
Como parte del proyecto Massively Multilingual Speech, Meta está lanzando modelos de IA capaces de convertir el lenguaje hablado en texto y texto en habla en 1.100 idiomas.
El nuevo conjunto de modelos se basa en wav2vec de Meta, así como en un conjunto de datos seleccionados de ejemplos para 1.100 idiomas y otro conjunto de datos no seleccionados para casi 4.000 idiomas, incluyendo idiomas hablados por solo unas pocas cientos de personas, para los cuales aún no existe tecnología de habla, según Meta.
El modelo puede expresarse en más de 1.000 idiomas e identificar más de 4.000 idiomas. Según Meta, MMS supera a los modelos anteriores al cubrir diez veces más idiomas. Puede obtener una visión general de todos los idiomas disponibles aquí.
El Nuevo Testamento encuentra un nuevo uso como conjunto de datos para IA
Un componente clave de MMS es la Biblia, específicamente el Nuevo Testamento. El conjunto de datos de Meta contiene lecturas del Nuevo Testamento en más de 1.107 idiomas, con una duración promedio de 32 horas.
Meta utilizó estas grabaciones en combinación con extractos correspondientes de internet. Además, se utilizaron otros 3.809 archivos de audio sin etiquetar, también con lecturas del Nuevo Testamento pero sin información adicional sobre el idioma.
Dado que 32 horas por idioma no son suficientes para entrenar un sistema confiable de reconocimiento de voz, Meta utilizó wave2vec 2.0 para preentrenar los modelos MMS con más de 500.000 horas de habla en más de 1.400 idiomas. Posteriormente, se ajustaron estos modelos para comprender e identificar numerosos idiomas.
Las pruebas de referencia muestran que el rendimiento del modelo se mantuvo prácticamente constante, incluso con el entrenamiento en un mayor número de idiomas diferentes. De hecho, la tasa de error disminuyó ligeramente en un 0,4% con el aumento del entrenamiento.
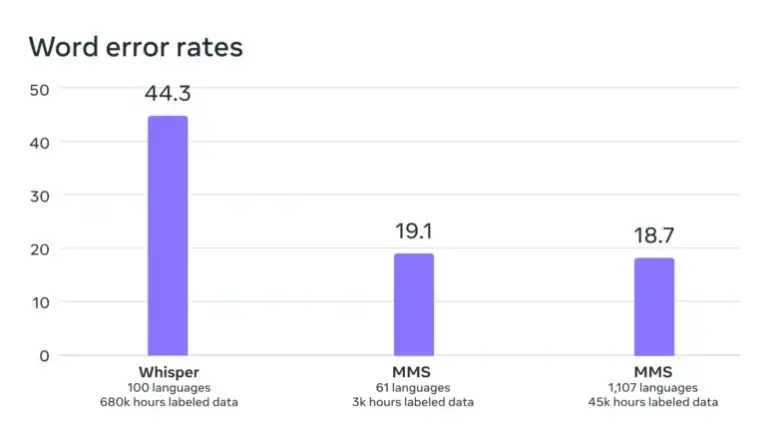
Según Meta, la tasa de error de su modelo es significativamente menor que la de Whisper de OpenAI, que no fue optimizado explícitamente para un amplio multilingüismo. Una comparación solo en inglés sería más interesante. Los primeros probadores en Twitter informan que Whisper tiene un mejor rendimiento en este aspecto.
MMS: Massively Multilingual Speech.
— Yann LeCun (@ylecun) May 22, 2023
– Can do speech2text and text speech in 1100 languages.
– Can recognize 4000 spoken languages.
– Code and models available under the CC-BY-NC 4.0 license.
– half the word error rate of Whisper.
Code+Models: https://t.co/zQ9lWms5TQ
Paper:…
Según Meta, el hecho de que las voces en el conjunto de datos sean predominantemente masculinas no afecta negativamente la comprensión o generación de voces femeninas.
Además, el modelo no tiende a generar discursos excesivamente religiosos. Meta atribuye esto al enfoque de clasificación utilizado (Clasificación Temporal Connectionista), que se centra más en los patrones y secuencias de habla que en el contenido y significado de las palabras.
Sin embargo, Meta advierte que el modelo a veces transcribe palabras o frases de manera incorrecta, lo que puede llevar a declaraciones incorrectas u ofensivas.
Un modelo para miles de idiomas El objetivo a largo plazo de Meta es desarrollar un solo modelo de lenguaje para la mayor cantidad posible de idiomas, con el fin de preservar idiomas en peligro de extinción. Los modelos futuros podrían admitir aún más idiomas e incluso dialectos.
«Nuestro objetivo es facilitar el acceso de las personas a la información y permitirles usar dispositivos en su idioma preferido», escribe Meta. Escenarios de aplicación específicos incluyen tecnologías de realidad virtual y aumentada, o mensajes.
En el futuro, un solo modelo podría ser entrenado para todas las tareas, como reconocimiento de voz, síntesis de voz e identificación de voz, lo que llevaría a un rendimiento general aún mejor, escribe Meta.
El código y los modelos pre-entrenados de MMS con 300 millones y mil millones de parámetros, respectivamente, junto con las derivaciones refinadas para reconocimiento e identificación de voz, así como la síntesis de texto a voz, están disponibles como modelos de código abierto por Meta en GitHub.
