
DeepFloyd IF est un modèle texte-image qui gère particulièrement bien le texte et qui est essentiellement une version open source d’Imagen de Google.
En mai 2022, Google a fait la démonstration d’Imagen, un modèle texte-image qui a surpassé DALL-E 2 d’OpenAI, qui venait juste d’être publié à l’époque. Selon l’équipe et les exemples présentés, le modèle a surpassé DALL-E en termes de précision et de qualité de la synthèse texte-image. Il a également été capable de générer du texte dans des images, une capacité qu’aucun modèle open source n’a été en mesure de réaliser de manière fiable.
Comme pour les autres modèles d’IA générateurs, tels que Stable Diffusion ou DALL-E 2, l’équipe de Google s’est appuyée sur un encodeur de texte figé qui convertit les invites textuelles en embeddings, lesquels sont ensuite décodés dans une image par un modèle de diffusion. Toutefois, contrairement à d’autres modèles, Imagen n’utilise pas le modèle CLIPE à entraînement multimodal, mais plutôt le grand modèle de langage T5-XXL. L’équipe a même pu montrer que la qualité des images générées augmente davantage avec la taille du modèle de langage qu’avec l’entraînement du modèle de diffusion, qui est en fait responsable de la synthèse d’images.
DeepFloyd IF est un logiciel libre Imagen
Aujourd’hui, l’équipe DeepFloyd, affiliée à StabilityAI, a reproduit cette architecture et publié une sorte d’image open source appelée IF. Selon l’équipe, IF démontre la haute qualité d’image et les capacités de compréhension du langage d’Imagen. Il a été entraîné sur environ 1,2 milliard d’images provenant de l’ensemble de données LAION-5B.
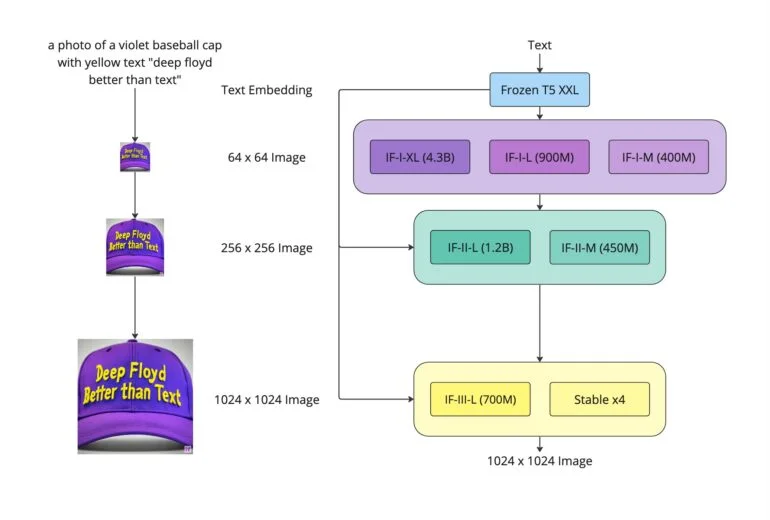
Lors des tests, il a même surpassé Google Imagen, obtenant un score FID Zero-Shot de 6,66 sur l’ensemble de données COCO, devançant également d’autres modèles disponibles tels que Stable Diffusion.




Selon l’équipe, IF prend également en charge la traduction d’image à image et la peinture.
Comme Imagen, DeepFloyd IF dispose de deux modèles de super-résolution qui augmentent la résolution des images à 1 024 x 1 024 pixels et offre différentes tailles de modèles avec jusqu’à 4,3 milliards de paramètres. Pour le plus grand modèle avec un upscaler de 1 024 pixels, l’équipe recommande 24 gigaoctets de VRAM, tandis que le plus grand modèle avec un upscaler de 256 pixels nécessite encore 16 gigaoctets de VRAM.
DeepFloyd présente le prochain niveau de synthèse texte-image
Selon DeepFloyd, ce travail montre le potentiel des grandes architectures UNet dans la première étape des modèles de diffusion en cascade et donc un avenir prometteur pour la synthèse texte-image. En d’autres termes, le modèle IF de DeepFloyd montre clairement que l’IA générative peut encore s’améliorer et que la communauté open source pourrait à l’avenir réaliser des modèles tels que Parti de Google, qui surpasse Imagen à certains égards.
La première version du modèle IF est soumise à une licence restreinte, destinée uniquement à des fins de recherche – en d’autres termes, à des fins non commerciales – pour collecter temporairement des informations en retour. Une fois ce retour d’information recueilli, l’équipe de DeepFloyd et StabilityAI publiera gratuitement une version commercialement compatible.
DeepFloyd’s IF a un Github, une démo est disponible sur HuggingFace. Plus d’informations sont disponibles sur le site de DeepFloyd.
