
Con LIMA, los investigadores de IA de Meta presentan un nuevo modelo de lenguaje que alcanza un rendimiento equivalente al GPT-4 y al Bard en escenarios de prueba, aunque se ajusta con relativamente pocos ejemplos.
LIMA significa «Menos es Más para el Alineamiento» y el nombre sugiere la función del modelo: demostrar que con un modelo de IA preentrenado de manera exhaustiva, pocos ejemplos son suficientes para obtener resultados de alta calidad.
«Pocos ejemplos» en este caso significa que Meta seleccionó manualmente 1.000 desencadenantes diversos y sus salidas de fuentes como otros artículos de investigación, WikiHow, StackExchange y Reddit.
El equipo luego utilizó estos ejemplos para mejorar su propio modelo LLaMA, con 65 mil millones de parámetros, que se filtró anteriormente y impulsó el movimiento de modelos de lenguaje de código abierto. Meta evitó el costoso RLHF, que OpenAI utiliza para ajustar sus modelos y considera una parte importante del futuro de la IA.
Estilo sobre sustancia
La Meta hizo que seres humanos compararan los resultados de LIMA y otros modelos, incluyendo GPT-4, text-davinci-003 y Google Bard. Según Meta, los evaluadores humanos prefirieron las respuestas de LIMA en un 43% de los casos en comparación con GPT-4, en 200 ejemplos. LIMA superó a Google Bard en un 58% de los casos y a text-davinci-003 en un 65% de los casos. Todos estos modelos, excepto LIMA, fueron refinados con retroalimentación humana.
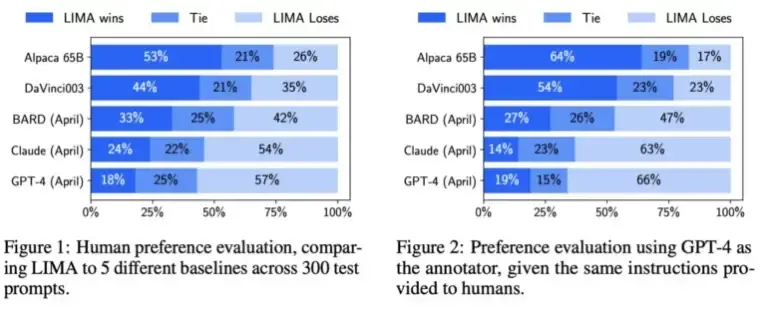
El equipo de investigación de Meta sugiere que estos resultados indican que un modelo de lenguaje adquiere gran parte de su conocimiento a través del preentrenamiento y que un ajuste fino relativamente limitado con algunos ejemplos es suficiente para enseñar a los modelos a generar contenido de alta calidad.
Como resultado, el entrenamiento extensivo con retroalimentación humana utilizado por OpenAI puede no ser tan importante como se pensaba anteriormente. Este es un punto que Meta destaca claramente en su artículo de investigación.
La «Hipótesis de Alineamiento Superficial»
La Meta define este descubrimiento como la «Hipótesis de Alineamiento Superficial». Sugiere que la fase de alineamiento después del preentrenamiento se trata principalmente de enseñar al modelo un estilo o formato específico que puede recordar al interactuar con los usuarios.
Así, el ajuste fino está más relacionado con el estilo que con la sustancia. Esto contrasta con la práctica común de procesos de ajuste fino especialmente extensos y complejos, como RLHF de OpenAI.
El equipo de investigación de Meta identifica dos limitaciones de LIMA: en primer lugar, construir conjuntos de datos con ejemplos de alta calidad es un enfoque desafiante que es difícil de escalar. En segundo lugar, LIMA no es tan robusto como los modelos que ya están disponibles como productos, como GPT-4.
Según el equipo, LIMA genera principalmente respuestas buenas, pero un «prompt adversarial» o una «muestra desafortunada» pueden resultar en respuestas débiles. Aun así, LIMA muestra que el problema complejo de alinear y ajustar un modelo de IA puede resolverse con un enfoque simple, según el equipo de Meta.
Yann LeCun, jefe de investigación en IA de Meta, adopta una visión pragmática de esta relativa devaluación del esfuerzo detrás de GPT-4 y modelos similares: ve a los grandes modelos de lenguaje como un elemento del futuro cercano que no jugará un papel a corto plazo, al menos «sin cambios significativos».
