
Certains voient l’ingénierie des instructions comme un domaine d’avenir dans le domaine professionnel, tandis que d’autres la considèrent comme une mode passagère. La recherche en IA de Microsoft décrit son approche.
Dans un récent article, les chercheurs de Microsoft décrivent leur processus d’ingénierie des instructions pour le Dynamics 365 Copilot et le Copilot sur Power Platform, deux mises en œuvre de modèles de chat développés par OpenAI.
L’ingénierie des instructions repose sur un processus d’essais et erreurs
Entre autres choses, l’équipe de recherche de Microsoft utilise des instructions générales pour leurs chatbots, ce que nous tapons généralement dans ChatGPT et des applications similaires lors de l’assignation d’un rôle spécifique, d’un ensemble de connaissances et de comportements au chatbot.
L’instruction est le « mécanisme principal » pour interagir avec un modèle de langage et est un outil « extrêmement efficace », écrit l’équipe de recherche. Elle doit être « précise et exacte » sinon le modèle ne fera que deviner.

La Microsoft recommande d’établir quelques règles de base pour les instructions appropriées au chatbot.
Pour Microsoft, ces règles de base comprennent l’évitement d’opinions subjectives ou de répétitions, de discussions ou d’aperçus excessifs sur la manière de procéder avec l’utilisateur et de mettre fin à une conversation devenue controversée. Les règles de base peuvent également éviter que le chatbot soit vague, s’écarte du sujet ou insère des images dans la réponse.
System message:
You are a customer service agent who helps users answer questions based on documents from## On Safety:
– e.g. be polite
– e.g. output in JSON format
– e.g. do not respond to if request contains harmful content…## Important
– e.g. do not greet the customer
–AI Assistant message:
## Conversation
User message:
AI Assistant message:
Microsoft sample prompt
Cependant, l’équipe de recherche reconnaît que la création de telles instructions nécessite une certaine quantité d' »art », ce qui implique qu’il s’agit principalement d’un acte créatif. Ils affirment que les compétences nécessaires ne sont pas « extrêmement difficiles à acquérir ».
Lors de la création d’instructions, ils suggèrent de créer un cadre dans lequel il est possible d’expérimenter des idées, puis de les affiner. « La génération d’instructions peut s’apprendre par la pratique », écrit l’équipe.
Le rôle futur de l’ingénierie des instructions n’est pas encore clair car, d’une part, il est vrai que la sortie des modèles dépend fortement de l’instruction. D’autre part, la nature aléatoire des générateurs de texte rend difficile l’étude de l’efficacité des méthodes d’instruction individuelles, voire d’éléments individuels dans les instructions, de manière à respecter les normes scientifiques.
Par exemple, il est au moins discutable de savoir si des « méga-instructions » étendues produisent de meilleurs résultats que des instructions concises de trois phrases. De telles affirmations sont difficiles à évaluer et profitent principalement à certains modèles économiques.
À terme, l’ingénierie des instructions pourrait évoluer d’une sorte de pseudo-langage de programmation vers un processus créatif dans la gestion des flux de travail – quels processus de travail peuvent être capturés par les LLMs (Large Language Models) et avec quelle fiabilité ?
Le modèle de langage pourrait ensuite générer les instructions exactes via des requêtes, des tests de fine-tuning et des exemples. Les travailleurs humains devraient principalement connaître les capacités des systèmes et définir et établir de nouvelles formes de travail.
Utilisation de données contextuelles pour obtenir de meilleures réponses de l’IA
L’approche de Microsoft en matière d’ingénierie des instructions va au-delà de l’utilisation traditionnelle d’instructions standard et inclut des techniques avancées telles que la génération avec augmentation de récupération (RAG) et la segmentation de la base de connaissances.
RAG est un outil puissant que Microsoft utilise pour traiter des données diverses et en grande quantité, en assemblant de petits morceaux de données pertinents, ou « chunks », pour des problèmes spécifiques des clients.
Ces chunks sont ensuite comparés à des données historiques et aux retours des agents pour générer la meilleure réponse possible à la requête du client. En même temps, la segmentation de la base de connaissances simplifie de grands blocs de données en créant des représentations des documents.
Ces représentations sont ensuite comparées à l’entrée de l’utilisateur pour incorporer les représentations les mieux notées dans le modèle d’instruction GPT pour la génération de la réponse. En combinant ces techniques, on obtient des réponses informées, pertinentes et personnalisées aux questions des clients.
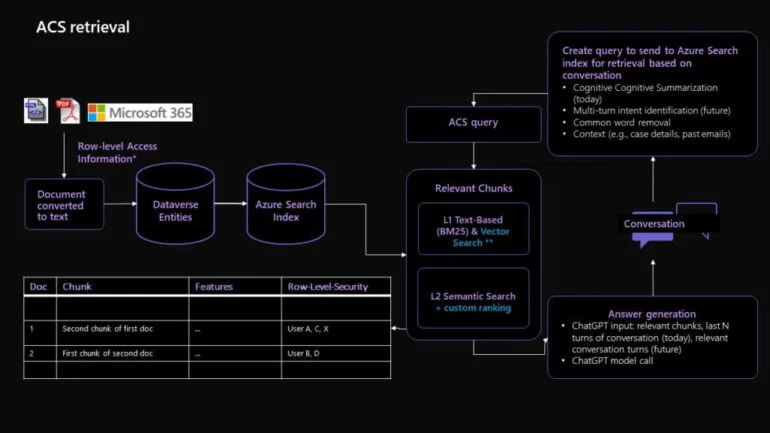
Une explication technique détaillée est disponible sur le Blog de recherche de Microsoft.
