
Investigadores de Microsoft demuestran LLaVA-Med, un asistente de IA multimodal para biomedicina capaz de procesar imágenes y texto.
Se utilizó un gran conjunto de datos de pares de imágenes y texto biomédico para entrenar el modelo de IA multimodal. El conjunto de datos incluye radiografías de tórax, resonancias magnéticas, histología, patología y imágenes de tomografía computarizada, entre otras. En primer lugar, el modelo aprende a describir el contenido de estas imágenes y, por ende, los conceptos biomédicos importantes. Luego, LLaVA-Med (Large Language and Vision Assistant for BioMedicine) se entrena con un conjunto de datos de instrucciones generadas por GPT-4.
Este conjunto de datos es creado por GPT-4 basado en textos biomédicos que contienen toda la información sobre cada imagen, y se puede utilizar para generar pares de preguntas y respuestas sobre las imágenes. En la etapa de ajuste fino, LLaVA-Med se entrena en las imágenes y los ejemplos correspondientes de GPT-4.
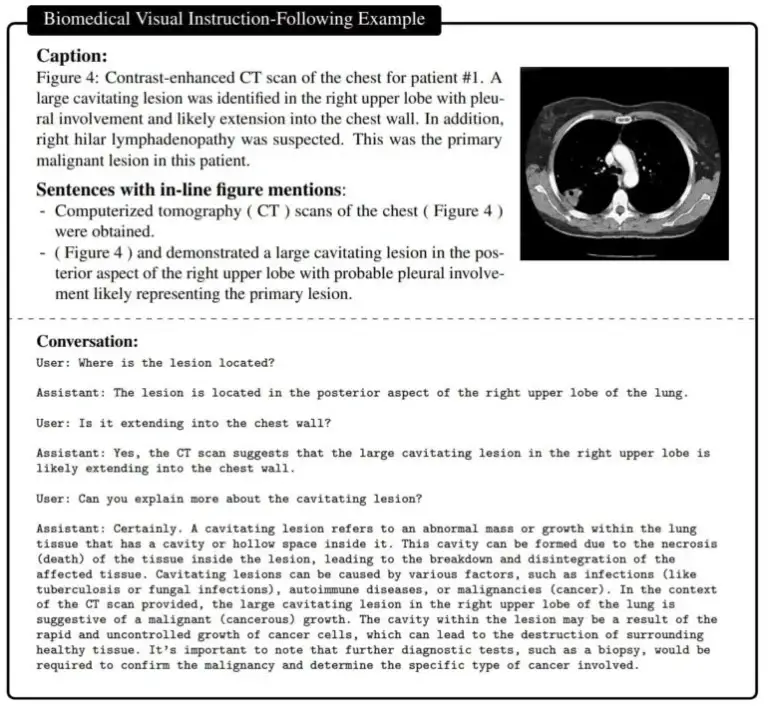
El resultado es un asistente capaz de responder preguntas sobre una imagen biomédica en lenguaje natural.
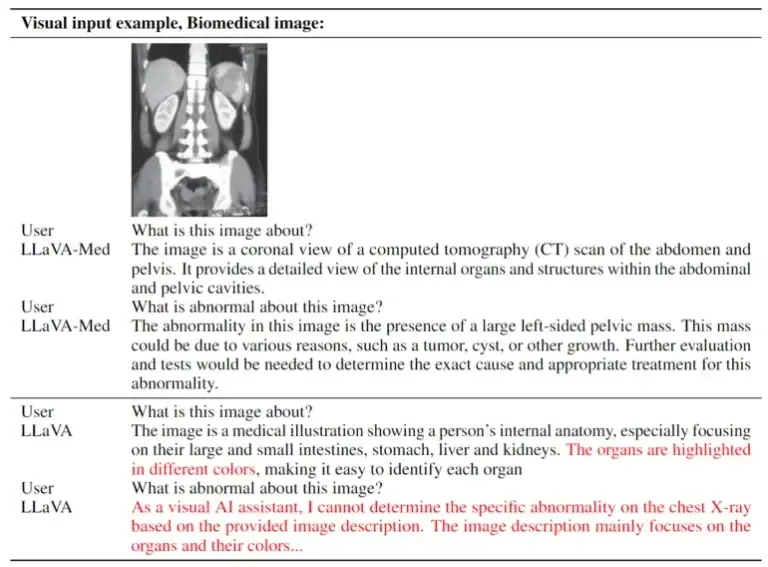
LLaVA-Med en comparación con LLaVA. Ambos son multimodales, pero el primero se especializa en biomedicina y, por lo tanto, proporciona respuestas más precisas. | Imagen: Microsoft
LLaVA-Med fue entrenado en 15 horas
El método de entrenamiento utilizado permitió entrenar a LLaVA-Med en ocho GPU Nvidia A100 en menos de 15 horas. Está basado en un Vision Transformer y en el modelo de lenguaje Vicuna, que a su vez se basa en LLaMA de Meta. Según el equipo, el modelo tiene una «excelente capacidad de conversación multimodal». En tres conjuntos de datos biomédicos estándar para responder preguntas visuales, LLaVA-Med superó a modelos anteriores de última generación en algunas métricas.
Asistentes multimodales como LLaVA-Med podrían utilizarse en diversas aplicaciones biomédicas en el futuro, como investigación médica, interpretación de imágenes biomédicas complejas y soporte de conversación en el campo de la salud.
Sin embargo, la calidad aún no es suficientemente buena: «Aunque creemos que LLaVA-Med representa un paso significativo para la construcción de un asistente visual biomédico útil, observamos que LLaVA-Med está limitado por alucinaciones y un razonamiento profundo débil común a muchos LMMs», dice el equipo. Los trabajos futuros se centrarán en mejorar la calidad y la confiabilidad.
Más información está disponible en GitHub.
