distinguer des gradations fines telles que « mettez la pomme sur le tissu » ou « mettez la pomme près du tissu ».
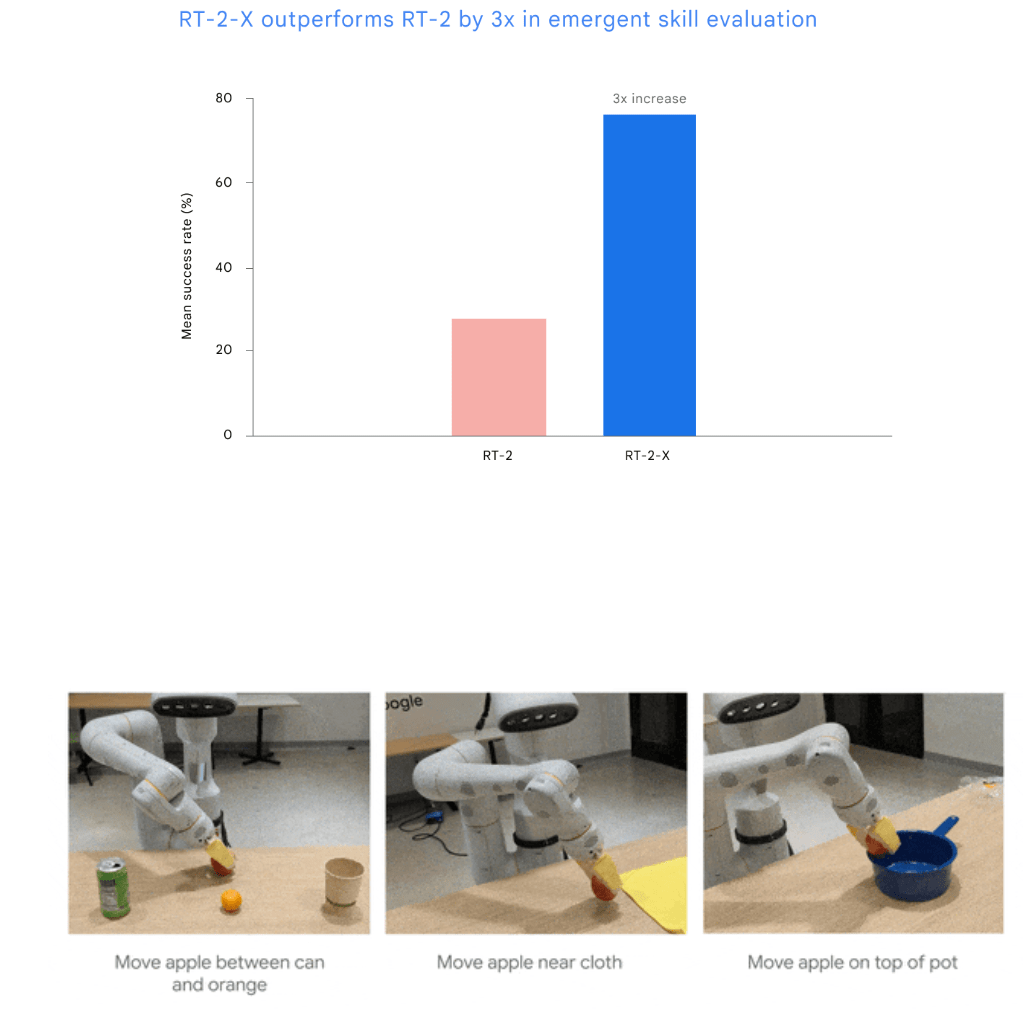
Le RT-2-X montre que l’entraînement avec des données provenant d’autres robots peut également améliorer des robots déjà capables qui ont été entraînés avec un grand nombre de données, écrit Deepmind.
La conclusion de l’équipe de recherche est similaire : l’augmentation des capacités des robots à l’aide de données provenant de différents types de robots fonctionne, affirment-ils, et produit des « améliorations spectaculaires des performances ». Les recherches futures pourraient analyser comment les modèles de robots peuvent mieux tirer parti de l’expérience pour s’améliorer.
