
El Instituto Allen para la Inteligencia Artificial (AI2) presentó Dolma, un conjunto de datos de código abierto con tres billones de tokens, provenientes de una amplia variedad de contenido web, publicaciones científicas, código y libros. Es el conjunto de datos de código abierto más extenso de este tipo disponible públicamente hasta el momento.
Dolma es la base del Modelo de Lenguaje Abierto (OLMo), que está siendo desarrollado actualmente en AI2 y tiene programado su lanzamiento a principios de 2024. Con el objetivo de desarrollar el «mejor modelo de lenguaje abierto», se creó el extenso conjunto de datos Dolma (Datos para alimentar el OLMo).
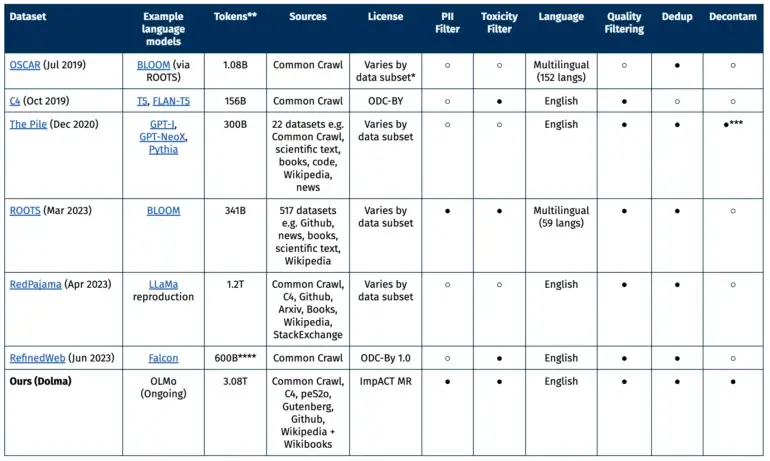
Dolma es actualmente el conjunto de datos de código abierto más grande y está disponible para desarrolladores e investigadores a través de la plataforma Hugging Face. Allí también encontrarás las herramientas que los investigadores utilizaron para crearlo, garantizando la reproducibilidad de los resultados.
Dolma consiste principalmente en datos en inglés
Para crear Dolma, se convirtieron datos de varias fuentes en documentos de texto limpios.
En la primera versión, Dolma está principalmente limitado a textos en inglés. Se utilizó un modelo de reconocimiento de idioma para filtrar los datos. Para compensar cualquier sesgo hacia dialectos minoritarios, el equipo incluyó todos los textos que el modelo clasificó como inglés con un 50 por ciento de confianza. En futuras versiones se incluirán otros idiomas.

En etapas posteriores, los investigadores limpiaron el conjunto de datos eliminando duplicados, contenido de baja calidad o información sensible, además de mejorar la calidad de los ejemplos de código.
Comparación con otros conjuntos de datos abiertos
Gran parte de los datos proviene del proyecto sin fines de lucro Common Crawl, que se centra en datos web. Además, hay otras páginas web de la colección C4, textos académicos de peS20, fragmentos de código de The Stack, libros de Project Gutenberg y la Wikipedia en inglés.
El conjunto de datos ideal, según la AI21, debe cumplir varios criterios: apertura, representatividad, tamaño y reproducibilidad. También debe minimizar los riesgos, especialmente aquellos que podrían afectar a indivíduos.
Estudios anteriores han demostrado que no solo el número de parámetros en el modelo, sino también la cantidad de material de entrenamiento en un modelo de lenguaje juega un papel central en el rendimiento.
Disponibilidad de Dolma y la cuestión del código abierto
El conjunto de datos se lanza bajo la licencia ImpACT de AI2 como un artefacto de riesgo medio. Los investigadores deben cumplir ciertos requisitos, como proporcionar su información de contacto y aceptar el uso previsto de Dolma. Además, se ha establecido un mecanismo para permitir la eliminación de datos personales bajo solicitud.
Después del lanzamiento de Dolma como un conjunto de datos de código abierto, algunos críticos argumentaron que había muchas cláusulas en la licencia. En su opinión, Dolma es abierto, pero no podría ser considerado como de código abierto. La designación de Meta del modelo LLaMA-2 como código abierto también ha sido recientemente criticada por la Iniciativa de Código Abierto.
