
BLIVA es un modelo de lenguaje visual que destaca en la lectura de texto en imágenes, lo que lo hace útil en escenarios y aplicaciones del mundo real en diversas industrias.
Investigadores de la Universidad de California en San Diego han desarrollado BLIVA, un modelo de lenguaje visual diseñado para manejar mejor las imágenes que contienen texto. Los modelos de lenguaje visual (VLM) amplían los grandes modelos de lenguaje (LLM) incorporando capacidades de comprensión visual para responder a preguntas sobre imágenes.
Estos modelos multimodales han logrado avances impresionantes en la evaluación comparativa de preguntas y respuestas visuales abiertas. Un ejemplo es el GPT-4 de OpenAI, que en su forma multimodal puede discutir el contenido de una imagen cuando se lo pide un usuario, aunque esta capacidad sólo está disponible actualmente en la aplicación «Be My Eyes».
Sin embargo, una de las principales limitaciones de los sistemas actuales es la capacidad de tratar con imágenes que contienen texto, algo habitual en los escenarios del mundo real.
BLIVA combina InstructBLIP y LLaVA
Para resolver este problema, el equipo desarrolló BLIVA, que significa «BLIP con asistente visual». BLIVA incorpora dos tipos complementarios de incrustaciones visuales, a saber, incrustaciones de consulta aprendidas extraídas por un módulo Q-former para centrarse en regiones de la imagen relevantes para la entrada textual, similar a InstructBLIP de Salesforce, e incrustaciones de parches codificados extraídas directamente de los parches de píxeles sin procesar de la imagen completa, inspiradas en LLaVA (Large Scale Language and Vision Assistant) de Microsoft.
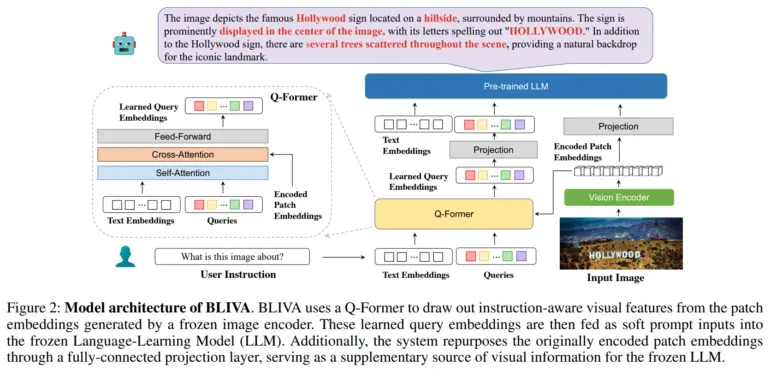
Según los investigadores, este doble enfoque permite a BLIVA utilizar tanto incrustaciones refinadas basadas en consultas adaptadas al texto como incrustaciones de parches más ricas que captan más detalles visuales.
BLIVA está preentrenado con aproximadamente 550.000 pares de imágenes y pies de foto, y se ha ajustado con 150.000 ejemplos de preguntas y respuestas visuales, manteniendo congelados el codificador visual y el modelo lingüístico.
El equipo demostró que BLIVA mejora notablemente el procesamiento de imágenes ricas en texto en conjuntos de datos como OCR-VQA, TextVQA y ST-VQA. Por ejemplo, alcanzó una precisión del 65,38% en OCR-VQA, frente al 47,62% de InstructBLIP. El nuevo sistema también superó a InstructBLIP en siete de las ocho pruebas comparativas generales de preguntas y respuestas visuales no textuales. El equipo cree que esto demuestra las ventajas de los enfoques de incrustación múltiple para la comprensión visual en general.

Los investigadores también evaluaron BLIVA con un nuevo conjunto de datos de miniaturas de vídeos de YouTube con preguntas asociadas, disponible en Hugging Face. BLIVA alcanzó una precisión del 92%, significativamente superior a la de los métodos anteriores. Según el equipo, la capacidad de BLIVA para leer texto en imágenes, como señales de tráfico o envases de alimentos, podría permitir aplicaciones prácticas en diversos sectores. Recientemente, investigadores de Microsoft demostraron un asistente multimodal de IA para biomedicina basado en LLaVA, denominado LLaVA-med.
Más información y el código están disponibles en el Github de BLIVA, y una demostración en Hugging Face.
